Hadoop学习------Hadoop安装方式之(三):分布式部署
这里为了方便直接将单机部署过的虚拟机直接克隆,当然也可以不这样做,一个个手工部署。
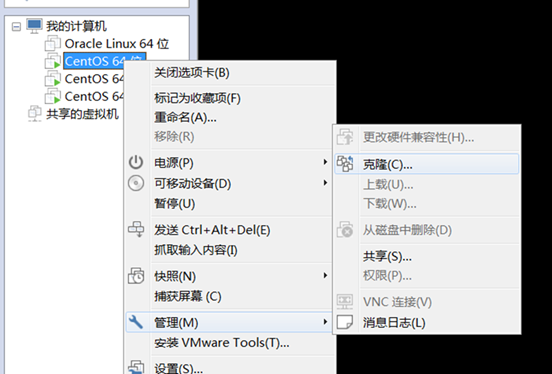
创建完整克隆——>下一步——>安装位置。等待一段时间即可。
我这边用了三台虚拟机,分别起名master,slave1.slave2
1、修改主机名、ip
1.1关闭防火墙
CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
在 CentOS 6.x 中,可以通过如下命令关闭防火墙:
service iptables stop # 关闭防火墙服务
chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了
若用是 CentOS 7,需通过如下命令关闭(防火墙服务改成了 firewall):
systemctl stop firewalld.service # 关闭firewall
systemctl disable firewalld.service # 禁止firewall开机启动
1.2 修改主机名
在 CentOS 6.x 中 vi /etc/sysconfig/network
在CentOS 7或者Ubuntu 中 vi /etc/hostname

在其他两节点同样如此。分别改为slave1.slave2
1.3 修改ip地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0 修改ip 地址 然后重启网卡
service network restart 发现重启失败

这是因为基本系统的网络相关配置都是基于eth0的,如果基于此克隆虚拟机继续克隆或复制新的虚拟机,网卡的标识每一次都会自动加1变成eth1(第二次克隆会变成eth2),dmesg却显示内核只识别到网卡eth0。
解决办法: 打开/etc/udev/rules.d/70-persistent-net.rules 记录下,eth1网卡的mac地址00:0c:29:50:bd:17
接下来 vi//etc/sysconfig/network-scripts/ifcfg-eth0
将 DEVICE="eth0" 改成 DEVICE="eth1" ,
将 HWADDR="00:0c:29:8f:89:97" 改成上面的mac地址 HWADDR="00:0c:29:50:bd:17"
最后,重启网络 service network restart 然后就能重启成功
1.4 修改hosts 使所用节点IP映射
在每台虚拟机上进行如下操作。
vi /etc/hosts
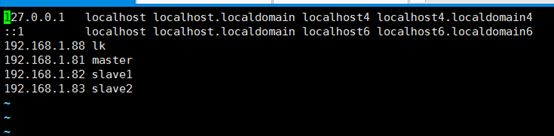
修改完成后需要重启一下 reboot
2、打通master到slave节点的SSH无密码登录
2.1设置本机无密码登录(各节点都要)
之前在单机部署时已经设置过了,这里再说一遍,没有设置的可以看下
第一步:产生密钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
第二部:导入authorized_keys
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第二部导入的目的是为了无密码等,这样输入如下命令:
ssh localhost

2.2 设置远程无密码登录
我这边偷懒用的是root用户,正规应该用hadoop用户
进入slave1的.ssh目录 cd /root/.ssh
复制公钥文件到master
scp authorized_keys root@master:~/.ssh/authorized_keys_from_master
进入到master的.ssh目录 将文件导入到authorized_keys
cat authorized_keys_from_master >> authorized_keys
此时 slave1 可以无密码远程登录master
同理
进入slave2的.ssh目录 cd /root/.ssh
复制公钥文件到master
scp authorized_keys root@master:~/.ssh/authorized_keys_from_master
进入到master的.ssh目录 将文件导入到authorized_keys
cat authorized_keys_from_master >> authorized_keys
然后 将master 的authorized_keys文件复制到slave1和slave2中,他们之间就可以互相无密码远程访问。
scp authorized_keys root@salve1:~/.ssh/authorized_keys
scp authorized_keys root@salve2:~/.ssh/authorized_keys
ssh root@slave1 不需要密码就直接进去了

3、修改配置文件
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
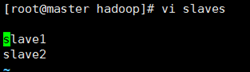
3.1 文件slaves
文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉让 Master 节点仅作为 NameNode 使用。
这里让 Master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加两行内容:slave1。slave2
cd /usr/local/hadoop/etc/hadoop/
vi slaves
3.2 core-site.xml
cd /usr/local/hadoop/etc/hadoop/
vi core-site.xml
在其中的<configuration>中添加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
3.3 hdfs-site.xml
dfs.replication 的值是副节点个数,有几个就写几个,这边设为2
cd /usr/local/hadoop/etc/hadoop/
vi hdfs-site.xml
其中的<configuration>中添加以下内容
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
3.4 mapred-site.xml
cd /usr/local/hadoop/etc/hadoop/
需要将mapred-site.xml.template 文件改名或者复制一份
mv mapred-site.xml.template mapred-site.xml
或 cp mapred-site.xml.template mapred-site.xml
然后在进行编辑 vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
3.5 yarn-site.xml
cd /usr/local/hadoop/etc/hadoop/
vi yarn-site.xml
在其中的<configuration>中 添加以下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.6 启动并检验
配置好后,按照以上步骤在各个节点均执行一边,或者将 master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。
在master
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
scp ./hadoop.master.tar.gz slave1:/usr/local
在slave1
tar -zxf ~/hadoop.master.tar.gz -C /usr/local
chown -R hadoop /usr/local/hadoop
在slave2上执行同样操作。就能将Hadoop部署好。
每个节点部署好后
在节点上执行NameNode 的格式化
hdfs namenode –format 或者 hadoop namenode format
启动hdfs 在master节点上执行 start-dfs.sh
启动yarn 在master节点上执行 start-yarn.sh
启动job history server 在master节点上执行 mr-jobhostory-daemon.sh start historyserver
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程
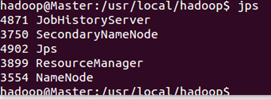
在 Slave 节点可以看到 DataNode 和 NodeManager 进程
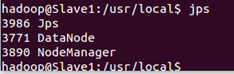
缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。
同样我们可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/。如果不成功,可以通过启动日志排查原因。
3.7执行分布式实例
创建 HDFS 上的用户目录
hdfs dfs -mkdir -p /user/hadoop
将 /usr/local/hadoop/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中
hdfs dfs -mkdir input
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
通过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中
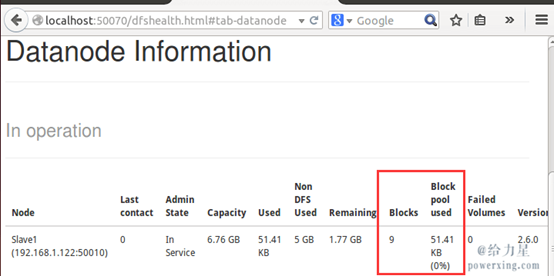
接着就可以运行 MapReduce 作业了
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
运行时的输出信息与伪分布式类似,会显示 Job 的进度。
可能会有点慢,但如果迟迟没有进度,比如 5 分钟都没看到进度,那不妨重启 Hadoop 再试试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改 YARN 的内存配置解决。
同样可以通过 Web 界面查看任务进度 http://master:8088/cluster,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息
4 、关闭Hadoop集群
同样关闭Hadoop集群也是在Master节点上执行的
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:"Calibri","sans-serif";
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;
mso-font-kerning:1.0pt;}
Hadoop学习------Hadoop安装方式之(三):分布式部署的更多相关文章
- Hadoop学习------Hadoop安装方式之(二):伪分布部署
要想发挥Hadoop分布式.并行处理的优势,还须以分布式模式来部署运行Hadoop.单机模式是指Hadoop在单个节点上以单个进程的方式运行,伪分布模式是指在单个节点上运行NameNode.DataN ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- Hadoop学习------Hadoop安装方式之(一):单机部署
Hadoop 默认模式为单机(非分布式模式),无需进行其他配置即可运行.非分布式即单 Java 进程,方便进行调试. 1.创建用户 1.1创建hadoop用户组和用户 一般我们不会经常使用root用户 ...
- Hadoop学习笔记——安装Hadoop
sudo mv /home/common/下载/hadoop-2.7.2.tar.gz /usr/local sudo tar -xzvf hadoop-2.7.2.tar.gz sudo mv ha ...
- Hadoop伪分布安装详解(三)
目录: 1.修改主机名和用户名 2.配置静态IP地址 3.配置SSH无密码连接 4.安装JDK1.7 5.配置Hadoop 6.安装Mysql 7.安装Hive 8.安装Hbase 9.安装Sqoop ...
- Hadoop学习(一):完全分布式集群环境搭建
1. 设置免密登录 (1) 新建普通用户hadoop:useradd hadoop(2) 在主节点master上生成密钥对,执行命令ssh-keygen -t rsa便会在home文件夹下生成 .ss ...
- Hadoop学习---Hadoop的深入学习
Hadoop生态圈 存储数据HDFS(Hadoop Distributed File System),运行在通用硬件上的分布式文件系统.具有高度容错性.高吞吐量的的特点. 处理数据MapReduce, ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- Hadoop学习-hdfs安装及其一些操作
hdfs:分布式文件系统 有目录结构,顶层目录是: /,存的是文件,把文件存入hdfs后,会把这个文件进行切块并且进行备份,切块大小和备份的数量有客户决定. 存文件的叫datanode,记录文件的切 ...
随机推荐
- Python字符串 --Python3
Python语言中,字符串是用两个双引号或者单引号括起来的词汇表或多个字符. 1.Python字符串的两种序号体系 反向递减序号:-- -9 -8 -7 -6 -5 -4 -3 -2 -1 正向递增序 ...
- Robot Framework自动化测试(1)
Python: https://www.python.org/ RF框架是基于python 的,所以一定要有python环境. Robot framework : https://pypi.pytho ...
- java.lang.ClassNotFoundException: org.apache.log4j.Logger 异常
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'd ...
- C# 抽象类和接口的差别
抽象类和接口最终目的:抽象类实现多态化,接口实现功能化.比如汽车:接口就是轮子,发动机,车身等零部件,抽象类则是颜色,款式,型号等参数性东西. 抽象类(abstract): (1) 抽象方法只作声明, ...
- MPI编程——分块矩阵乘法(cannon算法)
https://blog.csdn.net/a429367172/article/details/88933877
- Jupyter Notebook 修改默认打开的文件夹的位置
初次使用Jupyter Notebook,确实好用啊!!,又好看又好用,不过还是遇到了一个问题,安装好之后,打开Jupyter Notebook 的时候,默认的文件夹的位置是C盘下面的XXX目录,但是 ...
- 使用XStream解析复杂XML并插入数据库(二)
标注黄色地方:我需要加深学习!!! 我写的是webservice,目前具体写webservice的步骤我还不清楚, 整理完小知识开始整理webservice! 针对以下格式的XML进行解析 <? ...
- PAT 1136 A Delayed Palindrome
1136 A Delayed Palindrome (20 分) Consider a positive integer N written in standard notation with k ...
- jquery <div> 排序
var asc_active = function(a, b) { var av = Number($(a).find('.active_num .v').html()); var bv = Numb ...
- 第一个Azure应用
https://www.azure.cn/zh-cn/ 学习Azure,首先看的是官网Azure介绍,因为用到了虚拟机及存储等因此,着重看这两块. 本文Demo是通过API发送消息,当收到消息后新建虚 ...