5 Things You Should Know About the New Maxwell GPU Architecture
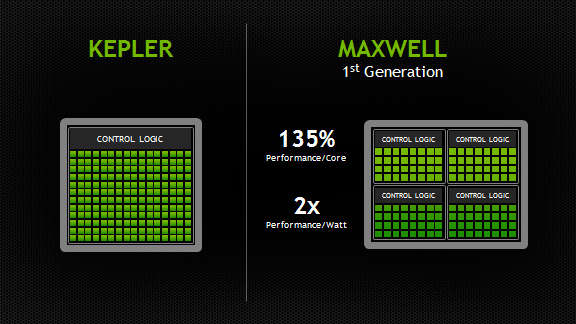
The introduction this week of NVIDIA’s first-generation “Maxwell” GPUs is a very exciting moment for GPU computing. These first Maxwell products, such as the GeForce GTX 750 Ti, are based on the GM107 GPU and are designed for use in low-power environments such as notebooks and small form factor computers. What is exciting about this announcement for HPC and other GPU computing developers is the great leap in energy efficiency that Maxwell provides: nearly twice that of the Kepler GPU architecture.
This post will tell you five things that you need to know about Maxwell as a GPU computing programmer, including high-level benefits of the architecture, specifics of the new Maxwell multiprocessor, guidance on tuning and pointers to more resources.
1. The Heart of Maxwell: More Efficient Multiprocessors
Maxwell introduces an all-new design for the Streaming Multiprocessor (SM) that dramatically improves power efficiency. Although the Kepler SMX design was extremely efficient for its generation, through its development NVIDIA’s GPU architects saw an opportunity for another big leap forward in architectural efficiency; the Maxwell SM is the realization of that vision. Improvements to control logic partitioning, workload balancing, clock-gating granularity, instruction scheduling, number of instructions issued per clock cycle, and many other enhancements allow the Maxwell SM (also called “SMM”) to far exceed Kepler SMX efficiency. The new Maxwell SM architecture enabled us to increase the number of SMs to five in GM107, compared to two in GK107, with only a 25% increase in die area.
Improved Instruction Scheduling
The number of CUDA Cores per SM has been reduced to a power of two, however with Maxwell’s improved execution efficiency, performance per SM is usually within 10% of Kepler performance, and the improved area efficiency of the SM means CUDA cores per GPU will be substantially higher versus comparable Fermi or Kepler chips. The Maxwell SM retains the same number of instruction issue slots per clock and reduces arithmetic latencies compared to the Kepler design.
As with SMX, each SMM has four warp schedulers, but unlike SMX, all core SMM functional units are assigned to a particular scheduler, with no shared units. The power-of-two number of CUDA Cores per partition simplifies scheduling, as each of SMM’s warp schedulers issue to a dedicated set of CUDA Cores equal to the warp width. Each warp scheduler still has the flexibility to dual-issue (such as issuing a math operation to a CUDA Core in the same cycle as a memory
operation to a load/store unit), but single-issue is now sufficient to fully utilize all CUDA Cores.
Increased Occupancy for Existing Code
In terms of CUDA compute capability, Maxwell’s SM is CC 5.0. SMM is
similar in many respects to the Kepler architecture’s SMX, with key
enhancements geared toward improving efficiency without requiring
significant increases in available parallelism per SM from the
application. The register file size and the maximum number of concurrent
warps in SMM are the same as in SMX (64k 32-bit registers and 64 warps,
respectively), as is the maximum number of registers per thread (255).
However the maximum number of active thread blocks per multiprocessor
has been doubled over SMX to 32, which should result in an automatic
occupancy improvement for kernels that use small thread blocks of 64 or
fewer threads (assuming available registers and shared memory are not
the occupancy limiter). Table 1 provides a comparison between key
characteristics of Maxwell GM107 and its predecessor Kepler GK107.
Reduced Arithmetic Instruction Latency
Another major improvement of SMM is that dependent arithmetic
instruction latencies have been significantly reduced. Because occupancy
(which translates to available warp-level parallelism) is the same or
better on SMM than on SMX, these reduced latencies improve utilization
and throughput.
| GPU | GK107 (Kepler) | GM107 (Maxwell) |
| CUDA Cores | 384 | 640 |
| Base Clock | 1058 MHz | 1020 MHz |
| GPU Boost Clock | N/A | 1085 MHz |
| GFLOP/s | 812.5 | 1305.6 |
| Compute Capability | 3.0 | 5.0 |
| Shared Memory / SM | 16KB / 48 KB | 64 KB |
| Register File Size / SM | 256 KB | 256 KB |
| Active Blocks / SM | 16 | 32 |
| Memory Clock | 5000 MHz | 5400 MHz |
| Memory Bandwidth | 80 GB/s | 86.4 GB/s |
| L2 Cache Size | 256 KB | 2048 KB |
| TDP | 64W | 60W |
| Transistors | 1.3 Billion | 1.87 Billion |
| Die Size | 118 mm2 | 148 mm2 |
| Manufactoring Process | 28 nm | 28 nm |
2. Larger, Dedicated Shared Memory
A significant improvement in SMM is that it provides 64KB of
dedicated shared memory per SM—unlike Fermi and Kepler, which
partitioned the 64KB of memory between L1 cache and shared memory. The
per-thread-block limit remains 48KB on Maxwell, but the increase in
total available shared memory can lead to occupancy
improvements. Dedicated shared memory is made possible in Maxwell by
combining the functionality of the L1 and texture caches into a single
unit.
3. Fast Shared Memory Atomics
Maxwell provides native shared memory atomic operations for 32-bit
integers and native shared memory 32-bit and 64-bit compare-and-swap
(CAS), which can be used to implement other atomic functions. In
contrast, the Fermi and Kepler architectures implemented shared memory
atomics using a lock/update/unlock pattern that could be expensive in
the presence of high contention for updates to particular locations in
shared memory.
4. Support for Dynamic Parallelism
Kepler GK110 introduced a new architectural feature called Dynamic
Parallelism, which allows the GPU to create additional work for itself. A
programming model enhancement leveraging this feature was introduced in
CUDA 5.0 to enable threads running on GK110 to launch additional
kernels onto the same GPU.
SMM brings Dynamic Parallelism into the mainstream by supporting it
across the product line, even in lower-power chips such as GM107. This
will benefit developers, because it means that applications will no
longer need special-case algorithm implementations for high-end GPUs
that differ from those usable in more power constrained environments.
5. Learn More about Programming Maxwell
For more architecture details and guidance on optimizing your code for Maxwell, I encourage you to check out the Maxwell Tuning Guide and Maxwell Compatibility Guide, which are available now to CUDA Registered Developers.
5 Things You Should Know About the New Maxwell GPU Architecture的更多相关文章
- Angular2学习笔记(1)
Angular2学习笔记(1) 1. 写在前面 之前基于Electron写过一个Markdown编辑器.就其功能而言,主要功能已经实现,一些小的不影响使用的功能由于时间关系还没有完成:但就代码而言,之 ...
- 动画requestAnimationFrame
前言 在研究canvas的2D pixi.js库的时候,其动画的刷新都用requestAnimationFrame替代了setTimeout 或 setInterval 但是jQuery中还是采用了s ...
- 【AR实验室】OpenGL ES绘制相机(OpenGL ES 1.0版本)
0x00 - 前言 之前做一些移动端的AR应用以及目前看到的一些AR应用,基本上都是这样一个套路:手机背景显示现实场景,然后在该背景上进行图形学绘制.至于图形学绘制时,相机外参的解算使用的是V-SLA ...
- iOS代码规范(OC和Swift)
下面说下iOS的代码规范问题,如果大家觉得还不错,可以直接用到项目中,有不同意见 可以在下面讨论下. 相信很多人工作中最烦的就是代码不规范,命名不规范,曾经见过一个VC里有3个按钮被命名为button ...
- 梅须逊雪三分白,雪却输梅一段香——CSS动画与JavaScript动画
CSS动画并不是绝对比JavaScript动画性能更优越,开源动画库Velocity.js等就展现了强劲的性能. 一.两者的主要区别 先开门见山的说说两者之间的区别. 1)CSS动画: 基于CSS的动 ...
- 阿里巴巴直播内容风险防控中的AI力量
直播作为近来新兴的互动形态和今年阿里巴巴双十一的一大亮点,其内容风险监控是一个全新的课题,技术的挑战非常大,管控难点主要包括业界缺乏成熟方案和标准.主播行为.直播内容不可控.峰值期间数千路高并发处理. ...
- 虾扯蛋:Android View动画 Animation不完全解析
本文结合一些周知的概念和源码片段,对View动画的工作原理进行挖掘和分析.以下不是对源码一丝不苟的分析过程,只是以搞清楚Animation的执行过程.如何被周期性调用为目标粗略分析下相关方法的执行细节 ...
- 【探索】无形验证码 —— PoW 算力验证
先来思考一个问题:如何写一个能消耗对方时间的程序? 消耗时间还不简单,休眠一下就可以了: Sleep(1000) 这确实消耗了时间,但并没有消耗 CPU.如果对方开了变速齿轮,这瞬间就能完成. 不过要 ...
- 对抗密码破解 —— Web 前端慢 Hash
(更新:https://www.cnblogs.com/index-html/p/frontend_kdf.html ) 0x00 前言 天下武功,唯快不破.但在密码学中则不同.算法越快,越容易破. ...
- H5单页面手势滑屏切换原理
H5单页面手势滑屏切换是采用HTML5 触摸事件(Touch) 和 CSS3动画(Transform,Transition)来实现的,效果图如下所示,本文简单说一下其实现原理和主要思路. 1.实现原理 ...
随机推荐
- 在vim下按ctrl+s后界面卡住
用惯了window编辑器的我们,在使用linux vim编辑器时会不会遇到这个问题:在编辑时总是会不小心按下Ctrl+S,然后整个终端都没有反应了?其实在Linux下 Ctrl+S是有特殊的用途的,不 ...
- INSPIRED启示录 读书笔记 - 第25章 快速响应阶段
产品出炉后切莫虎头蛇尾 急于“撤军”是项目管理和产品开发流程中的大忌,只要稍微延长项目周期,观察用户对产品的反应,效果就会有天壤之别.这样做投资之小.回报之高会令你瞠目结舌,绝非其他项目阶段可比 产品 ...
- Java 内部类、静态类内部类
问: 什么是内部类? 答: 内部类(Inner Class)就是在一个类的内部再定义一个类,与之对应包含内部类的类被称为外部类. 问: 为什么要将一个类定义在另外一个类内部呢? 答: 内部类主要作用如 ...
- 未能将网站配置为使用ASP.NET4.X 解决方法
WIN 10系统安装Visual Studio 2012新建ASP.NET MVC 4 WEB 应用程序出错 有些图片是网上截取而来,之前光顾着处理问题而忘记截图了,提示的ASP.net 版本有些不同 ...
- shell 计算文件交并差
交集 $ sort a b | uniq -d 并集 $ sort a b | uniq 差集a-b $ sort a b b | uniq -u 文件乱序 cat tmp.txt | awk 'BE ...
- java入门了解04
1.异常的体系:---------|Throwable --------------| Error (错误) 错误一般是由于jvm或者是硬件引发的问题,所以我们一般都不会通过代码去处理.------- ...
- C#反射第一天
[转]C#反射 反射(Reflection)是.NET中的重要机制,通过放射,可以在运行时获得.NET中每一个类型(包括类.结构.委托.接口和枚举等)的成员,包括方法.属性.事件,以及构造函数等. ...
- vijos 1250 最勇敢的机器人 分组背包+并查集
P1250最勇敢的机器人 背景 Wind设计了很多机器人.但是它们都认为自己是最强的,于是,一场比赛开始了~ 描述 机器人们都想知道谁是最勇敢的,于是它们比赛搬运一些物品. 它们到了一个仓库,里面有n ...
- iframe标签的子父页面调用函数和属性
在使用iframe标签时,总想通过子页面调用父页面的一些方法和属性.今天终于发现了. 1在父页面写一个函数 //让子页面来调用此方法,控制导航栏 function childfunc(){ alert ...
- 【转】移动oracle LOB索引到其他表空间
http://blog.chinaunix.net/uid-22948773-id-3451103.html