JDK源码分析(4)之 LinkedList 相关
LinkedList的源码大致分三个部分,双向循环链表的实现、List的API和Deque的API。
一、定义
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
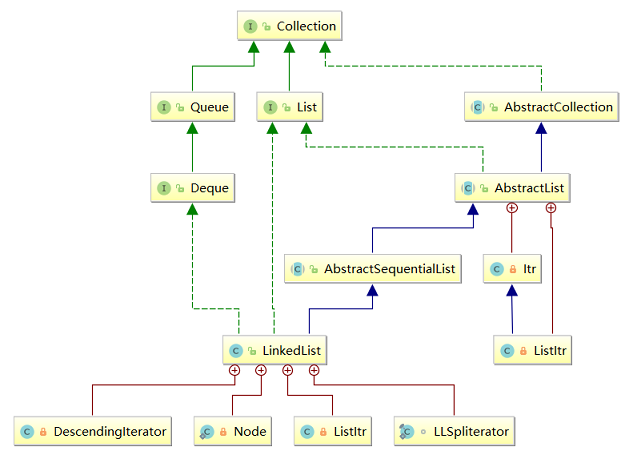
从类定义和图中也能很清晰的看到,LinkedList的结构大致分为三个部分;同时和ArrayList相比,他并没有实现RandomAccess接口,所以他并不支持随机访问操作;另外可以看到他的List接口是通过AbstractSequentialList实现的,同时还实现了多个迭代器,表明他的访问操作时通过迭代器完成的。
二、链表结构
常见链表
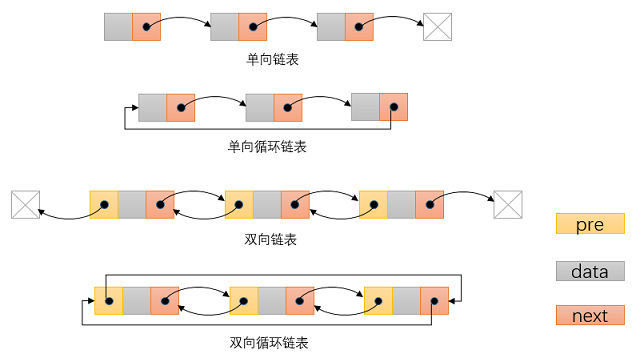
LinkedList是基于双向循环链表实现的,所以如图所示,当对链表进行插入、删除等操作时,
- 首先需要区分操作节点是否为首尾节点,并区分是否为空,
- 然后再变更相应
pre和next的引用即可;
void linkFirst(E e)
void linkLast(E e)
void linkBefore(E e, Node<E> succ)
E unlinkFirst(Node<E> f)
E unlinkLast(Node<E> l)
E unlink(Node<E> x)
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
上面所列的方法封装了对双向循环链表常用操作,其中node(int index)是随机查询方法,这里通过判断index是前半段还是后半段,来确定遍历的方向以增加效率。
同时在LinkedList中有关List和Deque的API也是基于上面的封装的方法完成的。具体代码比较简单,就不挨着分析了。
三、序列化和反序列化
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
可以看到LinkedList的成员变量都是用transient修饰的,那么在序列化的时候,他是怎么将包含的dada序列化的呢?
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject();
// Write out size
s.writeInt(size);
// Write out all elements in the proper order.
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item);
}
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject();
// Read in size
int size = s.readInt();
// Read in all elements in the proper order.
for (int i = 0; i < size; i++)
linkLast((E)s.readObject());
}
可以看到序列化的时候是将size和node中的data提取出来,放入java.io.ObjectInputStream,这样就避免了很多结构性的数据传输。
四、遍历
关于LinkedList的遍历这里有一个经常都会踩的坑需要注意一下。
- 随机访问
for (int i=0, len = list.size(); i < len; i++) {
String s = list.get(i);
}
- 迭代器遍历
Iterator iter = list.iterator();
while (iter.hasNext()) {
String s = (String)iter.next();
}
- 增强for循环遍历
for (String s : list) {
...
}
- 效率测试
对一个LinkedList做顺序遍历:
| 1000 | 10000 | 100000 | 200000 | |
|---|---|---|---|---|
| 随机访问 | 2 | 101 | 13805 | 105930 |
| 增强for循环 | 1 | 1 | 3 | 3 |
| 迭代器 | 1 | 1 | 3 | 3 |
这里可以明显的看增强for循环和迭代器的效率差不多,这是因为增强for循环也是通过迭代器实现的,具体可以查看我在ArrayList章节的分析;但是随机访问的方式遍历,耗时在急剧增加,这是为什么呢?
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
这里可以看到get(int index)是使用node(int index)实现的,所以对于迭代器和增强for循环遍历时间复杂度是O(n),而使用随机访问的方式遍历时间复杂度则是O(n*n);所以在对LinkedList遍历的时候一定不能采用随机访问的方式。建议直接使用增强for循环遍历,如果一定要使用随机访问则需要判断是否实现RandomAccess接口。
五、插入和删除
网上一般都在说LinkedList比ArrayList的插入和删除快,因为ArryList基于数组,需要移动后续元素,而LinkedList则只需要修改两条引用;但是实际如何呢?
private static final Random RANDOM = new Random();
private static List<String> getList(List<String> list, int n) {
for (int i = 0; i < n; i++) {
list.add("a" + i);
}
return list;
}
private static long test(List<String> list, int count) {
long start = System.currentTimeMillis();
for (int i = 0; i < count; i++) {
list.add(RANDOM.nextInt(list.size()), i + "");
list.remove(RANDOM.nextInt(list.size()));
}
return System.currentTimeMillis() - start;
}
public static void main(String[] args) {
int[] tt = {1000, 10000, 50000};
for (int t : tt) {
List<String> linked = getList(new LinkedList<>(), t);
List<String> array = getList(new ArrayList<>(), t);
System.out.println("------------" + t);
System.out.println("--linked: " + test(linked, t));
System.out.println("--array:" + test(array, t));
}
}
这里只是简单测试一下,如果需要精确结果可以使用JMH基准测试,
这里是对长度为 n 的 List,进行随机插入和删除 n 次,结果如下:
| 1000 | 10000 | 50000 | |
|---|---|---|---|
| LinkedList | 6 | 502 | 18379 |
| ArrayList | 2 | 9 | 202 |
如果只是在 List 的首尾插入和删除呢,测试结果如下:
| 1000 | 10000 | 50000 | |
|---|---|---|---|
| LinkedList | 1 | 4 | 9 |
| ArrayList | 2 | 11 | 200 |
根据测试结果:
对于随机插入和删除,
LinkedList效率低于ArrayList;主要是因为LinkedList遍历定位的时候比较慢,而ArrayList是基于数组,可以通过偏移量直接定位,并且ArrayList在插入和删除时,移动数组是通过System.arraycopy完成的,jvm 有做特殊优化,效率比较高。对于首尾的插入和删除,
LinkedList效率高于ArrayList,这里因为LinkedList只需要插入删除一个节点就可以,但ArrayList需要移动数组,同时可能还需要扩容操作,所以比较慢。
总结
- LinkedList 基于双向循环链表实现,随机访问比较慢,所以在遍历 List 的时候一定要注意。
- LinkedList 可以添加重复元素,可以添加 null。
JDK源码分析(4)之 LinkedList 相关的更多相关文章
- JDK源码分析(三)—— LinkedList
参考文档 JDK源码分析(4)之 LinkedList 相关
- JDK源码分析(2)LinkedList
JDK版本 LinkedList简介 LinkedList 是一个继承于AbstractSequentialList的双向链表.它也可以被当作堆栈.队列或双端队列进行操作. LinkedList 实现 ...
- JDK源码分析(一)—— String
dir 参考文档 JDK源码分析(1)之 String 相关
- 【JDK】JDK源码分析-HashMap(1)
概述 HashMap 是 Java 开发中最常用的容器类之一,也是面试的常客.它其实就是前文「数据结构与算法笔记(二)」中「散列表」的实现,处理散列冲突用的是“链表法”,并且在 JDK 1.8 做了优 ...
- 【JDK】JDK源码分析-TreeMap(2)
前文「JDK源码分析-TreeMap(1)」分析了 TreeMap 的一些方法,本文分析其中的增删方法.这也是红黑树插入和删除节点的操作,由于相对复杂,因此单独进行分析. 插入操作 该操作其实就是红黑 ...
- 【JDK】JDK源码分析-Vector
概述 上文「JDK源码分析-ArrayList」主要分析了 ArrayList 的实现原理.本文分析 List 接口的另一个实现类:Vector. Vector 的内部实现与 ArrayList 类似 ...
- 【JDK】JDK源码分析-List, Iterator, ListIterator
List 是最常用的容器之一.之前提到过,分析源码时,优先分析接口的源码,因此这里先从 List 接口分析.List 方法列表如下: 由于上文「JDK源码分析-Collection」已对 Collec ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(2)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(1)」初步分析了 AQS,其中提到了 Node 节点的「独占模式」和「共享模式」,其实 AQS 也主要是围绕对这两种模 ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(3)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(2)」分析了 AQS 在独占模式下获取资源的流程,本文分析共享模式下的相关操作. 其实二者的操作大部分是类似的,理解了 ...
- 【JDK】JDK源码分析-ReentrantLock
概述 在 JDK 1.5 以前,锁的实现只能用 synchronized 关键字:1.5 开始提供了 ReentrantLock,它是 API 层面的锁.先看下 ReentrantLock 的类签名以 ...
随机推荐
- github-新建文件夹
1,进入仓库“ sstruggle.github.io ”中,在该仓库页面中找到“ Create new file ”,如图: 2,在创建新文件页面,输入“ js/ ”,github默认为是一个文件夹 ...
- jquery固定表头和列头
1.对网上的开源方法稍作了些修改 <script type="text/javascript">// <![CDATA[ function FixTable(Ta ...
- springboot项目打包
使用IDEA或Eclipse的插件创建springboot项目的时候可以选择打包方式,一般情况下都是选择的jar包. 当想将原来的jar包格式的项目打成war包在本地tomcat下运行时可以通过以下几 ...
- hadoop2-HBase的Java API操作
Hbase提供了丰富的Java API,以及线程池操作,下面我用线程池来展示一下使用Java API操作Hbase. 项目结构如下: 我使用的Hbase的版本是 hbase-0.98.9-hadoop ...
- ES6的Module 的用法
在vue-cli中遇到的模糊参考 https://www.cnblogs.com/ppJuan/p/7151000.html 解决问题: 在 ES6 之前,社区制定了一些模块加载方案,最主要的有 Co ...
- Spring源码学习-容器BeanFactory(三) BeanDefinition的创建-解析Spring的默认标签
写在前面 上文Spring源码学习-容器BeanFactory(二) BeanDefinition的创建-解析前BeanDefinition的前置操作中Spring对XML解析后创建了对应的Docum ...
- 使用datagrip链接mysql数据库的报错问题.
1. datagrip刚打开时候,选择风格是白是黑后, 会有一个选择什么数据库,有oracle...一大堆,别选错了.我的是mysql,不要选成了windows sql 和sql. 2 基本设置写完, ...
- 关于实体类getset方法首字母小写问题
实体类:private Date cDateTime;private String cNickname; public Date getcDateTime() { return cDateTime;} ...
- win 10 亮度调节不能使用了
我的解决办法的前提:装过teamviewer ,然后每次系统推送大升级似乎都会无法调节亮度,如果不是这个前提自己找别的办法吧 teamviewer 就是一个流氓软件. 每次更新之后都末名奇妙的不能调节 ...
- ubuntu 16.04卸载不必要默认安装软件
两个办法,一个在ubuntu软件里一个一个删,明显的windows下做法. 还有一个通过终端来删除.ctrl+alt+t打开终端. 1.卸载libreoffices(要删一起删了,然后去装office ...