[python爬虫]Requests-BeautifulSoup-Re库方案--robots协议与Requests库实战
【根据北京理工大学嵩天老师“Python网络爬虫与信息提取”慕课课程编写
慕课链接:https://www.icourse163.org/learn/BIT-1001870001?tid=1002236011#/learn/announce】
一、网络爬虫引发的问题
爬虫依据获取数据的速度和能力,分为小型、中型和大型的爬虫。小型爬虫可以用python语言的Requests、BeautifulSoup库编写,适合获取页面内容;中型爬虫可以用Scrapy库编写,适合爬取网站或系列网站数据;大型爬虫指的是搜索引擎,像百度、Google等搜索引擎都有大型爬虫的支持,可以爬取全网络的信息,这种爬虫是定制开发的,没有第三方库支持。
网站搭建使用的Web服务器有一定的性能,如果爬虫大量地访问并获取服务器的资源数据,就会削弱服务器的性能。服务器是对用户提供数据资源服务的,它接受人类的浏览器访问。但是爬虫却可以凭借计算机的高速计算能力,大量地对服务器进行访问并获取数据,这对服务器来说是一种负担。此外,爬虫获取数据存在一定的法律风险和隐私泄露的风险。
大部分网站对爬虫有一定的限制,主要是通过两种方法。一是检查来访HTTP协议头的User-Agent字段,只响应浏览器或友好爬虫的访问请求。浏览器访问网站的HTTP头信息中会有User-Agent字段,用于标识浏览器的信息,如'User-Agent':'Mozilla/5.0'表示这是“Mozilla浏览器”。爬虫程序访问网站时,User-Agent字段通常都会标识程序的相关信息,而不会是浏览器的相关信息。如果访问请求的HTTP信息头中存在'User-Agent':'Mozilla/5.0',则网站认为这次访问是人使用浏览器进行的,而不会认为是爬虫行为。现在很多浏览器的User-Agent字段都有Mozilla的标识,这里面还有一段有趣的故事,请查看:https://zhidao.baidu.com/question/1767408752449075980.html。这种检测爬虫方式的缺点是,爬虫程序可以很容易地更改自己的User-Agent字段,从而骗取服务器,将自己的爬取行为伪装成浏览器的正常访问行为。第二种限制爬虫的方式是发布robots协议。它其实是一个txt文件,由各个网站的管理员发布。在这个robots.txt文件中说明了网站不允许哪些爬虫爬取哪些数据。
二、robots协议
robots(robots exclusion standard,网络爬虫排除标准),是一个txt文件,放在网站的根目录下。以简洁的语法告知爬虫程序和其编写者,在这个网站中,有哪些数据是不能爬取的。
如:https://www.cnblogs.com/robots.txt 博客园的robots协议
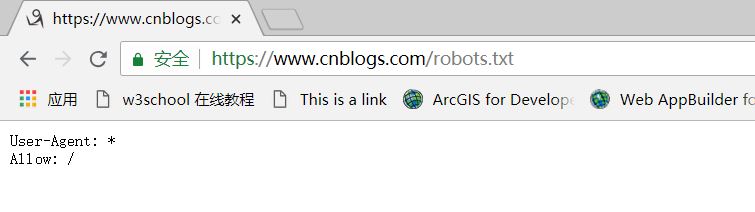
其中,User-Agent:*表示对所有的爬虫来说。Allow:/表示可以爬取根目录下的任何数据。也就是说,任何爬虫都可以爬取博客园的任何数据。
https://www.jd.com/robots.txt 京东的robots协议
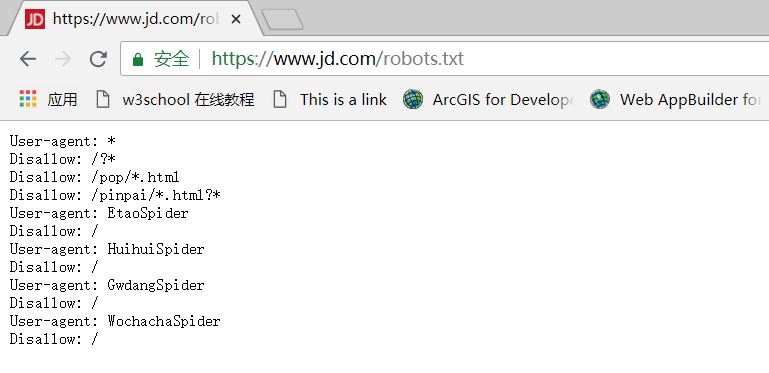
User-Agent:*,Disallow:/?*表示不允许任何爬虫爬取根目录下以问号(?)开头的任何数据,Disallow:/pop/*.html表示不允许爬取pop文件夹下所有的html文件,Disallow:/pinpai/*.html?*表示不允许爬取pinpai文件夹下任何后缀名开头是html?的文件。除了User-Agent:*之外,还对4个特定的爬虫进行了限制(EtaoSpider,HuihuiSpider,GwdangSpider,WochachaSpider)。在这4个爬虫下,都有Disallow:/表示不允许这4个爬虫爬取任何数据。
http://www.moe.edu.cn/robots.txt 中国教育部网站的robots协议(无robots协议)
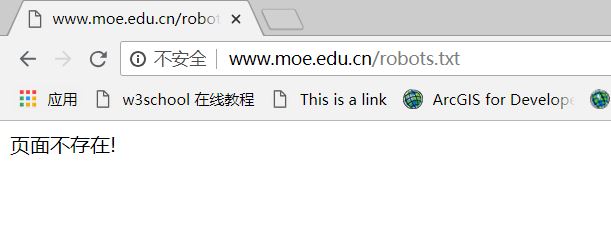
中国教育部的网站没有robots协议,表示对爬虫的爬取行为没有作规定。
robots协议是网站对爬虫和其编写者的声明,告知对于该网站哪些数据可以爬取,哪些则不可以。这个协议虽然不是约束性的,但如果违反有可能要承担法律责任,特别是爬取来的数据涉及隐私或重大机密,或用于商业盈利目的。对于编写爬虫的练习者来说,要在不影响、不危害网站服务器的前提下,遵守法律、道德,遵守网站相关规定,合理、有节制地使用爬虫程序。
三、Requests库编写爬虫实战
1.淘宝台灯商品页面爬取

上面的访问是正常的,也可以输出页面信息。但对于一些对请求访问有检查的网站来说,要更改请求HTTP信息头中的User-Agent字段,才可以成功连接至网站服务器。
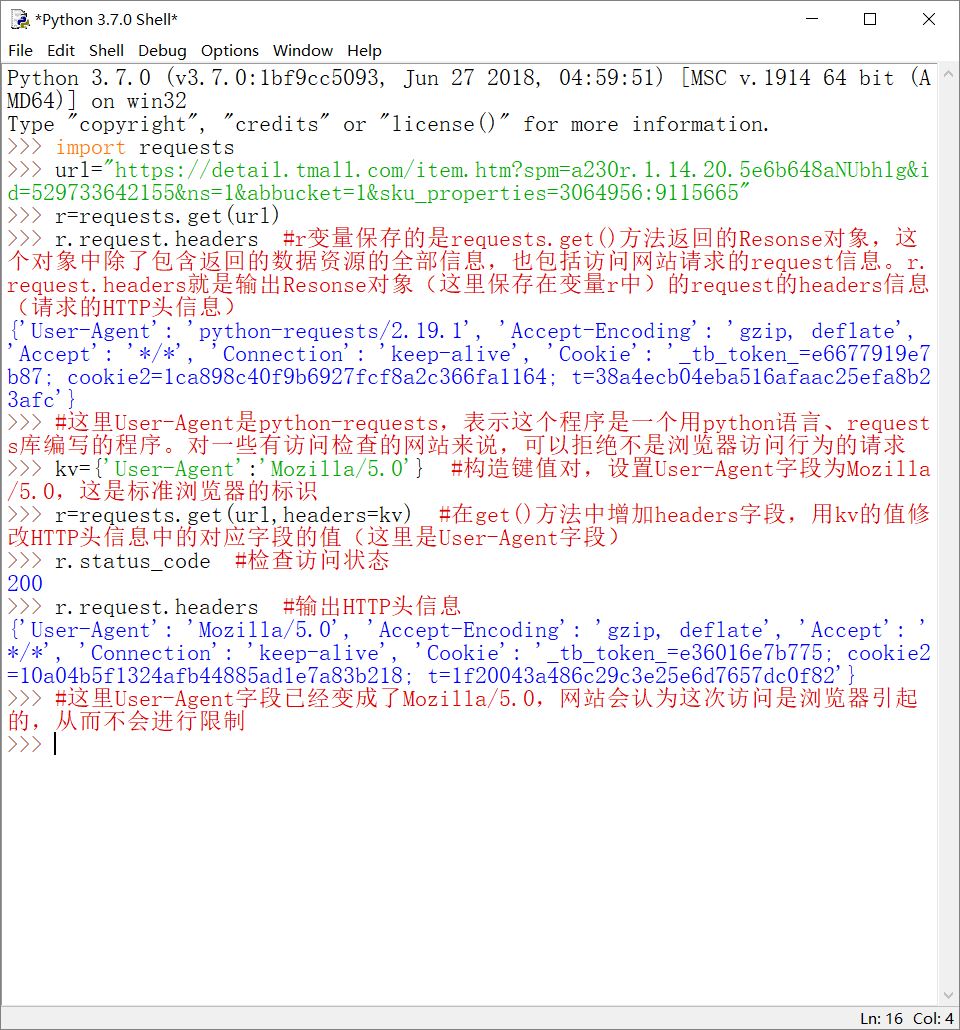
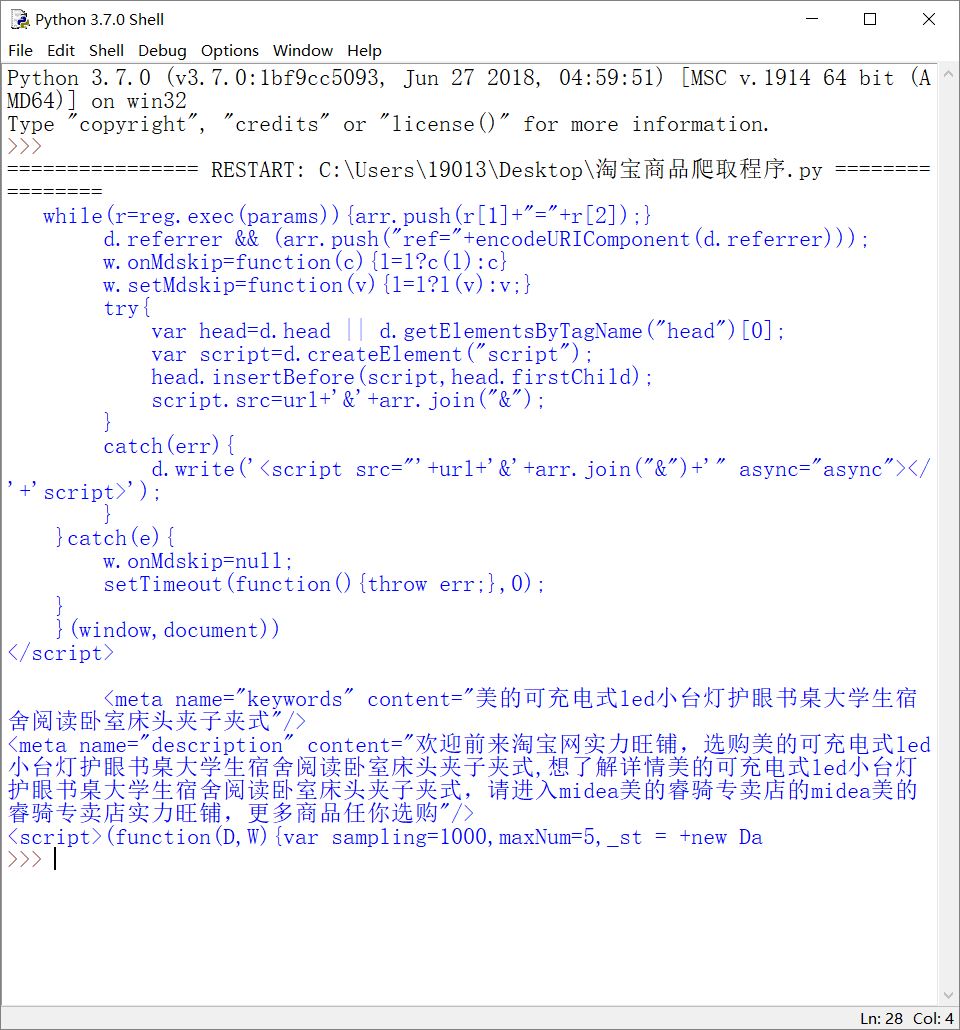
最终代码及运行结果如下:
#淘宝商品页面爬取程序
import requests def getHTMLText(url):
try:
kv={'User-Agent':'Mozilla/5.0'} #修改headers头信息,模拟浏览器访问行为
r=requests.get(url,headers=kv)
r.raise_for_status() #如果状态不是200,产生HTTPError异常
r.encoding=r.apparent_encoding
return r.text[1000:2000]
except:
return "" def main():
url="https://detail.tmall.com/item.htm?spm=a230r.1.14.20.5e6b648aNUbhlg&id=529733642155&ns=1&abbucket=1&sku_properties=3064956:9115665"
print(getHTMLText(url)) if __name__=="__main__":
main()
2.bing搜索关键词提交
在bing、百度等搜索引擎的搜索栏中输入要查询的内容,就会返回相应的信息。也可以直接在URL的地址中输入搜素关键字。根据这一点,可以在程序中提交搜索关键字,直接返回页面信息。
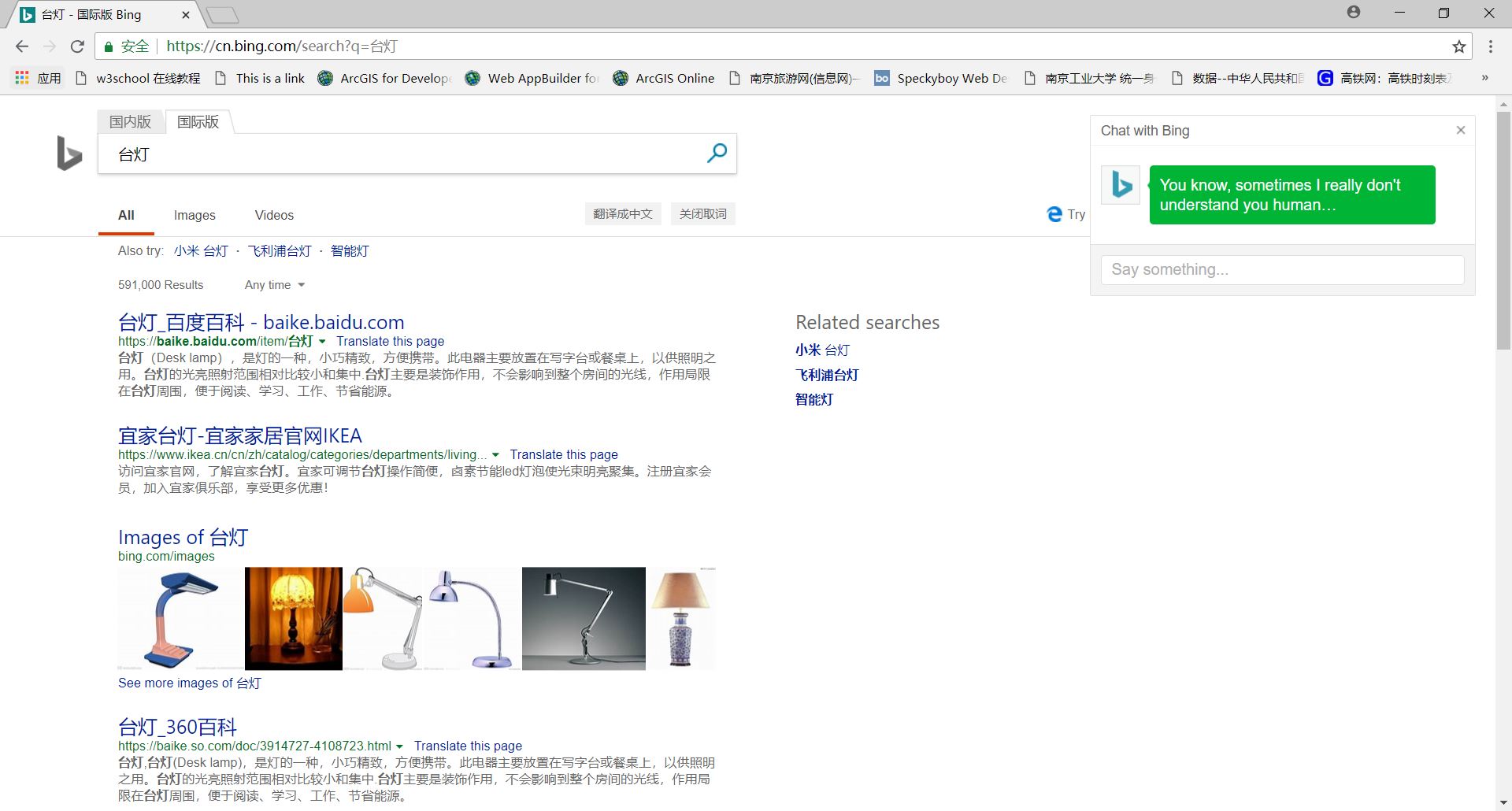
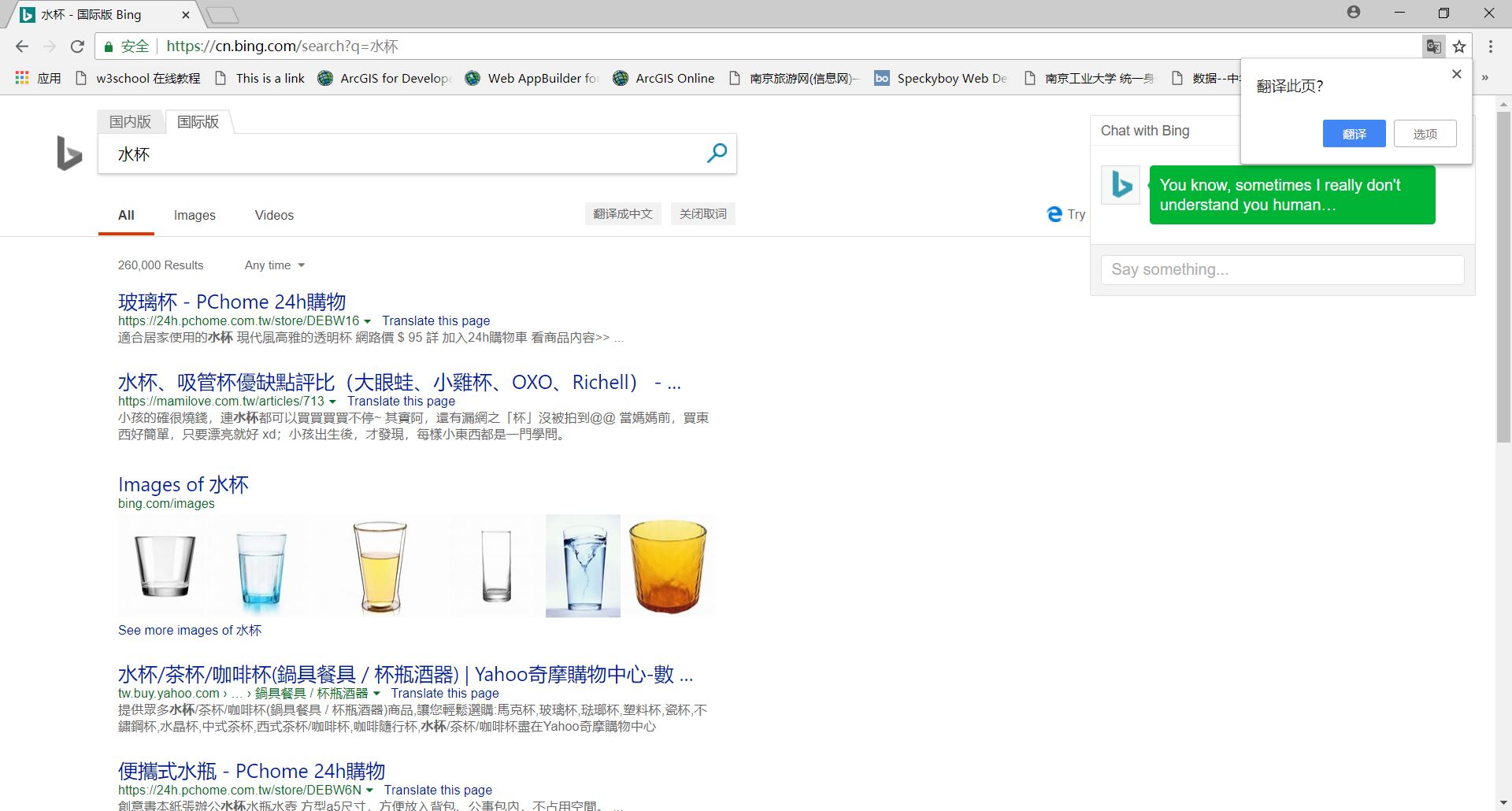
查看地址栏,可以看到bing搜索引擎的URL是https://cn.bing.com。输入完关键字后变成了https://cn.bing.com/search?q=keyword。其中keyword就是要输入的关键字,这里是台灯或者水杯。
根据bing搜索引擎的这种查询格式,编写代码:
#搜索引擎关键字提交
import requests def getHTMLText():
keyword="台灯"
try:
kv={'q':keyword}
#params参数将添加到URL中,作为URL连接的一部分
r=requests.get("https://cn.bing.com/search?",params=kv)
r.raise_for_status() #如果状态不是200,引发HTTPError异常
r.encoding=r.apparent_encoding
return r.text[60000:65000]
except:
return "" def main():
print(getHTMLText()) if __name__=="__main__":
main()

3.图片抓取
图片在网络上以二进制形式存储,在获取图片资源后也以二进制形式写入到本地磁盘中。在网络中找到一张图片,右键可以获得该图片的URL地址,这个地址就是用程序爬取时用到的URL。
#图片抓取程序
import requests
import os #要写入图片到本地磁盘,引入os库 url="http://syds.ngchina.cn/resc/img/difang1.jpg" #图片的URL链接
root="C://pics/" #存放图片的文件夹
#图片在本地磁盘中的路径
#使用split('/')以反斜杠为标志将url分割,取最后一个字符串(即difang1.jpg)
#与前面的root("C://pics/")相连接,形成图片在本地磁盘中的路径
#这句代码起到的效果是,用图片原来的名字保存
path=root+url.split('/')[-1] try:
if not os.path.exists(root): #如果root路径(一个文件夹)不存在,则创建
os.mkdir(root)
if not os.path.exists(path): #如果path路径不存在(即图片不在本地磁盘中)
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content) #将Response对象的信息以二进制形式写入磁盘
f.close()
print("图片保存成功")
else:
print("图片已存在") #path已存在(即图片已经保存在本地磁盘中)
except:
print("图片抓取失败")
python语言的文件相关知识,请参考:http://www.runoob.com/python3/python3-os-file-methods.html。
4.IP地址的查询
在网络上有相关软件或网站可以查询到IP地址,都是通过人机界面交互的形式进行的。如:http://www.ip138.com/。
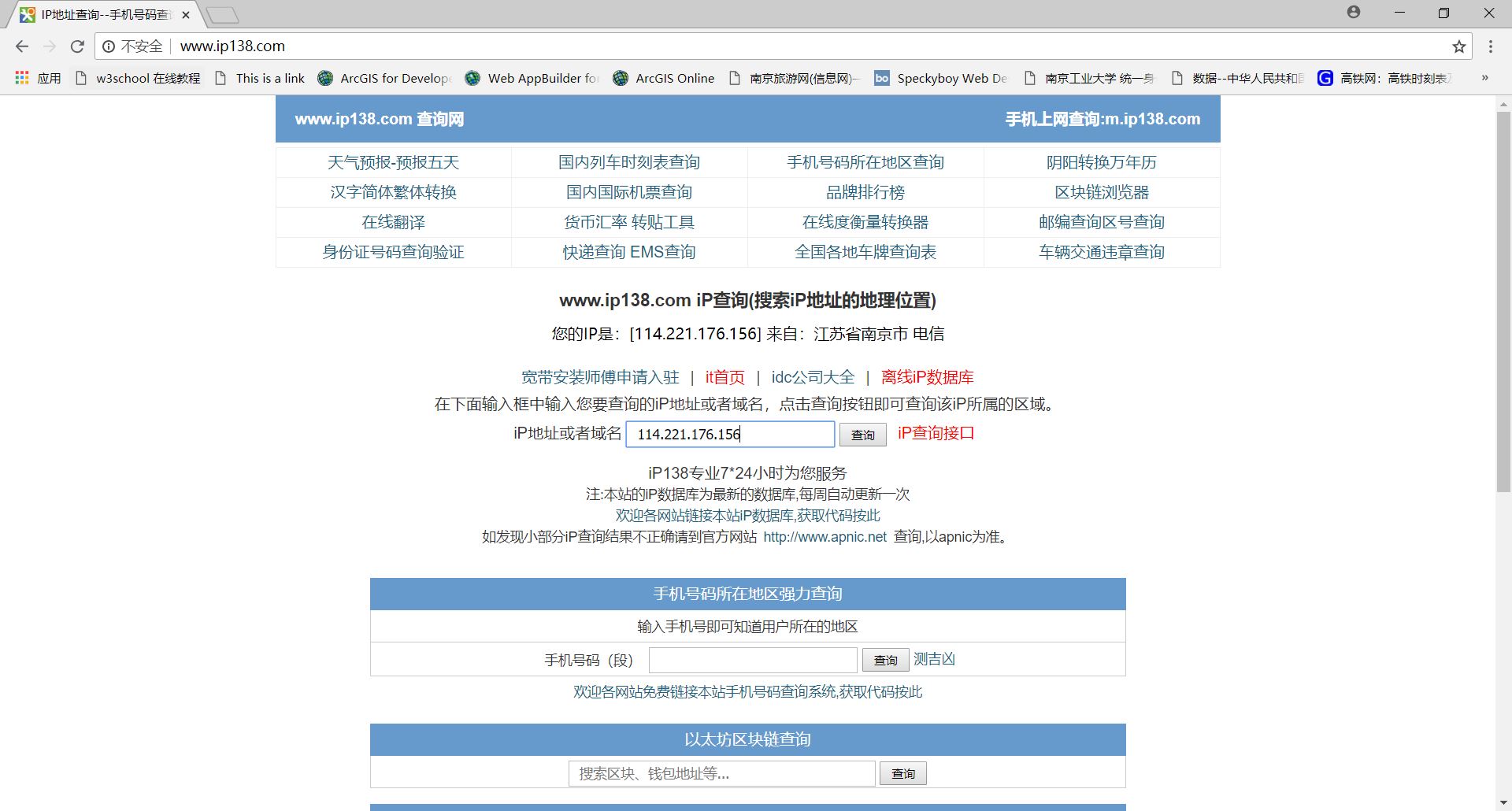
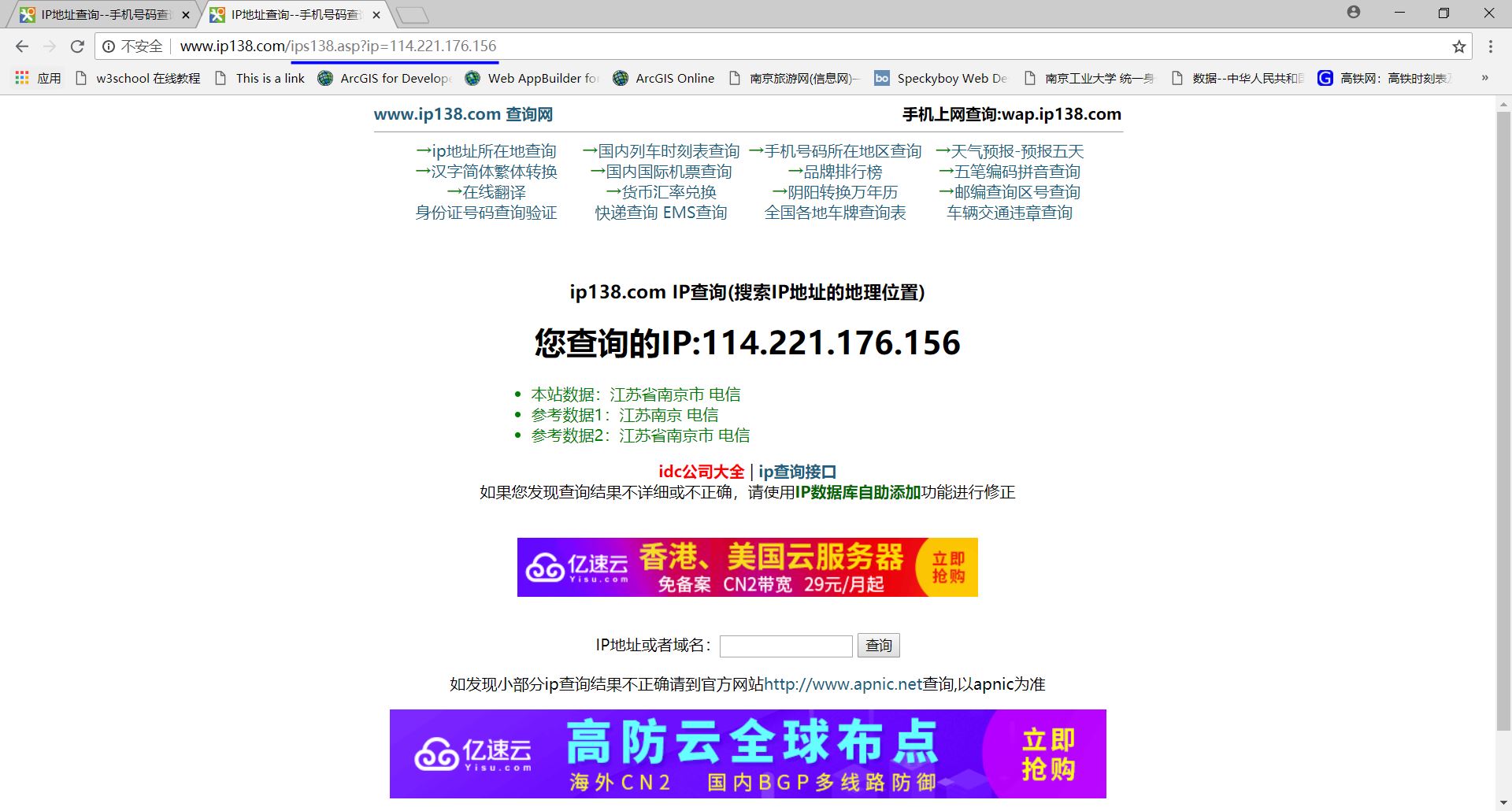
查询IP后,URL链接发生变化。与搜索引擎关键字提交类似,根据这样的变化编写程序:
#IP地址查询
import requests
url="http://www.ip138.com/ips138.asp?ip="
try:
r=requests.get(url+'114.221.176.156') #前面的URL再加上要查询的IP
r.raise_for_status() #如果状态不是200,产生HTTPError异常
r.encoding=r.apparent_encoding
print(r.text[7000:7500]) #返回包含地址信息的字符串区间
except:
print("查询失败")
[python爬虫]Requests-BeautifulSoup-Re库方案--robots协议与Requests库实战的更多相关文章
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- python爬虫从入门到放弃(四)之 Requests库的基本使用
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- python爬虫从入门到放弃(四)之 Requests库的基本使用(转)
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- Python爬虫——用BeautifulSoup、python-docx爬取廖雪峰大大的教程为word文档
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 廖雪峰大大贡献的教程写的不错,写了个爬虫把教程保存为word文件,供大家方便下载学习:http://p ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- Python 爬虫十六式 - 第一式:HTTP协议
HTTP:伟大而又无闻的协议 学习一时爽,一直学习一直爽! Hello,大家好啊,我是Connor,一个从无到有的技术小白.有的人一说什么是HTTP协议就犯愁,写东西的时候也没想过什么是HTTP协 ...
- 【Python爬虫】BeautifulSoup网页解析库
BeautifulSoup 网页解析库 阅读目录 初识Beautiful Soup Beautiful Soup库的4种解析器 Beautiful Soup类的基本元素 基本使用 标签选择器 节点操作 ...
- python 爬虫proxy,BeautifulSoup+requests+mysql 爬取样例
实现思路: 由于反扒机制,所以需要做代理切换,去爬取,内容通过BeautifulSoup去解析,最后入mysql库 1.在西刺免费代理网获取代理ip,并自我检测是否可用 2.根据获取的可用代理ip去发 ...
随机推荐
- request,reponse对象中的方法
1.request对象 客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应.它是HttpServletRequest类的实例. 序号 方 法 说 明 1 obj ...
- 写给大忙人的centos下ftp服务器搭建(以及启动失败/XFTP客户端一直提示“用户身份验证失败”解决方法)
注:个人对偏向于底层基本上拿来就用的应用,倾向于使用安装包,直接yum或者rpm安装:而对于应用层面控制较多或者需要大范围维护的,倾向于直接使用tar.gz版本. 对于linux下的ftp服务器,实际 ...
- [Swift]LeetCode228. 汇总区间 | Summary Ranges
Given a sorted integer array without duplicates, return the summary of its ranges. Example 1: Input: ...
- [Swift]LeetCode392. 判断子序列 | Is Subsequence
Given a string s and a string t, check if s is subsequence of t. You may assume that there is only l ...
- [Swift]LeetCode412. Fizz Buzz
Write a program that outputs the string representation of numbers from 1 to n. But for multiples of ...
- [Swift]LeetCode942. 增减字符串匹配 | DI String Match
Given a string S that only contains "I" (increase) or "D" (decrease), let N = S. ...
- Mysql数据库和表的增删改查以及数据备份&恢复
数据库 查看所有数据库 show databases; 使用数据库 use 数据库名; 查看当前使用的数据库 select database(); 创建数据库 create database 数据库名 ...
- IO复用(较详细)
进程与线程的描述 一个进程至少会创建一个线程,多个线程共享一个程序进程的内存.程序的运行最终是靠线程来完成操作的.线程的数量跟CPU核数有关,一个核最多能发出两个线程.线程的操作主要分为:一:给CPU ...
- Java集合类的那点通俗的认知
文/沉默王二 开门见山地说吧,Java提供了一套完整的集合类(也可以叫做容器类)来管理一组长度可变的对象(也就是集合的元素),其中常见的类型包括List.Set.Queue和Map.从我个人的编程经验 ...
- C++版 - 剑指offer面试题14: 调整数组顺序使奇数位于偶数前面
题目: 调整数组顺序使奇数位于偶数前面 热度指数:11843 时间限制:1秒 空间限制:32768K 本题知识点: 数组 题目描述 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇 ...