Python进阶3---python类型注解、functools
函数定义的弊端


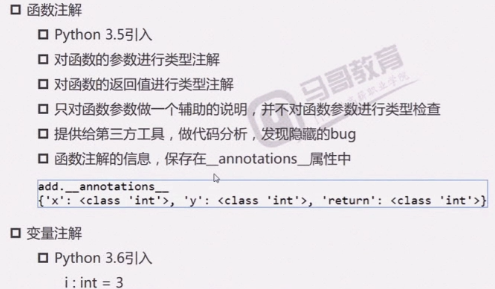
函数注解Function Annotations

业务应用

inspect模块

#示例
import inspect
def add(x,y:int,*args,**kwargs) -> int:
return x+y sig = inspect.signature(add)
print('sig:',sig)
print('params :',sig.parameters)#Ordereddict
print('return :',sig.return_annotation)
print(sig.parameters['x'])
print(sig.parameters['y'])
print(sig.parameters['y'].annotation)
print(sig.parameters['args'])
print(sig.parameters['args'].annotation)
print(sig.parameters['kwargs'])
print(sig.parameters['kwargs'].annotation)
print(sig.parameters['kwargs'].empty)
print(sig.parameters['kwargs'].kind)
'''
sig: (x, y:int, *args, **kwargs) -> int
params : OrderedDict([('x', <Parameter "x">), ('y', <Parameter "y:int">), ('args', <Parameter "*args">), ('kwargs', <Parameter "**kwargs">)])
return : <class 'int'>
x
y:int
<class 'int'>
*args
<class 'inspect._empty'>
**kwargs
<class 'inspect._empty'>
<class 'inspect._empty'>
VAR_KEYWORD
'''



业务应用


functools模块进阶






#源码 _make_key _HashSeq
def _make_key(args, kwds, typed,
kwd_mark = (object(),),
fasttypes = {int, str, frozenset, type(None)},
tuple=tuple, type=type, len=len): key = args
if kwds:
key += kwd_mark
for item in kwds.items():
key += item
if typed:
key += tuple(type(v) for v in args)
if kwds:
key += tuple(type(v) for v in kwds.values())
elif len(key) == 1 and type(key[0]) in fasttypes:
return key[0]
return _HashedSeq(key) class _HashedSeq(list):
__slots__ = 'hashvalue' def __init__(self, tup, hash=hash):
self[:] = tup
self.hashvalue = hash(tup) def __hash__(self):
return self.hashvalue

#利用缓存可以大大提高效率,类似于用空间换取时间!注意缓存与缓冲的区别!
import functools
@functools.lru_cache()
def fib(n):
if n<2:
return n
else:return fib(n-1)+fib(n-2) print(fib(100))

装饰器练习*****

#第一题
#装饰器的应用
#实现一个cache装饰器,实现可过期的被清除的功能
'''
简化设计,函数的形参定义不包括可变位置参数、可变关键词参数和keyword-only参数
可以不考虑缓存满了之后的换出问题。 数据类型的选择:
缓存的应用场景,是有数据需要频繁查询,且每次查询都需要大量计算或等待时间之后才能返回结果的情况,
使用缓存来提高查询速度,用空间换取时间。 cache应该选用什么数据结构?
便于查询的,且能快速找到的数据结构。每次查询的时候,只要输入一致,就应该得到同样的结果(顺序也一致,例如减法函数,参数顺序不一致,结果不一样)
基于上面的分析,此数据结构应该是字典。通过一个key,对应一个value。
key是参数列表组成的结构,value是函数返回值。难点在于key如何处理! key的存储
key必须是hash类,key能接受位置参数和关键字参数传参,位置参数是被收集在一个tuple中的,本身就有序
关键字参数被收集在一个字典中,本身无序,这会带来一个问题,传参的顺序未必是字典中保存的顺序。如何解决?
OrderedDict行吗?可以,它可以记录顺序。
不用OrderedDict行吗?可以,用一个tuple保存排过序的字典的item的kv对。 key的异同
什么才算是相同的key呢?定义一个加法函数,那么传参方式就应该有以下4种:
1.add(4,5)
2.add(4,y=5)
3.add(x=4,y=5)
4.add(y=5,x=4)
上面4种,可以有下面两种理解:
第一种: 3和4相同,1,2和3都不同。
第二种: 1、2、3、4全部相同。
lru_cache实现了第一种,可以看出单独的处理了位置参数和关键字参数。
但是函数定义为def add(4,y=5),使用了默认值,如何理解add(4,5)和add(4)是否一样呢?
如果认为一样,那么lru_cache无能为力,就需要使用inspect来自己实现算法。 key的要求
key必须是hashable,由于key是所有实参组合而成,而且最好要作为key的,key一定要可以hash,但是如果key有不可hash类型数据,就无法完成。
lru_cache就不可以,缓存必须使用key,但是key必须可hash,所以只能适用实参是不可变类型的函数调用。 key算法设计
inspect模块获取函数签名后,取parameters,这是一个有序字典,会保存所有参数的信息。
构建一个字典params_dict,按照位置顺序从args中依次对应参数名和传入的实参,组成kv对,存入params_dict中。
kwargs所有值update到params_dict中。
如果使用了缺省值的参数,不会出现在实参params_dict中,会出现在签名parameters中,缺省值也定义在其中。 调用的方式
普通的函数调用可以,但是过于明显,最好类似lru_cache的方式,让调查者无察觉的使用缓存。
构建装饰器函数 过期功能
一般缓存系统都有过期功能。
过期什么呢?
它是某一个key过期。可以对每一个key单独设置过期时间,也可以对这些key统一设定过期时间。
本次的实现就简单点,统一设置key的过期时间,当key生存超过了这个时间,就自动被清除。
注意:这里并没有考虑多线程等问题。而且这种过期机制,每一次都有遍历所有数据,大量数据的时候,
遍历可能有效率问题。
在下面的装饰器中增加一个参数,需要用到了带参装饰器了。
@mag_cache(5)代表key生存5秒钟后过期。
带参装饰器相当于在原来的装饰器外面再嵌套一层。 清除的时机,何时清除过期key?
1. 用到某个key之前,先判断是否过期,如果过期重新调用函数生成新的key对应value值。
2.一个线程负责清除过期的key,这个后面实现。本次在创建key之前,清除所有过期的key。 value的设计
1.key =>(v,createtimestamp)
适合key过期的时间都是统一的设定
2.key =>(v,createtimestamp,duration)
duration是过期时间,这样每一个key就可以单独控制过期时间。在这种设计中,-1可以表示永不过期,
0可以表示立即过期,正整数表示持续一段时间过期。
这次采用第一种实现!
'''
#题目:实现一个cache装饰器,实现可过期、可自动清除的功能。 from functools import wraps
import time
import inspect
import datetime def cache(duration):
def _cache(fn,):
local_cache = {}
@wraps(fn)
def wrapper(*args,**kwargs):
#local_cache中有没有过期的key
# for k,(_,ts) in local_cache:
# if datetime.datetime.now().timestamp()- ts>5:
# local_cache.pop(k) #不能一边迭代一边删除!
def clear_expire(cache):
expire_key = []
for k, (_, ts) in cache.items():
if datetime.datetime.now().timestamp() - ts > duration:
expire_key.append(k)
for k in expire_key:
cache.pop(k)
clear_expire(local_cache) def make_key():
key_dict = {}
sig = inspect.signature(fn)
params = sig.parameters # 返回一个有序字典
params_list = list(params.keys()) # 返回参数列表
# 位置参数add(5,6,y=8)
for i, v in enumerate(args):
k = params_list[i]
key_dict[k] = v
# 关键字参数
# print('*kwargs', *kwargs)
# for k,v in kwargs.items():
# key_dict[k] = v
key_dict.update(kwargs)
# 缺省值参数
for k in params.keys():
if k not in key_dict.keys():
key_dict[k] = params[k].default
key = tuple(sorted(key_dict.items()))
# print('处理后得到的key:',key)
# print('处理后得到的local_cache:',local_cache)
return key key = make_key() if key not in local_cache.keys():
ret = fn(*args, **kwargs)
local_cache[key] = (ret,datetime.datetime.now().timestamp()) # return local_cache[key]
return wrapper
return _cache def logger(fn):
@wraps(fn)
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)
delta = (datetime.datetime.now() - start).total_seconds()
print(delta)
return ret
return wrapper @logger
@cache(5)
def add(x,y=5):
time.sleep(3)
return x+y add(4)
add(4,5)
add(x=4,y=5)
add(4,y=5)
add(y=5,x=4) time.sleep(5)
print('*'*20)
add(4)
add(4,5)
add(x=4,y=5)
add(4,y=5)
add(y=5,x=4)
#2 题目:写一个命令分发器
"""
1.程序员可以方便的注册函数到某一个命令,用户输入命令时,路由到注册的函数
2.如果此命令没有对应的注册函数,执行默认函数
3.用户输入用input(">>")
"""
'''分析
输入命令映射到一个函数,并执行这个函数。应该是cmd_tbl[cmd]=fn的形式,字典正好合适。
如果输入了某一个cmd命令后,没有找到函数,就要调用缺省的函数执行,这正好是字典缺省参数。
cmd是字符串 实现主要功能后会发现代码布局很丑陋,最好是不要将所有的函数和字典都在全局中定义!
如何改进呢?将reg函数封装成装饰器,并用它来注册函数。 重复注册的问题
如果函数使用同一个函数名注册,就等于覆盖了原来的cmd到fn的关系,这样的逻辑也是合理的。
也可以加一个判断,如果key已经存在,重复注册,抛出异常。看业务需求。 注销
有注册就应该有注销
一般来说注销是要有权限的,但是什么样的人拥有注销的权限。
'''
command_dict = {} #注册(带参装饰器)
def dispatch(): def req(name):
def wrapper(fn):
command_dict[name]=fn
return wrapper def defaultfunc():
print('Unkown command!') def dispatchfunc():
while True:
userinput = input('>>')
if userinput.strip() == 'quit':
return
if userinput in command_dict.keys():
command_dict.get(userinput,defaultfunc)()
else:
defaultfunc()
return req,dispatchfunc req,dispatchfunc = dispatch()
#自定义函数
@req('cy') # f1=req('cy')(f1)
def f1():
print('chengyu')
@req('py')
def f2():
print('python') dispatchfunc()
装饰器的应用

装饰器应用场景

作业

Python进阶3---python类型注解、functools的更多相关文章
- Python进阶09 动态类型
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 谢谢TeaEra, 猫咪cat 动态类型(dynamic typing)是Pyth ...
- python进阶:Python进程、线程、队列、生产者/消费者模式、协程
一.进程和线程的基本理解 1.进程 程序是由指令和数据组成的,编译为二进制格式后在硬盘存储,程序启动的过程是将二进制数据加载进内存,这个启动了的程序就称作进程(可简单理解为进行中的程序).例如打开一个 ...
- python 进阶篇 python 的值传递
值传递和引用传递 值传递,通常就是拷贝参数的值,然后传递给函数里的新变量,这样,原变量和新变量之间互相独立,互不影响. 引用传递,通常是指把参数的引用传给新的变量,这样,原变量和新变量就会指向同一块内 ...
- 第二篇 python进阶
目录 第二篇 python进阶 一 数字类型内置方法 二 字符串类型内置方法 三 列表类型内置方法(list) 四 元组类型内置方法(tuple) 五 字典内置方法 六 集合类型内置方法(self) ...
- 【Python大系】Python快速教程
感谢原作者:Vamei 出处:http://www.cnblogs.com/vamei 怎么能快速地掌握Python?这是和朋友闲聊时谈起的问题. Python包含的内容很多,加上各种标准库.拓展库, ...
- Python3.6引入的f-string 与 Python 3的新的特性:类型注解;
f-string 1.介绍 f-string(formatted string literals):格式化字符串常量,是Python3.6新引入的一种字符串格式化方法,使格式化字符串的操作更加简便. ...
- Python入门篇-类型注解
Python入门篇-类型注解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.函数定义的弊端 1>.动态语言很灵活,但是这种特性也是弊端 Python是动态语言,变量随时可 ...
- Python 3 新特性:类型注解——类似注释吧,反正解释器又不做校验
Python 3 新特性:类型注解 Crossin 上海交通大学 计算机应用技术硕士 95 人赞同了该文章 前几天有同学问到,这个写法是什么意思: def add(x:int, y:int) - ...
- python 类型注解
函数定义的弊端 python 是动态语言,变量随时可以被赋值,且能赋值为不同类型 python 不是静态编译型语言,变量类型是在运行器决定的 动态语言很灵活,但是这种特性也是弊端 def add(x, ...
- Python Type Hint类型注解
原文地址:https://realpython.com/python-type-checking/ 在本指南中,你将了解Python类型检查.传统上,Python解释器以灵活但隐式的方式处理类型.Py ...
随机推荐
- 事件绑定on与hover事件
今天项目中UI设计了一个鼠标划入和划出的效果,本来这个小效果是非常简单的!可是在实际的生产环境中就出现了一点点问题!因为在实际的环境中,数据全部是用ajax异步加载进去的,这样就造成了hover方法不 ...
- Dynamics 365的系统作业实体记录增长太快怎么回事?
摘要: 本人微信公众号:微软动态CRM专家罗勇 ,回复294或者20190111可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me ...
- 12月16日广州.NET俱乐部下午4点爬白云山活动
正如我们在<广州.NET微软技术俱乐部与其他技术群的区别>和<广州.NET微软技术俱乐部每周三五晚周日下午爬白云山活动>里面提到的, 我们会在每周三五晚和周日下午爬白云山. ...
- CentOS 7安装指南
CentOS 7安装指南(U盘版) 一.准备阶段 1.下载CentOS7镜像文件(ISO文件)到自己电脑,官网下载路径: http://isoredirect.centos.org/centos/7/ ...
- 从.Net到Java学习第五篇——Spring Boot &&Profile &&Swagger2
从.Net到Java学习系列目录 刚学java不久,我有个疑问,为何用到的各种java开源jar包许多都是阿里巴巴的开源项目,为何几乎很少见百度和腾讯?不是说好的BAT吗? Spring Boot 的 ...
- C++ 虹软人脸识别 ArcFace 2.0 Demo
环境配置: 开发环境:Win10 + VS 2013 SDK版本:ArcFace v2.0 OpenCV版本:2.4.9 平台配置: x64.x86下Release.Debug SDK 下载地址:戳这 ...
- spring学习总结——高级装配学习四(运行时:值注入、spring表达式)
前言: 当讨论依赖注入的时候,我们通常所讨论的是将一个bean引用注入到另一个bean的属性或构造器参数中.bean装配的另外一个方面指的是将一个值注入到bean的属性或者构造器参数中.在没有学习使用 ...
- linux(centos7) 常用命令和快捷键 持续验证更新中...
1.文件和目录cd 进入目录示例:cd /home 进入home目录 cd.. 返回上一级目录cd../.. 返回上两级目录cd - 返回上次所在目录cd ~ 返回根目录 ...
- The account that is running SQL Server Setup does not have one or all of the following rights: the right to back up files and directories, the right to manage auditing and the security log and the rig
安装SQL SERVER 是规则检查提示权限问题 运行secpol.msc,没有Debug program权限,添加即可,如果已加域则要在域策略修改,或退域安装后在加域.
- 搭建一个dubbo+zookeeper平台
本篇主要是来分享从头开始搭建一个dubbo+zookeeper平台的过程,其中会简要介绍下dubbo服务的作用. 首先,看下一般网站架构随着业务的发展,逻辑越来越复杂,数据量越来越大,交互越来越多之后 ...