sklearn 中 make_blobs模块
# 生成用于聚类的各向同性高斯blob
sklearn.datasets.make_blobs(n_samples = 100,n_features = 2,center = 3,cluster_std = 1.0,center_box =( - 10.0,10.0),shuffle = True,random_state = None)
参数
n_samples: int, optional (default=100)
待生成的样本的总数。
n_features: int, optional (default=2)
每个样本的特征数。
centers: int or array of shape [n_centers, n_features], optional (default=3)
要生成的样本中心(类别)数,或者是确定的中心点。
cluster_std: float or sequence of floats, optional (default=1.0)
每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]。
center_box: pair of floats (min, max), optional (default=(-10.0, 10.0))
中心随机生成时每个聚类中心的边界框。
shuffle:布尔值,可选(默认= True)
对样本进行随机播放。
random_state:int,RandomState实例或None,可选(default = None)
如果为int,random_state是随机数生成器使用的种子; 如果RandomState实例,random_state是随机数生成器; 如果为None,则随机数生成器是np.random使用的RandomState实例。
返回
X : array of shape [n_samples, n_features]
生成的样本数据集。
y : array of shape [n_samples]
样本数据集的标签。
例子
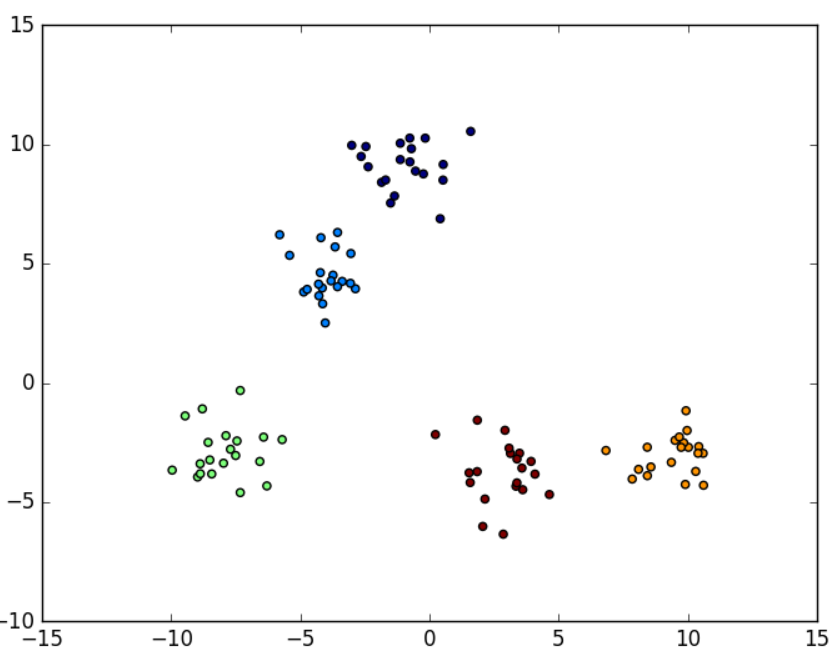
例如要生成5类数据(100个样本,每个样本有2个特征),代码如下
from sklearn.datasets import make_blobs
from matplotlib import pyplot data, label = make_blobs(n_samples=100, n_features=2, centers=5)
# 绘制样本显示
pyplot.scatter(data[:, 0], data[:, 1], c=label)
pyplot.show()
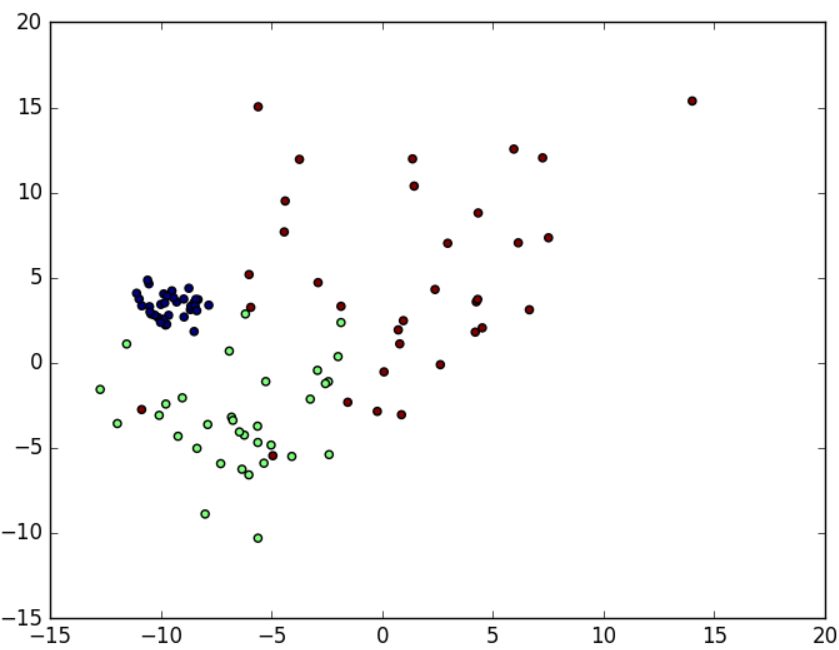
如果希望为每个类别设置不同的方差,需要在上述代码中加入cluster_std参数:
from sklearn.datasets import make_blobs
from matplotlib import pyplot data, label = make_blobs(n_samples=10, n_features=2, centers=3, cluster_std=[0.8, 2.5, 4.5])
# 绘制样本显示
pyplot.scatter(data[:, 0], data[:, 1], c=label)
pyplot.show()
sklearn 中 make_blobs模块的更多相关文章
- sklearn 中 make_blobs模块使用
sklearn.datasets.make_blobs(n_samples=100, n_features=2, centers=3, cluster_std=1.0, center_box=(-10 ...
- 【集成学习】sklearn中xgboost模块的XGBClassifier函数
# 常规参数 booster gbtree 树模型做为基分类器(默认) gbliner 线性模型做为基分类器 silent silent=0时,不输出中间过程(默认) silent=1时,输出中间过程 ...
- 【集成学习】sklearn中xgboost模块中plot_importance函数(绘图--特征重要性)
直接上代码,简单 # -*- coding: utf-8 -*- """ ################################################ ...
- sklearn中xgboost模块中plot_importance函数(特征重要性)
# -*- coding: utf-8 -*- """ ######################################################### ...
- 【集成学习】sklearn中xgboot模块中fit函数参数详解(fit model for train data)
参数解释,后续补上. # -*- coding: utf-8 -*- """ ############################################## ...
- sklearn中的metrics模块中的Classification metrics
metrics是sklearn用来做模型评估的重要模块,提供了各种评估度量,现在自己整理如下: 一.通用的用法:Common cases: predefined values 1.1 sklearn官 ...
- python中导入sklearn中模块提示ImportError: DLL load failed: 找不到指定的程序。
python版本:3.7 平台:windows 10 集成环境:Anaconda3.7 64位 在jupyter notebook中导入sklearn的相关模块提示ImportError: DLL l ...
- sklearn中的KMeans算法
1.聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇).这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布. 2.KMeans算法将一 ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
随机推荐
- LeetCode OJ:Combination Sum (组合之和)
Given a set of candidate numbers (C) and a target number (T), find all unique combinations in C wher ...
- 条款21:必须返回对象的时候,不要妄想使其返回reference
//先看看下面这个例子 class Rational{ public: Rational(int num, int denu) :numirator(num), denumirator(denu); ...
- DRF 中 解决跨域 与 预检
DRF 中 解决跨域 与 预检 1 跨域 浏览器的同源策略: 对ajax请求进行阻拦 ps: 对href src属性 不限制 只有浏览器会阻止,requests模块不会存在跨域 (1)解决方案1 JS ...
- my vim IDE 编辑器的配置
<h4>1.自定义编辑.vimrc的快捷键</h4><blockquote>"Set mapleaderlet mapleader = ",&q ...
- 使用Audition录制自己的歌曲
Audition专为在照相室.广播设备和后期制作设备方面工作的音频和视频专业人员设计,可提供先进的音频混合.编辑.控制和效果处理功能.最多混合 128 个声道,可编辑单个音频文件,创建回路并可使用 4 ...
- wlan接收器如何共享网络
无线局域网络(Wireless Local Area Networks: WLAN)是相当便利的数据传输系统,它利用射频(Radio Frequency: RF)的技术,取代旧式碍手碍脚的双绞铜线(C ...
- CentOS虚拟机中安装VMWare Tools
1.单击VMWare的[虚拟机]菜单,选择[安装VMWare Tools]命令 2.接着CentOS系统会自动挂载VMWare Tools,并自动打开,如果没有打开可以自己去图形界面打开VMWare ...
- angular中的 input select 值绑定无效,以及多出一个空白选项问题
问题: <!-- 问题标签 --> <select ng-model="sortType"> <option value="1"& ...
- 谷歌设置支持webgl
浏览器报错: could not initialize WebGl 因为谷歌默认不支持WebGl 在浏览器器中输入 about:flags 然后开启:覆盖软件渲染列表,覆盖内置的软件渲染列表,并对不支 ...
- JUnit测试,获取Spring MVC环境
@RunWith(SpringJUnit4ClassRunner.class) @WebAppConfiguration @ContextConfiguration(locations = { &qu ...