hadoop文件写入
转:http://blog.csdn.net/xiaoshunzi111/article/details/48198105

由上图可知;写入文件分为三个角色,分别是clientnode namenode 和datanode
cliennode本质为java虚拟机.namenode 和datanode则是Hadoop数据集群存储块
第一步:create实际是客户端创建DistributedFileSystem实例化对象
第二步 create通过实例化对象录取调用对象中create()方法,此方法访问namenode,namenode收到命令,首先判断datanode中所写的文件是否有重复,然后在检查namenode是否有可写入空余的空间.当二者同时满足是,namenode写将datanode路径信息,文件数等记录,并确认信息返回DistributedFileSystem,否则返回异常,DistributedFileSystem收到确认信息后向客户端返回一个FSDataOutputStream FSDataOutputStream对象
第三步:实例化FSDataOutputStream对象(该对象负责处理 datanode 和 namenode 之间的通信 ),调用该对象的write()方法, 即是图中write实现过程该对象负责处理 datanode 和 namenode 之间的通信
第四步:方法将数据分成多个数据包,并写入内部队列. DFDataOutStream 将写入的数据分成多个数据包,并写入内部队列中,同时开启datanode中DataStreamer处理数据队列,它负责根据datanode列来要求namenode分配合适的新块存储数据备份开启管道机制依次执行步骤4,同时即是write packet完整过程
第五步:每执行一次4就有一次步骤5返回确认信息.
4和5属于分别在DataQueue队列和ACKQueue队列,当每执行一次4就将此步确认信息放到ACKQueue队列中
如图:
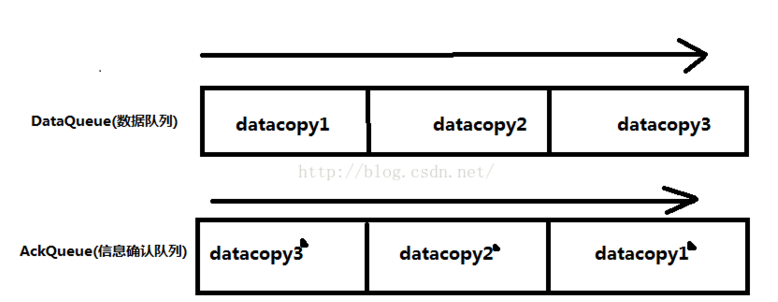
第六步:当FSDataOutputStream收到确认信息后,执行close()方法关闭输出流,
第七步:DistributeFileStream 返回给namenode确认信息.
注释:第4-5部分实现在后台完成步不一定在第七步之前,
当执行第四步就就收第5步确认信息,告诉namenode 数据写入成功,即是第七步.
hadoop文件写入的更多相关文章
- Hadoop学习笔记(3) Hadoop文件系统一
1. 分布式文件系统,即为管理网络中跨多台计算机存储的文件系统.HDFS以流式数据访问模式来存储超大文件,运行于商用硬件集群上.HDFS的构建思路为:一次写入.多次读取是最高效的访问模式.数据集通常由 ...
- hdfs文件写入kafka集群
1. 场景描述 因新增Kafka集群,需要将hdfs文件写入到新增的Kafka集群中,后来发现文件不多,就直接下载文件到本地,通过Main函数写入了,假如需要部署到服务器上执行,需将文件读取这块稍做修 ...
- Java文件写入,换行
import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.io.IOExce ...
- 视频文件写入转换之图像处理-OpenCV应用学习笔记五
在<笔记二>中我们做了视频播放和控制的实现,仅仅算是完成了对视频文件的读取操作:今天我们来一起练习下对视频文件的写入操作:格式转换. 实现功能: 打开一个视频文件play.avi,读取文件 ...
- Python学习笔记——文件写入和读取
1.文件写入 #coding:utf-8 #!/usr/bin/env python 'makeTextPyhton.py -- create text file' import os ls = os ...
- Sqli-LABS通关笔录-7[文件写入函数Outfile]
该关卡最主要的就是想要我们学习到Outfile函数(文件写入函数)的使用. 通过源代码我们很容易的写出了payload.倘若我们一个个去尝试的话,说实话,不容易. http://127.0.0.1/s ...
- 将gridFS中的图片文件写入硬盘
开启用户验证下的gridfs 连接使用,在执行脚本前可以在python shell中 from pymongo import Connectionfrom gridfs import *con = C ...
- PHP文件读写操作之文件写入代码
在PHP网站开发中,存储数据通常有两种方式,一种以文本文件方式存储,比如txt文件,一种是以数据库方式存储,比如Mysql,相对于数据库存储,文件存储并没有什么优势,但是文件读写操作在基本的PHP开发 ...
- Java学习-018-EXCEL 文件写入实例源代码
众所周知,EXCEL 也是软件测试开发过程中,常用的数据文件导入导出时的类型文件之一,此文主要讲述如何通过 EXCEL 文件中 Sheet 的索引(index)或者 Sheet 名称获取文件中对应 S ...
随机推荐
- flask_sqlalchemy + sqlite 的一系列使用方法
如何使用在官网上有详细记录 :http://flask-sqlalchemy.pocoo.org/2.3/ 作为项目笔记,简单阐述使用方法: 1.创建flask_sqlalchemy基于sqlite的 ...
- 广义线性模型(GLM)
一.广义线性模型概念 在讨论广义线性模型之前,先回顾一下基本线性模型,也就是线性回归. 在线性回归模型中的假设中,有两点需要提出: (1)假设因变量服从高斯分布:$Y={{\theta }^{T}}x ...
- About toupper()
// toupper.c #include <stdio.h> #include <string.h> #include <ctype.h> int main() ...
- linux时间管理 之 jiffies
1.jiffies 又称时钟滴答,是一个全局变量,它的值在系统引导的时候初始化为0,在时钟中断初始化完成后,每次时钟中断发生,在时钟中断处理例程中都会将jiffies的值 +1. jiffies_64 ...
- [置顶]
kubernetes1.7新特性:新增StorageOS卷插件和Local持久存储
背景介绍 在Kubernetes中卷的作用在于提供给POD存储,这些存储可以挂载到POD中的容器上,进而给容器提供存储. 从图中可以看到结构体PodSpec有个属性是Volumes,通过这个Volum ...
- [置顶]
关于Android实现 退出登录那些小事?
使用场景: 相信大家应该清楚每一个app都会有一个"退出登陆"的功能,有的可能在个人中心有的在设置里面.当用户点击退出之后需要将所有的Activity都finish掉,开始是想将栈 ...
- C#调用EasyPusher推送到EasyDarwin实现视频流中转
本文转自:http://www.cnblogs.com/kangkey/p/6772863.html 最近在公司项目中,遇到需要将内网的监控视频信息,在外网进行查看,最终通过查阅资料,发现EasyDa ...
- FireMonkey Premium Style Pack 2 for RAD Studio XE4
FireMonkey Premium Style Pack 2 for RAD Studio XE4 http://cc.embarcadero.com/item/29483 http://www.e ...
- struct 字节对齐详解
一.什么是字节对齐,为什么要对齐? 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特 定的内存地址访问, ...
- Ubantu 新建用户后没有生成对应文件夹
原命令:useradd python 改正后:useradd python -m 后成功在home目录下创建文件夹 原因: man useradd就可以看到如此介绍:Create the user´s ...