用python爬取杭电oj的数据
暑假集训主要是在杭电oj上面刷题,白天与算法作斗争,晚上望干点自己喜欢的事情!
首先,确定要爬取哪些数据:
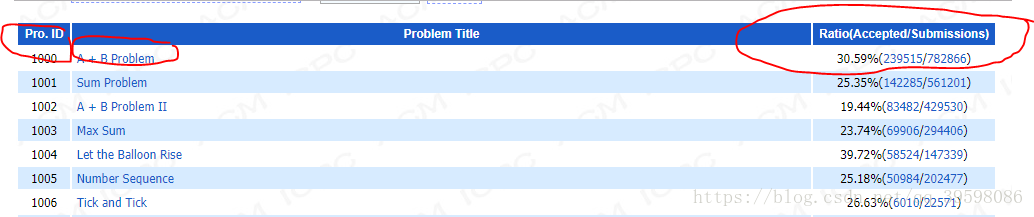
如上图所示,题目ID,名称,accepted,submissions,都很有用。
查看源代码知:

所有的数据都在一个script标签里面。
思路:用beautifulsoup找到这个标签,然后用正则表达式提取。
话不多说,上数据爬取的代码:
import requests
from bs4 import BeautifulSoup
import time
import random
import re
from requests.exceptions import RequestException
prbm_id = []
prbm_name = []
prbm_ac = []
prbm_sub = []
def get_html(url): # 获取html
try:
kv = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, timeout=5, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
random_time = random.randint(1, 3)
time.sleep(random_time) # 应对反爬虫,随机休眠1至3秒
return r.text
except RequestException as e: # 异常输出
print(e)
return ""
def get_hdu():
count = 0
for i in range(1, 56):
url = "http://acm.hdu.edu.cn/listproblem.php?vol=" + str(i)
# print(url)
html = get_html(url)
# print(html)
soup = BeautifulSoup(html, "html.parser")
cnt = 1
for it in soup.find_all("script"):
if cnt == 5:
# print(it.get_text())
str1 = it.string
list_pro = re.split("p\(|\);", str1) # 去除 p(); 分割
# print(list_pro)
for its in list_pro:
if its != "":
# print(its)
temp = re.split(',', its)
len1 = len(temp)
prbm_id.append(temp[1])
prbm_name.append(temp[3])
prbm_ac.append(temp[len1-2])
prbm_sub.append(temp[len1-1])
cnt = cnt + 1
count = count + 1
print('\r当前进度:{:.2f}%'.format(count * 100 / 55, end='')) # 进度条
def main():
get_hdu()
root = "F://爬取的资源//hdu题目数据爬取2.txt"
len1 = len(prbm_id)
for i in range(0, len1):
with open(root, 'a', encoding='utf-8') as f: # 存储个人网址
f.write("hdu"+prbm_id[i] + "," + prbm_name[i] + "," + prbm_ac[i] + "," + prbm_sub[i] + '\n')
# print(prbm_id[i])
if __name__ == '__main__':
main()
爬取数据之后,想到用词云生成图片,来达到数据可视化。
本人能力有限,仅根据AC的数量进行分类,生成不同的词云图片。数据分析代码如下:
import re
import wordcloud
from scipy.misc import imread # 这是一个处理图像的函数
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
import os
prbm_id = []
prbm_name = []
prbm_ac = []
prbm_sub = []
def read():
f = open(r"F://爬取的资源//hdu题目数据爬取2.txt", "r", encoding="utf-8")
list_str = f.readlines()
for it in list_str:
list_pre = re.split(",", it)
prbm_id.append(list_pre[0].strip('\n'))
prbm_name.append(list_pre[1].strip('\n'))
prbm_ac.append(list_pre[2].strip('\n'))
prbm_sub.append(list_pre[3].strip('\n'))
def data_Process():
for it in range(0, len(prbm_ac)):
# print(prbm_sub[it])
root = "F://爬取的资源//词语统计.txt"
num1 = int(prbm_ac[it])
# num2 = int(prbm_ac[it])*1.0/int(prbm_sub[it])
if 5000 <= num1 <= 10000: # 分类
with open(root, 'a', encoding='utf-8') as f: # 写入txt文件,用于wordcloud词云生成
for i in range(0, int(num1/100)): # num1/100,这里可根据num1,除数变化
f.write(prbm_id[it] + ' ')
def main():
read()
data_Process()
text = open(r"F://爬取的资源//词语统计.txt", "r", encoding='utf-8').read()
# 生成一个词云图像
back_color = imread('F://爬取的资源//acm.jpg') # 解析该图片
w = wordcloud.WordCloud(background_color='white', # 背景颜色
mask=back_color, # 以该参数值作图绘制词云,这个参数不为空时,width和height会被忽略
width=300,
height =100,
collocations=False # 去掉重复元素
)
w.generate(text)
plt.imshow(w)
plt.axis("off")
plt.show()
os.remove("F://爬取的资源//词语统计.txt")
w.to_file("F://爬取的资源//hdu热度词云5.png")
if __name__ == '__main__':
main()
生成的图片效果展示如下:

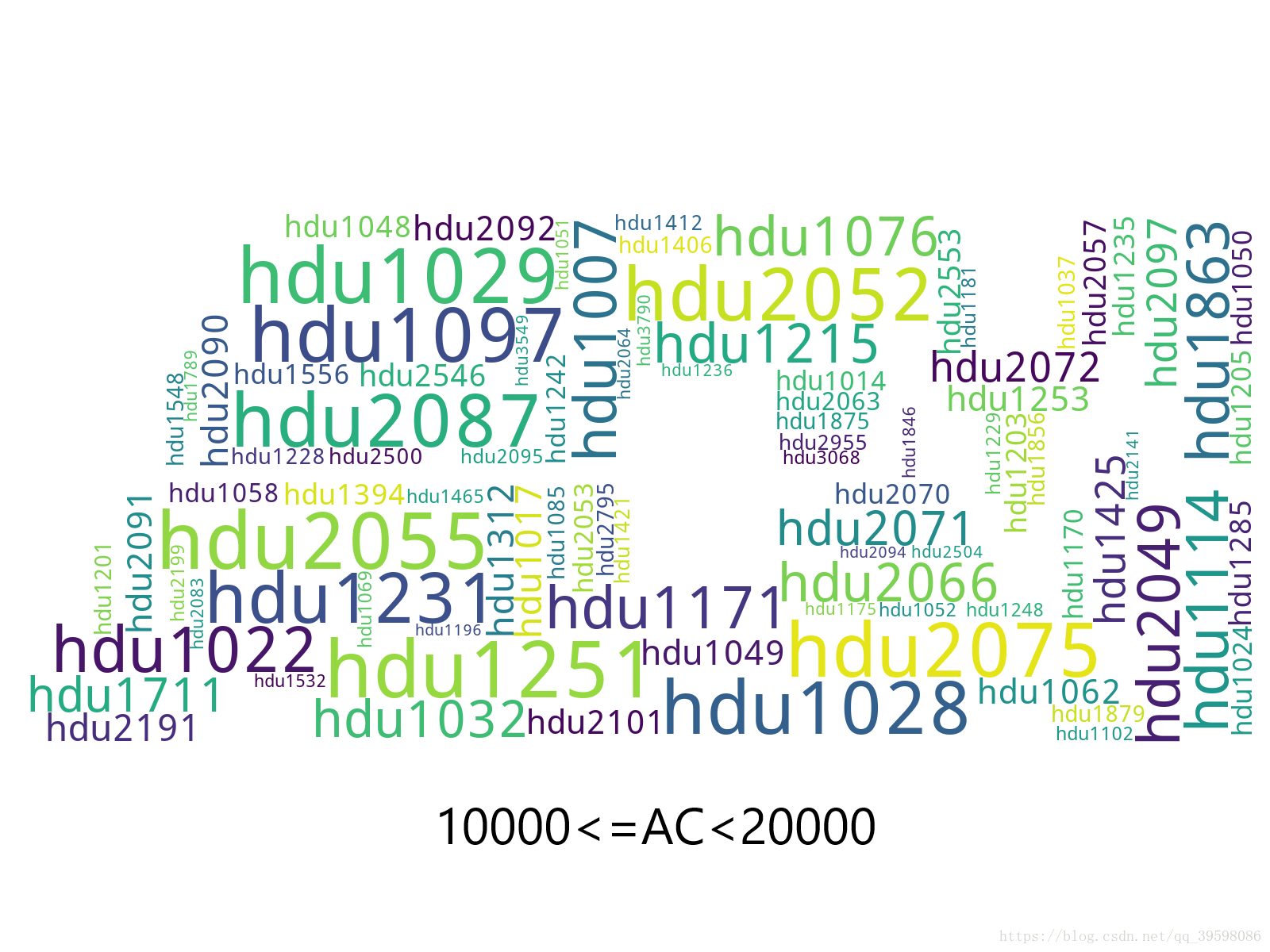



词云是根据每个分类里面,ac的数量生成的。
仅以此,向广大在杭电上刷题的苦逼acmer们,表达此刻心中的敬意。愿每位acmer都能勇往直前,披荆斩棘。
用python爬取杭电oj的数据的更多相关文章
- 爬取杭电oj所有题目
杭电oj并没有反爬 所以直接爬就好了 直接贴源码(参数可改,循环次数可改,存储路径可改) import requests from bs4 import BeautifulSoup import ti ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行.对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了.本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似 ...
- Python爬取6271家死亡公司数据,一眼看尽十年创业公司消亡史!
小五利用python将其中的死亡公司数据爬取下来,借此来观察最近十年创业公司消亡史. 获取数据 F12,Network查看异步请求XHR,翻页. 成功找到返回json格式数据的url, 很多人 ...
- Python爬取6271家死亡公司数据,看十年创业公司消亡史
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 朱小五 凹凸玩数据 PS:如有需要Python学习资料的小伙伴可以加 ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬取上交所一年大盘数据
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 半个码农2018 PS:如有需要Python学习资料的小伙伴可以加点 ...
- Python爬取某网站文档数据完整教程(附源码)
基本开发环境 (https://jq.qq.com/?_wv=1027&k=NofUEYzs) Python 3.6 Pycharm 相关模块的使用 (https://jq.qq.com/?_ ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
随机推荐
- QEMU KVM Libvirt手册(6) – Network Block Device
网络块设备是通过NBD Server将虚拟块设备通过TCP/IP export出来,可以远程访问. NBD Server通常是qemu-nbd 可以提供unix socket qemu-nbd -t ...
- new Date()设置日期在IOS的兼容问题
一般这样创建一个日期变量 var d = new Date("2017-08-11 12:00:00"); 发现在iOS中不兼容,返回valid Date. IOS中不支持 - 连 ...
- 【安富莱原创开源应用第2期】基于RL-USB和RL-FlashFS的完整NAND解决方案,稳定好用,可放心用于产品批量
说明:0. NAND Flash这块经常有人咨询,这里发布一个完整的解决方案,支持擦写均衡,坏块管理,ECC和掉电保护. 早期的时候我们是用的自己做的NAND算法,支持滑块管理,擦写均衡 ...
- [Swift]LeetCode837. 新21点 | New 21 Game
Alice plays the following game, loosely based on the card game "21". Alice starts with 0 p ...
- HashMap? ConcurrentHashMap? 相信看完这篇没人能难住你!
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
- C++中的to_string()函数[C++11支持]
C++ -> 字符串库 -> std::basic_string 定义于头文件 std::string to_string(int value); (1) (C++11起) std::st ...
- windows git 上传
1.打开git.bash 2. 告诉要传的git的用户名字 和邮箱地址 git config --global user.name "CardLove" git config -- ...
- 给vs2015添加EF
今天做EF的小例子时,发现需要添加实体数据模型,但是不管怎么找在新建项中都找不到这个选项,这是怎么回事,于是就开始百度吧,有的说可能是VS安装时没有全选,也有的人说可能是重装VS时,没有将注册表清除, ...
- Typora中的Markdown教程
Tutorial of markdown in Typora 工欲善其事,必先利其器 如上所说,这里给大家安利一款高BIG的利器Typora,这是一款文艺青年(装逼)必备的用于编写markdown的打 ...
- Spring Boot分布式系统实践【扩展1】shiro+redis实现session共享、simplesession反序列化失败的问题定位及反思改进
前言 调试之前请先关闭Favicon配置 spring: favicon: enabled: false 不然会发现有2个请求(如果用nginx+ 浏览器调试的话) 序列化工具类[ ...