Consul实现原理系列文章2: 用Gossip来做集群成员管理和消息广播
工作中用到了Consul来做服务发现,之后一段时间里,我会陆续发一些文章来讲述Consul实现原理。这篇文章会讲述Consul是如何使用Gossip来做集群成员管理和消息广播的。
Consul使用Gossip协议来管理集群中的成员关系,以及把消息广播到集群中。而这些Gossip的特性是利用Serf这个lib来实现的。
下面,我们先来看看什么是Gossip协议。
Gossip协议
在学习Gossip的过程中,我找到了一篇介绍Gossip的很不错的文章,下面是那篇文章的主要内容:
( 以下转载自http://blog.csdn.net/chen77716/article/details/6275762):
Gossip背景
Gossip算法如其名,灵感来自办公室八卦,只要一个人八卦一下,在有限的时间内所有的人都会知道该八卦的信息,这种方式也与病毒传播类似,因此Gossip有众多的别名“闲话算法”、“疫情传播算法”、“病毒感染算法”、“谣言传播算法”。
但Gossip并不是一个新东西,之前的泛洪查找、路由算法都归属于这个范畴,不同的是Gossip给这类算法提供了明确的语义、具体实施方法及收敛性证明。
Gossip特点
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。
要注意到的一点是,即使有的节点因宕机而重启,有新节点加入,但经过一段时间后,这些节点的状态也会与其他节点达成一致,也就是说,Gossip天然具有分布式容错的优点。
Gossip本质
Gossip是一个带冗余的容错算法,更进一步,Gossip是一个最终一致性算法。虽然无法保证在某个时刻所有节点状态一致,但可以保证在”最终“所有节点一致,”最终“是一个现实中存在,但理论上无法证明的时间点。
因为Gossip不要求节点知道所有其他节点,因此又具有去中心化的特点,节点之间完全对等,不需要任何的中心节点。实际上Gossip可以用于众多能接受“最终一致性”的领域:失败检测、路由同步、Pub/Sub、动态负载均衡。
但Gossip的缺点也很明显,冗余通信会对网路带宽、CUP资源造成很大的负载,而这些负载又受限于通信频率,该频率又影响着算法收敛的速度,后面我们会讲在各种场合下的优化方法。
Gossip节点的通信方式及收敛性
根据原论文,两个节点(A、B)之间存在三种通信方式:
- push: A节点将数据(key,value,version)及对应的版本号推送给B节点,B节点更新A中比自己新的数据
- pull:A仅将数据key,version推送给B,B将本地比A新的数据(Key,value,version)推送给A,A更新本地
- push/pull:与pull类似,只是多了一步,A再将本地比B新的数据推送给B,B更新本地
如果把两个节点数据同步一次定义为一个周期,则在一个周期内,push需通信1次,pull需2次,push/pull则需3次,从效果上来讲,push/pull最好,理论上一个周期内可以使两个节点完全一致。直观上也感觉,push/pull的收敛速度是最快的。
假设每个节点通信周期都能选择(感染)一个新节点,则Gossip算法退化为一个二分查找过程,每个周期构成一个平衡二叉树,收敛速度为O(n2 ),对应的时间开销则为O(logn )。这也是Gossip理论上最优的收敛速度。
但在实际情况中最优收敛速度是很难达到的,假设某个节点在第i个周期被感染的概率为pi ,第i+1个周期被感染的概率为pi+1 ,则pull的方式: 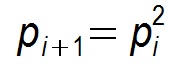
而push为: 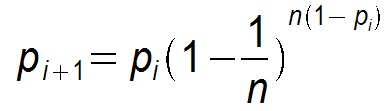
显然pull的收敛速度大于push,而每个节点在每个周期被感染的概率都是固定的
p(0< p <1),因此Gossip算法是基于p的平方收敛,也成为概率收敛,这在众多的一致性算法中是非常独特的。
Gossip的节点的工作方式又分两种:
- Anti-Entropy(反熵):以固定的概率传播所有的数据
- Rumor-Mongering(谣言传播):仅传播新到达的数据
Anti-Entropy模式有完全的容错性,但有较大的网络、CPU负载;Rumor-Mongering模式有较小的网络、CPU负载,但必须为数据定义”最新“的边界,并且难以保证完全容错,对失败重启且超过”最新“期限的节点,无法保证最终一致性,或需要引入额外的机制处理不一致性。我们后续着重讨论Anti-Entropy模式的优化。
Anti-Entropy的协调机制
协调机制是讨论在每次2个节点通信时,如何交换数据能达到最快的一致性,也即消除两个节点的不一致性。上面所讲的push、pull等是通信方式,协调是在通信方式下的数据交换机制。
协调所面临的最大问题是,因为受限于网络负载,不可能每次都把一个节点上的数据发送给另外一个节点,也即每个Gossip的消息大小都有上限。在有限的空间上有效率地交换所有的消息是协调要解决的主要问题。
在讨论之前先声明几个概念:
令N = {p,q,s,…}为需要gossip通信的server集合,有界大小
令(p1,p2,…)是宿主在节点p上的数据,其中数据有(key,value,version)构成,q的规则与p类似。
为了保证一致性,规定数据的value及version只有宿主节点才能修改,其他节点只能间接通过Gossip协议来请求数据对应的宿主节点修改。
精确协调(Precise Reconciliation)
精确协调希望在每次通信周期内都非常准确地消除双方的不一致性,具体表现为相互发送对方需要更新的数据,因为每个节点都在并发与多个节点通信,理论上精确协调很难做到。
精确协调需要给每个数据项独立地维护自己的version,在每次交互是把所有的(key,value,version)发送到目标进行比对,从而找出双方不同之处从而更新。但因为Gossip消息存在大小限制,因此每次选择发送哪些数据就成了问题。当然可以随机选择一部分数据,也可确定性的选择数据。对确定性的选择而言,可以有最老优先(根据版本)和最新优先两种,最老优先会优先更新版本最新的数据,而最新更新正好相反,这样会造成老数据始终得不到机会更新,也即饥饿。
当然,开发者也可根据业务场景构造自己的选择算法,但始终都无法避免消息量过多的问题。
整体协调(Scuttlebutt Reconciliation)
整体协调与精确协调不同之处是,整体协调不是为每个数据都维护单独的版本号,而是为每个节点上的宿主数据维护统一的version。
比如节点P会为(p1,p2,…)维护一个一致的全局version,相当于把所有的宿主数据看作一个整体,当与其他节点进行比较时,只需必须这些宿主数据的最高version,如果最高version相同说明这部分数据全部一致,否则再进行精确协调。
整体协调对数据的选择也有两种方法:
- 广度优先:根据整体version大小排序,也称为公平选择
- 深度优先:根据包含数据多少的排序,也称为非公平选择。
因为后者更有实用价值,所以原论文更鼓励后者
Consul中的Gossip
Consul用了两种不同的Gossip池。我们把这两种池分别叫做LAN池和WAN池。
LAN池
Consul中的每个数据中心有一个LAN池,它包含了这个数据中心的所有成员,包括clients和servers。LAN池用于以下几个目的:
- 成员关系信息允许client自动发现server, 减少了所需要的配置量。
- 分布式失败检测机制使得由整个集群来做失败检测这件事, 而不是集中到几台机器上。
- gossip池使得类似领导人选举这样的事件变得可靠而且迅速。
WAN池
WAN池是全局唯一的,因为所有的server都应该加入到WAN池中,无论它位于哪个数据中心。由WAN池提供的成员关系信息允许server做一些跨数据中心的请求。一体化的失败检测机制允许Consul优雅地去处理:整个数据中心失去连接, 或者仅仅是别的数据中心的某一台失去了连接。
所有的这些特性都是利用Serf来提供的。Consul中内嵌了Serf这个lib。
参考资料
Consul实现原理系列文章2: 用Gossip来做集群成员管理和消息广播的更多相关文章
- Consul实现原理系列文章3: Consul的整体架构
工作中用到了Consul来做服务发现,之后一段时间里,我会陆续发一些文章来讲述Consul实现原理.在前几篇文章介绍完了Consul用到的两个关键性东西Raft和Gossip之后,这篇文章会讲述Con ...
- Consul实现原理系列文章1: 用Raft来实现分布式一致性
工作中用到了Consul来做服务发现,之后一段时间里,我会陆续发一些文章来讲述Consul实现原理.在前一篇文章中,我介绍了Raft算法.这篇文章会讲讲Consul是如何使用Raft算法来实现分布式一 ...
- 彻底搞懂 etcd 系列文章(三):etcd 集群运维部署
0 专辑概述 etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管.etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册与发现,还可以作为 key-value 存储的中间件 ...
- MapReduce调度与执行原理系列文章
转自:http://blog.csdn.net/jaytalent?viewmode=contents MapReduce调度与执行原理系列文章 一.MapReduce调度与执行原理之作业提交 二.M ...
- FastDFS原理系列文章
FastDFS原理系列文章 基于FastDFS 5.03/5.04 2014-12-19 一.概述 FastDFS文档极少,仅仅能找到一些宽泛的架构文档,以及ChinaUnix论坛上作者对网友提问的一 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- springCloud系列教程01:Eureka 注册中心集群搭建
springCloud系列教程包含如下内容: springCloud系列教程01:Eureka 注册中心集群搭建 springCloud系列教程02:ConfigServer 配置中心server搭建 ...
- RabbitMQ学习系列(六): RabbitMQ 高可用集群
前面讲过一些RabbitMQ的安装和用法,也说了说RabbitMQ在一般的业务场景下如何使用.不知道的可以看我前面的博客,http://www.cnblogs.com/zhangweizhong/ca ...
随机推荐
- iOS开发笔记_4自定义TabBar
新博客:http://www.liuchendi.com 好多APP都使用的是自定义的TabBar,那这个功能应该如何实现呢?首先应该解决的问题就是,加载NavigationController的时候 ...
- Merge的山寨版“联机帮助”
IF NOT OBJECT_ID('Demo_AllProducts') IS NULL DROP TABLE Demo_AllProducts GO CREATE TABLE Demo_AllPro ...
- Javascript高级程序设计 -- 第三章 -- 总结
1.Javascript有几种数据类型 2.变量 Javascript有几种数据类型 JavaScript中有5种简单数据类型(也称为基本数据类型):Undefined.Null.Boolean.Nu ...
- iOS:Masonry介绍与使用
Masonry介绍与使用实践:快速上手Autolayout frame----->autoresing------->autoLayout-------->sizeClasses ...
- eclipse里面配置spring,提示java.lang.ClassNotFoundException:org.springframework.web.servlet.Dispatcher错误
在eclipse里面创建了一个Dynamic 项目,用到spring,一直提示java.lang.ClassNotFoundException: org.springframework.web.ser ...
- 从C转到JAVA学习路之struct与class对比(转)
转自:http://blog.csdn.net/andywxf01/article/details/53506549 JAVA里最牛B的最基本的就是类,而C语言中的struct也可以定义自己的数据结构 ...
- [Javascript] Use a Pure RNG with the State ADT to Select an Element from State
The resultant in a State ADT instance can be used as a means of communication between different stat ...
- POJ 3083:Children of the Candy Corn(DFS+BFS)
Children of the Candy Corn Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 9311 Accepted: ...
- B2:观察者模式 Observer
定义了一种一对多的依赖关系,多个观察者对象同时监听某一主题的变化,这个主题对象在状态发生变化时,会通知所有观察者对象,使它们可以更新自己. 应用场景:某个实例的变化影响到了其他对象. UML: 示例代 ...
- mysqli 预处理语句
预处理语句用于执行多个相同的 SQL 语句,并且执行效率更高. <?php // 设置编码格式 header('content-type:text/html;charset=utf-8'); / ...