[py]pandas数据统计学习
pandas.core.base.DataError: No numeric types to aggregate错误规避
我没有去解决这个问题, 而用填充0规避了这个问题
统计 聚合
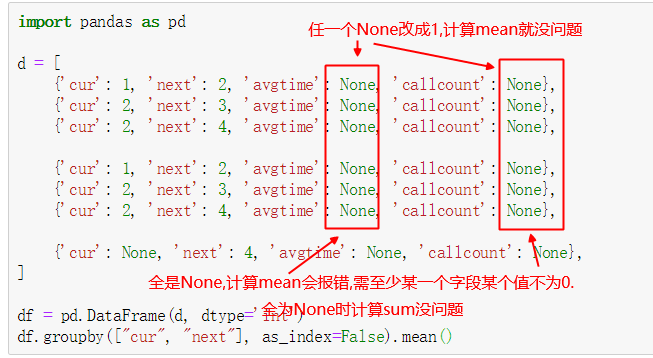
d = [
{'cur': 1, 'next': 2, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 3, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 4, 'avgtime': None, 'callcount': None},
{'cur': 1, 'next': 2, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 3, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 4, 'avgtime': None, 'callcount': None},
{'cur': None, 'next': 4, 'avgtime': None, 'callcount': None},
]
df = pd.DataFrame(d, dtype='int')
df.groupby(["cur", "next"], as_index=False).mean()重要总结:
1. None为NaN
2. count会统计空字符串, 但是cont不统计NaN. sum不统计NaN, 否则就会像sql里select(1+NULL)结果是NULL
3. 分组key为None时,记录不显示
计算mean()时DataError: No numeric types to aggregate
agg函数
使用这种聚合会卡到这个bug
pandas.core.base.DataError: No numeric types to aggregate错误规避
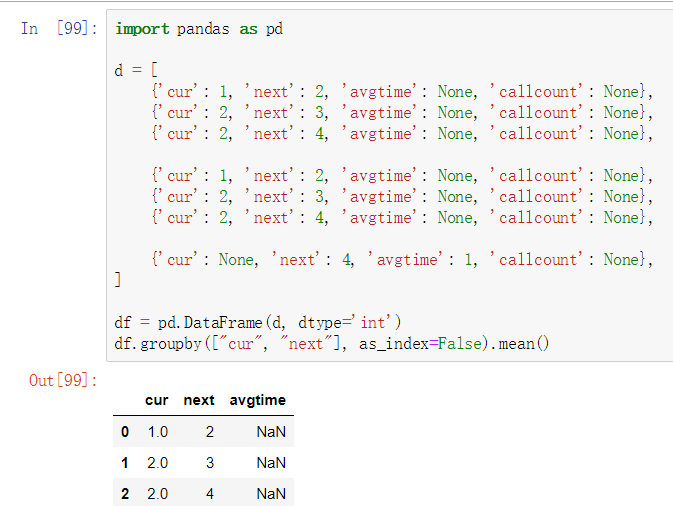
import pandas as pd
d = [
{'cur': 1, 'next': 2, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 3, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 4, 'avgtime': None, 'callcount': None},
{'cur': 1, 'next': 2, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 3, 'avgtime': None, 'callcount': None},
{'cur': 2, 'next': 4, 'avgtime': None, 'callcount': None},
{'cur': None, 'next': 4, 'avgtime': None, 'callcount': None},
]
df = pd.DataFrame(d, dtype='int')
g = df.groupby(["cur", "next"], as_index=False)
res = g.agg(
{
'avgtime': 'sum',
'callcount': 'mean',
}
)
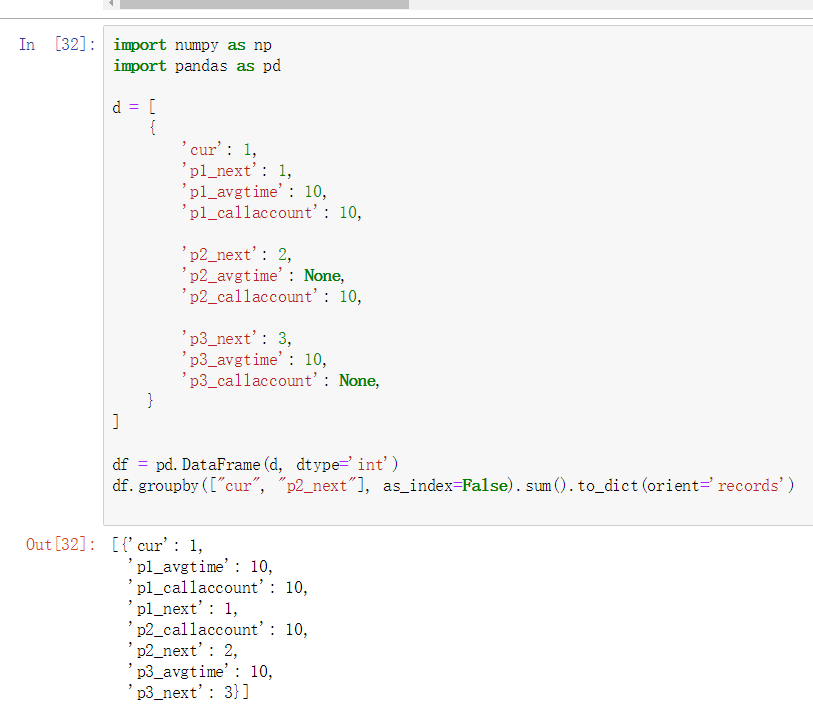
复杂的分组: cur分别与p1 p2 p3分组
import numpy as np
import pandas as pd
d = [
{
'cur': 1,
'p1_next': 1,
'p1_avgtime': 10,
'p1_callaccount': 10,
'p2_next': 2,
'p2_avgtime': None,
'p2_callaccount': 10,
'p3_next': 3,
'p3_avgtime': 10,
'p3_callaccount': None,
}
]
df = pd.DataFrame(d, dtype='int')
df.groupby(["cur", "p2_next"], as_index=False).sum().to_dict(orient='records')
[py]pandas数据统计学习的更多相关文章
- 转载,Pandas 数据统计用法
pandas模块为我们提供了非常多的描述性统计分析的指标函数,如总和.均值.最小值.最大值等,我们来具体看看这些函数: 1.随机生成三组数据import numpy as npimport panda ...
- pandas数据统计
1 count() 非空观测数量 2 sum() 所有值之和 3 mean() 所有值的平均值 4 median() 所有值的中位数 5 mode() 值的模值 6 std() 值的标准偏差 7 mi ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- pandas数据框,统计某列或者某行数据元素的个数
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/sinat_38893241/articl ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- 大数据学习day33----spark13-----1.两种方式管理偏移量并将偏移量写入redis 2. MySQL事务的测试 3.利用MySQL事务实现数据统计的ExactlyOnce(sql语句中出现相同key时如何进行累加(此处时出现相同的单词))4 将数据写入kafka
1.两种方式管理偏移量并将偏移量写入redis (1)第一种:rdd的形式 一般是使用这种直连的方式,但其缺点是没法调用一些更加高级的api,如窗口操作.如果想更加精确的控制偏移量,就使用这种方式 代 ...
- [译]针对科学数据处理的统计学习教程(scikit-learn教程2)
翻译:Tacey Wong 统计学习: 随着科学实验数据的迅速增长,机器学习成了一种越来越重要的技术.问题从构建一个预测函数将不同的观察数据联系起来,到将观测数据分类,或者从未标记数据中学习到一些结构 ...
- scikit-learning教程(二)统计学习科学数据处理的教程
统计学习:scikit学习中的设置和估计对象 数据集 Scikit学习处理来自以2D数组表示的一个或多个数据集的学习信息.它们可以被理解为多维观察的列表.我们说这些阵列的第一个轴是样本轴,而第二个轴是 ...
随机推荐
- Java基础之中间件的初识
java常用的中间件 一般本地开发的话建议使用tomcat.(小项目,或者是个人开发) linux系统建议使用jetty或apache hpptd 大型的项目或者商业项目就用JBOSS或webloig ...
- RGB与HSB之间转换
先来了解一些概念: 1.RGB是一种加色模型,就是将不同比例的Red/Green/Blue混合在一起得到新颜色.通常RGB颜色模型表示为: 2.HSB(HSV) 通过色相/饱和度/亮度三要素来表达颜色 ...
- linux(CentOS)磁盘挂载数据盘
linux(CentOS)磁盘挂载数据盘:第一步:查看是否存在需要挂载的磁盘: sudo fdisk -l 第二步:为需要挂载的磁盘创建分区: sudo fdisk /dev/vdb 执行中:依次选择 ...
- Numpy初步
1,获取矩阵行列数 Import numpyasnp #创建二维的naaray对象 a=np.array([[1,2,3,4,5],[6,7,8,9,10]]) print(a.shape) #返 ...
- XII Open Cup named after E.V. Pankratiev. GP of Eastern Europe (AMPPZ-2012)
A. Automat $m$超过$1600$是没用的. 从后往前考虑,设$f[i][j][k]$表示考虑$[i,n]$这些物品,一共花费$j$元钱,买了$k$个物品的最大收益. 时间复杂度$O(n^5 ...
- vue_VueRouter 路由_路由器管理n个路由_并向路由组件传递数据_新标签路由_编程式路由导航
路由:就是一个 key 与 value 的映射关系.key 就是 pathh 前台路由的 value 是 Component 组件对象 后台路由的 value 是一个 回调函数 普通链接: 会发送请求 ...
- 提高你的python:解释 yield 和 Generators(生成器)
转自:http://www.oschina.net/translate/improve-your-python-yield-and-generators-explained 原文:http://www ...
- 如何使用post请求下载文件
使用get请求下载文件非常简便,但是get请求的url有长度和大小的限制,所以当请求参数非常多时无法满足需求,所以改成post请求const res = await fetch('xxxxxxxxx' ...
- Java集合-treebag
import org.apache.commons.collections4.Bag; import org.apache.commons.collections4.bag.TreeBag; impo ...
- 壁虎书3 Classification
MNIST fetch_openml returns the unsorted MNIST dataset, whereas fetch_mldata() returned the dataset s ...