【模块04-大数据技术入门】02节-HDFS核心知识
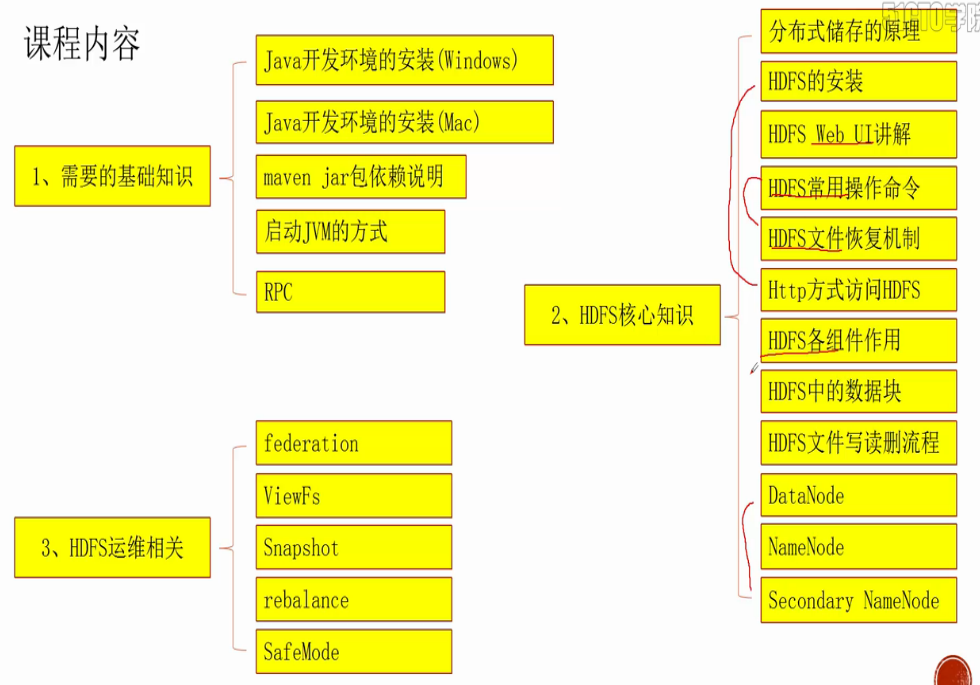
分布式存储
(1) 5PB甚至更大的数据集怎么存储 ?
所有数据分块,每个数据块冗余存储在多台机器上(冗余可提高数据块高可用性)。另外一台机器上启动一个管理所有节点、以及存储在各节点上面数据块的服务。
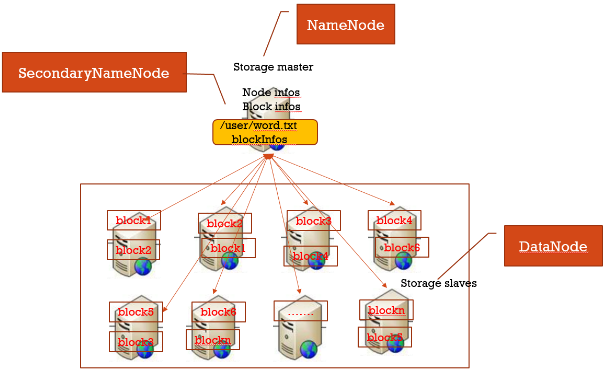
(2)分布式存储集群: master/slave结构集群
- 存在于slave上的文件:表示真实存放数据的文件即本地磁盘文件
- 存在于master上的文件:表示逻辑文件,它表示这个逻辑文件全路径名,与这个全路径对应的有数据块的存储信息(数据块位置等)
HDFS各组件及作用讲解
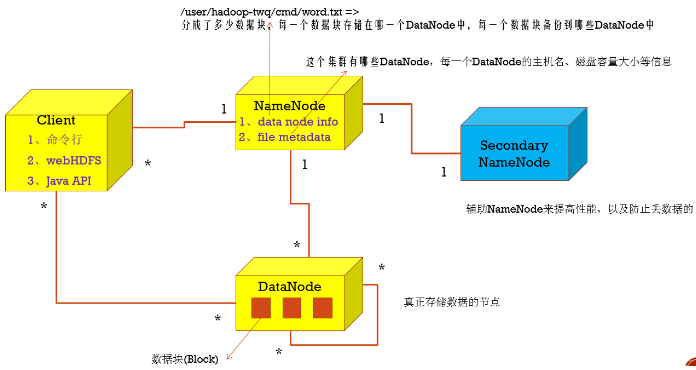
1.NameNode
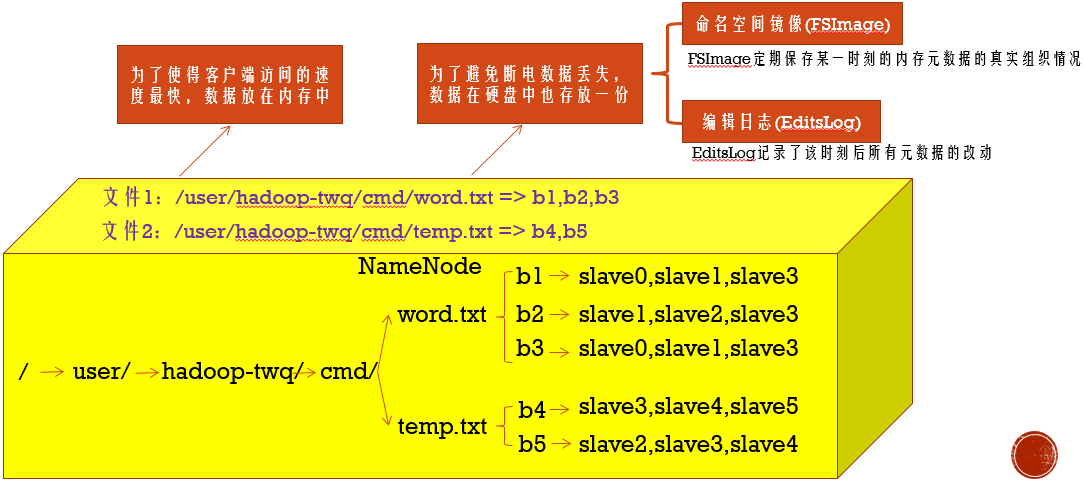
名字节点中维护了两层关系:
(1)HDFS文件系统的文件目录树,以及文件数据块的索引,即每一个文件对应的数据块列表
(2)数据块与数据节点的关系,即某一数据块保存在哪些数据节点中
2.
安装HDFS
(1)下载Hadoop ,选择版本hadoop-2.7.5.tar
(2)master slave1 slave2,使用hadoop-twq用户,家目录下创建目录~/bigdata
mkdir -p ~/bigdata
(3)master,使用hadoop-twq用户,上传安装包到目录~/bigdata,并解压。
cd ~/bigdata
tar -zxvf ~/bigdata/hadoop-2.7.5.tar.gz
(4)master,使用hadoop-twq用户,创建nameNode和dataNode需要的文件目录
mkdir -p ~/bigdata/dfs/name
mkdir -p ~/bigdata/dfs/data
(5)master,使用hadoop-twq用户,修改配置文件【core-site.xml】【hdfs-site.xml】
cd ~/bigdata/hadoop-2.7.5/etc/hadoop
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9999</value>
<description>默认的HDFS路径</description>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>数据块的副本数量,需小于DataNode数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop-twq/bigdata/dfs/name</value>
<description>NameNode存放数据的位置</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop-twq/bigdata/dfs/data</value>
<description>DataNode存放数据的位置</description>
</property>
</configuration>
(6)master,使用hadoop-twq用户,配置JAVA_HOME,修改【hadoop-env.sh】
cd ~/bigdata/hadoop-2.7.5/etc/hadoop vi hadoop-env.sh
export JAVA_HOME=/usr/local/lib/jdk1.8.0_161
(7)master,使用hadoop-twq用户,配置集群里所有DataNode的主机名,修改【slaves】
cd ~/bigdata/hadoop-2.7.5/etc/hadoop vi slaves
slave1
slave2
(8)master,使用hadoop-twq用户,将配置好的hadoop分发到每一个slave上
scp -r ~/bigdata/dfs hadoop-twq@slave1:~/bigdata
scp -r ~/bigdata/dfs hadoop-twq@slave2:~/bigdata scp -r ~/bigdata/hadoop-2.7.5 hadoop-twq@slave1:~/bigdata
scp -r ~/bigdata/hadoop-2.7.5 hadoop-twq@slave2:~/bigdata
(9)master salve1 slave2,使用hadoop-twq用户,配置环境变量
vi ~/.bash_profile
export HADOOP_HOME=~/bigdata/hadoop-2.7.5
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source ~/.bash_profile
which hdfs
(10)master,使用hadoop-twq用户,格式化并启停HDFS
hdfs namenode -format ==>格式化
start-dfs.sh ==>启动hdfs
jps
http://master的IP地址:50070/ ==>看下是否部署成功
stop-dfs.sh ==>停止hdfs
安装注意事项:
1..更改salves配置前,需要先停止集群,否则有datanode无法停止。
2.多次格式化,可能会出现namenode和datanode的clusterID不一致。(clusterID在/home/hadoop-twq/bigdata/dfs/data/current/VERSION中)
3.core-site.xml中fs.defaultFS 描述集群中NameNode结点的URI(包括协议、主机名称、端口号)
4.hdfs-site.xml中dfs.namenode.http-address,描述HDFS web界面的监听端口,默认50070
添加节点
(1)修改所有节点的host
(2)修改namenode的配置文件slaves
(3)在新节点的机器上,启动服务
hadoop-daemon.sh start datanode
hadoop-daemon.sh start tasktracker
(4)namenode节点,均衡block
a.如果不balance,那么cluster会把新的数据都存放在新的node上,这样会降低mapred的工作效率。
start-balancer.sh
b.设置平衡阈值,默认是10%,值越低各节点越平衡,但消耗时间也更长
start-balancer.sh -threshold 5
c.配置hdfs balance时datanode之间数据迁移的带宽设置,默认只有1048576(1M/s)
vi hdfs-site.xml
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value>
<description>
Specifies the maximum amount of bandwidth that each datanode
can utilize for the balancing purpose in term of
the number of bytes per second.
</description>
</property>
删除节点
(1)阻止待删除的机器连接Namenode
vi conf/hdfs-site.xml
<property>
<name>dfs.hosts.exclude</name>
<value>~/bigdata/hadoop-2.7.5/etc/hadoop/excludes</value>
<description>
Names a file that contains a list of hosts that are
not permitted to connect to the namenode. The full pathname of the
file must be specified. If the value is empty, no hosts are
excluded.
</description>
</property>
vi ~/bigdata/hadoop-2.7.5/etc/hadoop/excludes ==>待下线机器hostname一个一行
slave3
slave4
(2)强制重新加载配置
hadoop dfsadmin -refreshNodes ==>强制重新加载配置,会在后台进行Block块移动
hadoop dfsadmin -report ==>查看到现在集群上连接的节点, Decommission in progress(执行中), Decommissioned(执行完毕)
(3)关闭节点
等待刚刚的操作结束后,需要下架的机器就可以安全的关闭了
(4)再次编辑excludes文件
一旦完成了机器下架,它们就可以从excludes文件移除了
登录要下架的机器,会发现DataNode进程没有了,但是TaskTracker依然存在,需要手工处理一下。
参考文档:
【模块04-大数据技术入门】02节-HDFS核心知识的更多相关文章
- 大数据学习(02)——HDFS入门
Hadoop模块 提到大数据,Hadoop是一个绕不开的话题,我们来看看Hadoop本身包含哪些模块. Common是基础模块,这个是必须用的.剩下常用的就是HDFS和YARN. MapReduce现 ...
- 大数据技术之Hadoop(HDFS)
第1章 HDFS概述 1.1 HDFS产出背景及定义 1.2 HDFS优缺点 1.3 HDFS组成架构 1.4 HDFS文件块大小(面试重点) 第2章 HDFS的Shell操作(开发重点) 1.基本语 ...
- 大数据技术之Hadoop入门
第1章 大数据概论 1.1 大数据概念 大数据概念如图2-1 所示. 图2-1 大数据概念 1.2 大数据特点(4V) 大数据特点如图2-2,2-3,2-4,2-5所示 图2-2 大数据特点之大量 ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- TOP100summit:【分享实录-WalmartLabs】利用开源大数据技术构建WMX广告效益分析平台
本篇文章内容来自2016年TOP100summitWalmartLabs实验室广告平台首席工程师.架构师粟迪夫的案例分享. 编辑:Cynthia 粟迪夫:WalmartLabs实验室广告平台首席工程师 ...
- 利用大数据技术处理海量GPS数据
我秀中国物联网地图服务平台目前接入的监控车辆近百万辆,每天采集GPS数据7亿多条,产生日志文件70GB,使用传统的数据处理方式非常耗时. 比如,仅仅对GPS做一些简单的统计分析,程序就需要几个小时才能 ...
- 大数据技术之Hadoop3.1.2版本HA模式
大数据技术之Hadoop3.1.2版本HA模式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Hadoop的HA特点 1>.主备NameNode 2>.解决单点故障 ...
- 大数据技术之HBase
第1章 HBase简介 1.1 什么是HBase HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储. 官方 ...
随机推荐
- .NET Core玩转机器学习
最近在搞机器学习,目前国内没有什么关于ML.NET的教程,官方都是一大堆英文,经过了我的努力,找到了Relax Development大哥的博客,有关于ML.NET的内容 原文地址:https://w ...
- solr之环境配置一
安装Java JDK solr运行需要java serverlet 容器,默认使用jetty,或者tomcat,jboss等等. 下载一个jdk,我的jdk是jdk1.7.0_65. 安装JDK的步骤 ...
- 【朝花夕拾】Android编码风格篇
结合51CTO学院中张凌华老师讲的编码风格课程,对自己平时工作中的形成的一些编码风格做一些总结. 一. 项目开发目录命名: Requirement - 需求相关文档 Design - 设计 Plann ...
- 面试小知识:MySQL索引相关
前言 本模板主要是一些面试相关的题目,对于每一道问题,我会提供简单的解答,答案的来源主要是基于自己看了各方资料之后的理解,如果有错的,欢迎指点出来. 1. 什么是最左前缀原则? 以下回答全部是基于My ...
- Chapter 5 Blood Type——4
"Does he mean you?" Jessica asked with insulting astonishment in her voice. “他对你有意思吗?”Jess ...
- 剖析HBase负载均衡和性能指标
1.概述 在分布式系统中,负载均衡是一个非常重要的功能,在HBase中通过Region的数量来实现负载均衡,HBase中可以通过hbase.master.loadbalancer.class来实现自定 ...
- spring cloud 配置zuul实用
在线演示 演示地址:http://139.196.87.48:9002/kitty 用户名:admin 密码:admin 技术背景 前面我们通过Ribbon或Feign实现了微服务之间的调用和负载均衡 ...
- ES6躬行记(17)——Map
一.Map Map类似于Object(对象),可用来存储键值对,但需要通过SameValueZero算法保持键的唯一性.与Set一样,在使用之前也得要实例化,如下代码所示,构造函数Map()中的参数也 ...
- webpack4.0各个击破(10)—— Integration篇
webpack作为前端最火的构建工具,是前端自动化工具链最重要的部分,使用门槛较高.本系列是笔者自己的学习记录,比较基础,希望通过问题 + 解决方式的模式,以前端构建中遇到的具体需求为出发点,学习we ...
- 【学习笔记】tensorflow文件读取
目录 文件读取 文件队列构造 文件阅读器 文件内容解码器 开启线程操作 管道读端批处理 CSV文件读取案例 先看下文件读取以及读取数据处理成张量结果的过程: 一般数据文件格式有文本.excel和图片数 ...