Python基本数据类型集合、格式化、函数
一、变量总结
1.1 变量定义
记录某种状态或者数值,并用某个名称代表这个数值或状态。
1.2 变量在内存中的表现形式
Python 中一切皆为对象,数字是对象,列表是对象,函数也是对象,任何东西都是对象。而变量是对象的一个引用(又称为名字或者标签),对象的操作都是通过引用来完成的。例如,[]是一个空列表对象,变量 a 是该对象的一个引用
在 Python 中,「变量」更准确叫法是「名字」,赋值操作 = 就是把一个名字绑定到一个对象上。就像给对象添加一个标签。
a = 1

整数 1 赋值给变量 a 就相当于是在整数1上绑定了一个 a 标签。
a = 2

整数 2 赋值给变量 a,相当于把原来整数 1 身上的 a 标签撕掉,贴到整数 2 身上。
b = a
把变量 a 赋值给另外一个变量 b,相当于在对象 2 上贴了 a,b 两个标签,通过这两个变量都可以对对象 2 进行操作。
变量本身没有类型信息,类型信息存储在对象中,这和C/C++中的变量有非常大的出入(C中的变量是一段内存区域)
1.3 id()
id方法的返回值就是对象的内存地址。
python中会为每个出现的对象分配内存。
1.4 可变类型和不可变类型
可变类型:列表list、字典dict、集合set
不可变类型:数值类型(int和float)、字符串str、元组tuple
1.5 按访问顺序分类
a、顺序访问:字符串、列表、元组,可以索引,下标
b、映射访问:字典,使用链表
c、直接访问:数字
1.6 存放元素个数:
容器类型:列表、元组、字典,能够存放多个值。
原子类型:数字、字符串,只存放一个值。
二、集合
1、集合定义:由不同元素组成,元素全部都是无序的,元素都是不可变类型。
2、集合元素必须是是数字、字符串、元组。
3、由于集合必须是不同元素组成,定义时可以重复,但输出时自动去掉重复的元素。
例子
set1= {1,2,2,2,3,4,5,6,6}
print(set1)
输出结果
{1, 2, 3, 4, 5, 6}
4、集合是无序的
例子
set1= {"hello","world","nicholas","nick"}
print(set1)
输出结果
{'hello', 'nicholas', 'world', 'nick'}
再次运行输出结果
{'nick', 'hello', 'nicholas', 'world'}
5、集合的元素必须是不可变类型
例子
set1= {"hello",[1,2]}
print(set1)
输出结果
报错TypeError: unhashable type: 'list',无法对列表进行哈希化
但在创建集合的时候可以使用列表
例子
s = set(["nicholas","niubi",])
print(s)
输出结果
{'nicholas', 'niubi'}
6、创建定义集合的方法
set1= {"hello",8}
set2 = set("hello")
print(set1)
print(set2)
输出结果
{8, 'hello'}
{'o', 'h', 'e', 'l'}
分析:这里的第二个set将字符串每个字符循环了一遍,然后去掉了重复的l
例子
s = set(["hello","nicholas","hello"])
print(s)
输出结果
{'hello', 'nicholas'}
分析:这里也是将列表循环了一次,去掉重复的元素。
三、集合的方法
1、add()
例子
s = {"hello","nicholas","hello",1,(8,"nihao")}
s.add("world")
print(s)
输出结果
{1, 'world', 'nicholas', 'hello', (8, 'nihao')}
分析:这里自动去掉了重复的元素,添加的元素也必须是不可变类型,同时符合元素不能重复的条件。
2、clear()
例子
s = {"hello","nicholas","hello",1,(8,"nihao")}
s.clear()
print(s)
输出结果
set()
分析:字典的清空结果是{},集合的清空结果是set()
3、copy()
例子
s = {"hello","nicholas","hello",1,(8,"nihao")}
s2 = s.copy()
print(s2)
输出结果
{(8, 'nihao'), 'nicholas', 'hello', 1}
4、pop()
例子
s = {"nicholas","hello",1,(8,"nihao")}
s.pop()
print(s)
输出结果
第一次:
{'hello', 'nicholas', (8, 'nihao')}
第二次
{1, 'nicholas', 'hello'}
分析:由于集合是无序的,这里是随机的删除。
5、remove()
删除指定的元素
例子
s = {"nicholas","hello",1,(8,"nihao")}
s.remove("hello")
print(s)
输出结果
{(8, 'nihao'), 1, 'nicholas'}
分析:这里用remove()的参数可以指定删除,如果指定的参数原集合没有则会报错。
6、discard()
指定删除集合中的元素。
s = {"nicholas","hello",1,(8,"nihao")}
s.discard("hello")
print(s)
输出结果
{'nicholas', 1, (8, 'nihao')}
例子2
s = {"nicholas","hello",1,(8,"nihao")}
s.discard("nick")
print(s)
输出结果
{1, 'nicholas', (8, 'nihao'), 'hello'}
分析:这里discard()里的参数在原集合里没有,但是这里不会报错,只是会输出原集合。
7、用set()将列表去掉重复的元素
利用集合元素不能重复的特点对列表中的元素进行去重。
例子
li1 = ["nicholas","pony","jack","nicholas"]
s1 = set(li1)
new_li1 = list(s1)
print(new_li1 )
输出结果
['jack', 'nicholas', 'pony']
分析:这样利用了集合的特点去重,但是原列表的顺序也没有了。
四、集合关系运算
1、取交集
1.1 list中for循环取交集
例子
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard "]
li1_and_li2 = []
for i in li1:
if i in li2:
li1_and_li2.append(i)
print(li1_and_li2)
输出结果
['nicholas']
分析:这里是用for循环遍历每个列表元素,同时在循环体内部用in判断是否在li2里,用append()添加在空列表里。
1.2 集合中 intersection()取交集
简化符号 &
例子
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard "]
s1 = set(li1)
s2 = set(li2)
v = s1.intersection(s2)
#这里也可以这样写
#v = s1&s2
#去掉小圆点和括号
print(v)
#print(s1&s2)
输出结果
{'nicholas'}
或者直接写成这样,效果一样的
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard "]
print(set(li1).intersection(set(li2)))
输出结果
{'nicholas'}
2、集合取并集
union()
简化符号 |
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard "]
s1 = set(li1)
s2 = set(li2)
v = s1.union(s2)
print(v)
print(s1 | s2)
#这里用简化符号也可以
输出结果
{'pony', 'robin', 'jack', 'nicholas', 'charles', 'Richard '}
{'pony', 'robin', 'jack', 'nicholas', 'charles', 'Richard '}
3、求差集
difference()
简化符号 -
例子
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard ","jack"]
s1 = set(li1)
s2 = set(li2)
v = s1.difference(s2)
print(v)
print(s1 - s2)
#这里也可以用简化符号
输出结果
{'robin', 'pony'}
{'robin', 'pony'}
4、交叉补集
symmetric_difference()
简化符号 ^
例子
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard ","jack"]
s1 = set(li1)
s2 = set(li2)
v = s1.symmetric_difference(s2)
print(v)
print(s1 ^ s2)
输出结果
{'robin', 'Richard ', 'charles', 'pony'}
{'robin', 'Richard ', 'charles', 'pony'}
集合的交集、差集、并集、补集几何含义
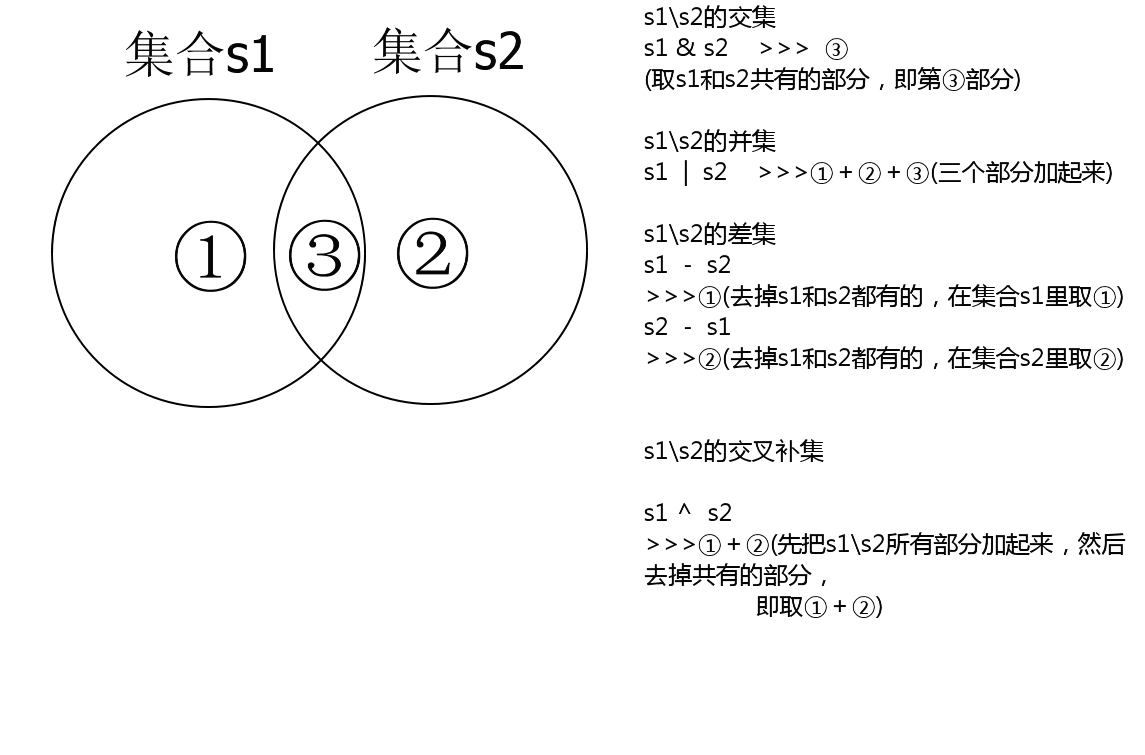
图4
五、集合的其他方法
1、difference_update()
用图4的表示方法,集合s1中存在,集合s2中不存在,把集合s1重新赋值为①
即s1 = s1 - s2
将s1更新为s1和s2的差集
例子
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard ","jack"]
s1 = set(li1)
s2 = set(li2)
s1.difference_update(s2)
#s1 = s1 - s2,这里其实就是这样的
print(s1)
输出结果
{'pony', 'robin'}
2、intersection_update()
用图4的表示方法,集合s1和集合s2取交集,并把结果更新在集合s1中,把③给集合s1。
即s1 = s1 & s2
例子
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard ","jack"]
s1 = set(li1)
s2 = set(li2)
s1.intersection_update(s2)
#s1 = s1 & s2
print(s1)
输出结果
{'nicholas', 'jack'}
3、isdisjoint()
如果两个集合取交集是空集,那么返回True,不是空集返回False.
例子
li1 = ["nicholas","pony","robin","jack"]
li2 = ["nicholas","charles","Richard ","jack"]
s1 = set(li1)
s2 = set(li2)
v = s1.isdisjoint(s2)
print(v)
输出结果
False
例子2
li1 = ["nicholas","pony","robin","jack"]
li2 = ["charles","Richard "]
s1 = set(li1)
s2 = set(li2)
v = s1.isdisjoint(s2)
print(v)
输出结果
True
4、issubset()
是不是子集,subset :子集
s1.issubset(s2)
判断s1是不是s2的子集
例子
s1 = {"nicholas","pony","robin","jack"}
s2 = {"robin","jack"}
v = s1.issubset(s2)
print(v)
输出结果
False
例子2
s1 = {"nicholas","pony","robin","jack"}
s2 = {"robin","jack"}
v = s2.issubset(s1)
print(v)
输出结果
True
5、issuperset()
s1.issuperset(s2)
判断s1是不是包含s2,superset:父集,超集
例子
s1 = {"nicholas","pony","robin","jack"}
s2 = {"robin","jack"}
v = s1.issuperset(s2)
print(v)
输出结果
True
例子2
s1 = {"nicholas","pony","robin","jack"}
s2 = {"robin","jack"}
v = s2.issuperset(s1)
print(v)
输出结果
False
6、symmetric_difference_update()
用图1的表示方法,集合s1和集合s2取交叉补集,并把结果更新在集合s1中,把①﹢②给集合s1。
s1 = s1 ^ s2
例子
s1 = {"nicholas","pony","robin","jack"}
s2 = {"charles","richard","robin"}
s1.symmetric_difference_update(s2)
print(s1)
输出结果
{'pony', 'richard', 'charles', 'jack', 'nicholas'}
7、update()
7.1
s1.update(s2)
将集合s1结果添加集合s2
例子
s1 = {"nicholas","pony","robin","jack"}
s2 = {"charles","richard","robin"}
s1.update(s2)
print(s1)
输出结果
{'richard', 'pony', 'nicholas', 'robin', 'jack', 'charles'}
7.2 与union(并集)的区别
例子
s1 = {"nicholas","pony","robin","jack"}
s2 = {"charles","richard","robin"}
s1.union(s2)
print(s1)
输出结果
{'robin', 'jack', 'nicholas', 'pony'}
分析:s1.union(s2)这里只是做了并集的操作,这时这里的s1仍然没变。
7.3 与add()的差别
例子
s1 = {"nicholas","pony","robin","jack"}
s2 = {"charles","richard","robin"}
s1.add(s2)
print(s1)
输出结果:报错,unhashable type
分析:add()只能增加单个值, update()可以传可迭代对象,更新多个值
例子
s1 = {"nicholas","pony","robin","jack"}
s2 = {"charles","richard","robin"}
s1.add("william")
print(s1)
输出结果
{'pony', 'william', 'robin', 'nicholas', 'jack'}
8、frozenset()
不能追加,不能修改的集合,不能删除。
例子
s1 = frozenset(["nicholas","pony","robin","jack"])
print(s1)
输出结果
frozenset({'nicholas', 'pony', 'robin', 'jack'})
例子
s1 = frozenset(["nicholas","pony","robin","jack"])
s1.pop()
print(s1)
输出结果:报错,AttributeError: 'frozenset' object has no attribute 'pop'
分析:frozenset()定义的集合,不能追加,不能修改,不能删除。
六、字符串的格式化
格式符为真实值预留位置,并控制显示的格式。格式符可以包含有一个类型码,用以控制显示的类型
1、百分号方式
(1)%s
例子
msg = "I am %s ,age %s"%("nicholas",18)
print(msg)
输出结果
I am nicholas ,age 18
分析:这里的%是一个格式化符,s是被字符串后面的变量替换占位符。
在字符串里用%s可可以接收单个值,可以接收多个值传入到字符串,接收多个值要在传入的值%后面加个括号。
例子
print("I am %s ,age %s"%"nicholas")
输出结果:报错,not enough arguments for format string,没有足够的变量进行格式化
分析:字符串里有多少个格式化符%,字符串后面要加多少个要传入的值,不能少写。
%s可以还可以接收数字、列表。
例子
print("I am %s ,age %s"%("nicholas",18))#传入多个值加括号,%s可以传入数字
print("I am %s "%["nicholas"])#这里传入的是列表
输出结果
I am nicholas ,age 18
I am ['nicholas']
(2)%d
只能接受整数的传入,即只能进行整数的格式化。
例子
print("I am %d "%18)
输出结果
I am 18
例子
print("I am %d "%"nicholas")
输出结果:报错
分析:%d只能接收整数的传入,不接收字符串、列表。
例子
print("I am %d "%18.96)
输出结果
I am 18
分析:%d可以接收浮点数,但是会自动取整数部分。
(3)%f
进行浮点数的格式化
例子
print("I have %f dollars "%18.96) #%f可以接收浮点数,默认保留小数点后6位
print("I have %.2f dollas "%18.96 )# 在格式化符后加上.2保留小数点后2位
print("I have %.3f dollas "%18.96 )# 在格式化符后加上.3保留小数点后3位
输出结果
I have 18.960000 dollars
I have 18.96 dollas
I have 18.960 dollas
(4)%.2f%%
将百分比打印出来
print("I hold %.2f of the share "%18.96 )
print("I hold %.2f %% of the share "%18.96 ) #在格式化符号之后加上%%即可打印百分号
输出结果
I hold 18.96 of the share
I hold 18.96 % of the share
(5)%的其他用法
例子
print("I am %(name)s ,age %(age)d"%{"name":"nicholas","age":18})
#name代表了后面的要传入字典的值,括号里的age代表了后面的要传入字典的值
print("I have %(num)f dollars " %{ "num":18.96})
print("I have %(num).2f dollars " %{ "num":18.96})
#num代表了后面的要传入字典的值
输出结果
I am nicholas ,age 18
I have 18.960000 dollars
I have 18.96 dollars
(6)百分号语法
%[(name)][flags][width].[precision]typecode
(name) 可选,用于选择指定的key
flags 可选,可供选择的值有:
+ 右对齐;正数前加正好,负数前加负号;
- 左对齐;正数前无符号,负数前加负号;
空格 右对齐;正数前加空格,负数前加负号;
0 右对齐;正数前无符号,负数前加负号;
用0填充空白处
width 可选,占有宽度
.precision 可选,小数点后保留的位数
typecode 必选
s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
f,将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
%,当字符串中存在格式化标志时,需要用 %%表示一个百分号
(7)%的对齐
例子
print("I am %(name)-50s ,age 18"%{"name":"nicholas"})
#name后用-50,左对齐宽度是50
print("I am %(name)+50s ,age 18"%{"name":"nicholas"})
#name后用-50,右对齐宽度是50
输出结果
I am nicholas ,age 18
I am nicholas ,age 18
分析:根据语法,-是左对齐,后面的数字是规定的对齐的宽度。
(8)不用格式化的方式
例子
print('root','x','','',sep=':')
输出结果
root:x:0:0
2、format方式
语法:
[[fill]align][sign][#][0][width][,][.precision][type]

例子
print("I am {} ,age {} ,{}".format("nicholas",18,"niubi"))
#k可以直接用空的大括号,与后面的是一一对应的关系
print("I am {0} ,age {1},{2}".format("nicholas",18,"niubi"))
#也可以在大括号里加入数字序号,这里也是与后面是一一对应的关系
print("I am {2} ,age {1},{0}".format("nicholas",18,"niubi"))
#这里注意看下,大括号里的数字可以决定选取后面的哪个值
print("I am {2} ,age {2},{2}".format("nicholas",18,"niubi"))
#这里注意看下,大括号里的数字可以决定选取后面的哪个值
print("I am {name} ,age {age},{niu}".format(name= "nicholas",age = 18,niu = "niubi"))
#大括号里也可以加上变量名,在后面直接用变量 = 进行赋值
print("I am {name} ,age {name},{name}".format(name= "nicholas",age = 18,niu = "niubi"))
#大括号里的变量名也可以决定取后面的哪些值
print("I am {name} ,age {age},{name}".format(**{"name": "nicholas","age" : 18,"niu": "niubi"}))
#大括号里加上变量名,后面写成字典的形式,但是要在字典前加上**
#同样这里大括号里的变量名也可以决定取后面的哪些值
print("I am {0[2]} ,age {1[1]},{1[2]}".format([1,2,"nicholas"],[3,18,"niubi"]))
#如果后面是列表,可以在大括号里根据.format的索引进行取值
print("I am {:s} ,age {:d},{:f}".format("nicholas",18,99.886))
#大括号里也可以规定后面数值的格式
print("I am {:s} ,age {:d},{:f}".format(*["nicholas",18,99.886]))
#如果传入的是列表,.format后要加上*
print("I am {name:s} ,age {age:d},{niu:s}".format(name= "nicholas",age = 18,niu = "niubi"))
print("I am {name:s} ,age {age:d},{name:s}".format(**{"name": "nicholas","age" : 18,"niu": "niubi"}))
#传入字典,大括号里加:s符号的格式
print("numbers: {:b},{:o},{:d},{:x},{:X}, {:%}".format(15, 15, 15, 15, 15, 15.87623, 2))
# :b,将10进制整数转换成2进制然后格式化
# :o 将10进制整数自动转换成8进制然后格式化
# :d 十进制整数
# :x # 将10进制整数自动转换成16进制然后格式化(小写x)
# :X 将10进制整数自动转换成16进制表示然后格式化(大写X)
# % 显示百分比(默认显示小数点后6位)
print("numbers: {0:b},{0:o},{0:d},{0:x},{0:X}, {0:%}".format(15,1))
#对后面的第0个元素进行取值并格式化
输出结果
I am nicholas ,age 18 ,niubi
I am nicholas ,age 18,niubi
I am niubi ,age 18,nicholas
I am niubi ,age niubi,niubi
I am nicholas ,age 18,niubi
I am nicholas ,age nicholas,nicholas
I am nicholas ,age 18,nicholas
I am nicholas ,age 18,niubi
I am nicholas ,age 18,99.886000
I am nicholas ,age 18,99.886000
I am nicholas ,age 18,niubi
I am nicholas ,age 18,nicholas
numbers: 1111,17,15,f,F, 1587.623000%
numbers: 1111,17,15,f,F, 1500.000000%
七、函数
1、编程中的函数定义
编程语言中的函数是通过一个函数名封装好一串用来完成某一特定功能的逻辑.
将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可.
2、使用函数的作用
使用函数的好处:
a.代码重用
b.保持一致性,易维护
c.可扩展性
3、函数的返回值
函数可以不返回值,可以返回一个值,也可以返回多个值
总结
没有返回值:返回None
返回值数=1:返回object(对象)
返回值数>1:返回tuple(元组)
例子
def test1( ):
new = "hello" def test2( ):
new2 = "hello"
return new2
def test3( ):
new3 = "hello"
return 1,2,3,4,[5,8],{"nicholas"} v1= test1()
v2= test2()
v3= test3()
print(v1)
print(v2)
print(v3)
输出结果
None
hello
(1, 2, 3, 4, [5, 8], {'nicholas'})
4、函数的参数

a.形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
b.实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
c、return返回语句
函数中只要执行到return语句,函数就自动结束
可以写多个return语句但是第二个及之后的return语句不会被执行。
例子
def test(x):
new = x + 1
return new
return x
a = 2
v= test(a)
print(v)
输出结果
1 3
分析:这里的第二个return语句永远不会被执行。
d、位置参数:实参和形参是一一对应的,这是标准调用。
例子:
def test(x,y,z ):
print(x)
print(y)
print(z)
test(1,2,3)
输出结果
1
2
3
分析:这里的1,2,3是和形参x,y,z是一一对应的。即x = 1,y =2 ,z = 3. test(1,2,3)这里必须有三个参数,缺一不可。
例子
def test(x,y,z ):
print(x)
print(y)
print(z)
test(1,2)
输出结果
报错,test() missing 1 required positional argument
test()缺少一个要求位置参数。
e、关键字调用:位置无需固定
例子
def test(x,y,z ):
print(x)
print(y)
print(z)
test(y = 1,x = 3 ,z = 2)
输出结果
3
1
2
分析:这里的实参顺序不影响形参的取值,实参可以随意调整顺序。
如果位置参数和关键字参数混合使用,**则位置参数必须在关键字参数左边**。同时形参必须每个都要取到实参的值,不能重复或者缺少,也不能多。
例子
def test(x,y,z ):
print(x)
print(y)
print(z)
test(1,y=3,z = 2)
输出结果
1
3
2
f、默认参数
例子
def test(x,y = 2 ):
print(x)
print(y)
test(1)
输出结果
1
2
分析:这里的y=2就是一个默认的参数,在设定实参时可以不写,也可以写,在实参里默认参数对应的位置写了新的数值,原默认参数会被覆盖掉。
例子
def test(x,y = 2 ):
print(x)
print(y)
test(1,8)
输出结果:
1
8
g、参数组
(1)在函数定义中使用*args和**kwargs传递可变长参数。
*args用作传递非命名键值可变长参数列表(位置参数),在函数内为元组; **kwargs用作传递键值可变长参数列表。
(关键字参数)在函数里为字典。
例子:
def test(x,*args ):
print(x)
print(args)
test(1,2,3,4,5)
输出结果
1
(2, 3, 4, 5)
分析:这里的实参1传给了x,其他的2,3,4,5传给了args。
例子
def test(x,*args ):
print(x)
print(args)
test(1)
输出结果
1
()
分析:如果args对应的位置实参没有传入值,则输出空的元组。
例子
def test(x,*args ):
print(x)
print(args)
print(args[0][0])
test(1,["h","l","l"])
输出结果
1
(['h', 'l', 'l'],)
h
分析:这里把列表作为一个值传给args,在函数里args是一个元组,而列表是元组的第一个元素,h是列表的第一个元素,所以要打印h应该是args[0][0]。
例子
def test(x,*args ):
print(x)
print(args)
test(1,*["h","l","l"])
输出结果
1
('h', 'l', 'l')
分析:这里如果在[]前加上*,则函数将会对列表进行遍历,循环每个元素传给args
与test(1,"h","l","l")效果一样。
例子
def test(x,*args ):
print(x)
print(args)
test(1,*("h","l","l"))
输出结果
1
('h', 'l', 'l')
分析:这里如果在()前加上*,则函数将会对元组进行遍历,循环每个元素传给args
与test(1,"h","l","l")效果一样。
(2)**kwargs
传递多个关键字参数的方式
。
例子
def test(x,**kwargs ):
print(x)
print(kwargs)
test(1,y=2,z=3)
输出结果
1
{'y': 2, 'z': 3}
分析:函数将1传给x,将y=2,z=3传给kwargs,在函数里args是一个字典。
(3)将*args和*kwargs一起使用
例子
def test(x,*args,**kwargs ):
print(x)
print(args)
print(kwargs)
test(1,2,3,4,5,6,y=2,z=3,q=8)
输出结果
1
(2, 3, 4, 5, 6)
{'y': 2, 'z': 3, 'q': 8}
分析:这里混合使用了位置参数和关键字参数。 1传给x, 2,3,4,5,6传给args,
y=2,z=3,q=8传给kwargs.
例子
def test(x,*args,**kwargs ):
print(x)
print(args[0])
print(kwargs["z"])
test(1,2,3,4,5,6,y="k",z="w",q="s")
输出结果
1
2
w
分析:这里也可以根据索引处理args、kwagrs。
例子
def test(x,*args,**kwargs ):
print(x)
print(args)
print(kwargs)
test(1,*[2,3,4,5,6],**{"y":"k","z":"w","q":"s"})
输出结果:
1
(2, 3, 4, 5, 6)
{'y': 'k', 'z': 'w', 'q': 's'}
分析:用*直接传一个列表,用**传一个字典。
Python基本数据类型集合、格式化、函数的更多相关文章
- python基础数据类型--集合(set)
python基础数据类型--集合(set) 集合是一个数学概念由一个或多个确定的元素所构成的整体叫做集合 集合中的三个特征 1.确定性(元素必须死可hash) 2.互异性(去重) 3.无序性(集合中的 ...
- Python之路(第五篇) Python基本数据类型集合、格式化、函数
一.变量总结 1.1 变量定义 记录某种状态或者数值,并用某个名称代表这个数值或状态. 1.2 变量在内存中的表现形式 Python 中一切皆为对象,数字是对象,列表是对象,函数也是对象,任何东西都是 ...
- Python:Day14 集合、函数
浅copy只copy一层 深copy相当于克隆一份 深copy要引入copy,具体如下: import copy wife = copy.copy() #此为浅copy,括号中要加copy的对象,相当 ...
- python字符串之format格式化函数
学习中~ 觉得应该系统地学习一下python,今天学习了字符串,以下是自己的笔记. 首先说一下format函数,用{}和:代替了%,比如: >>>“{} {} {}”.format( ...
- python基本数据类型集合set操作
转:https://www.cnblogs.com/tina-python/p/5468495.html 一.集合的定义 set集合,是一个无序且不重复的元素集合. 集合对象是一组无序排列的可哈希的值 ...
- 实验与作业(Python)-04 数据类型、数学函数与字符串
截止日期 实验目标 继续熟悉for循环与turtle 数值运算符 math库常用函数 字符串转化为数值类型(int, float, complex) 字符串常用函数 实验内容 任务1.使用for代替w ...
- python基本数据类型——集合
集合 无序可变序列,集合中元素不允许重复,即每个元素都是唯一的 集合中的元素按照升序排列 # 创建集合 >>aset = set([0,2,4,5,7,2,3,5,9,0]) >&g ...
- python numpy 数据集合操作函数
arrarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])arr1array([0, 1, 2, 3, 4])np.intersect1d(arr,arr1)#计算数组ARR A ...
- Python基本数据类型--列表、元组、字典、集合
一.Python基本数据类型--列表(List) 1.定义:[ ]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素. 2.列表的创建: # 方式一 list1 = ['name','ag ...
随机推荐
- html-select
<html><head> <title>select选择标签</title> <meta charset="UTF-8"> ...
- python实现文件下载的方法总结
前端时间遇到一个通过url下载文件的需求,只需要简单的编写一个py脚本即可.从网上搜了下python实现文件下载的方法,总结如下,备查. 以下方法均已测试,环境win8.1 python2.6/2. ...
- python3导入自定义模块
模块是个好东西啊,大牛们开源共享许多模块也加快了大家开发的速度,许多开源模块可以在这里找到 ↓ https://pypi.python.org/pypi 因为刚入门所有有很多细节不懂,在网上搜寻资料的 ...
- 【原创】0. MYSQL++的环境准备
1. 获取 Google MYSQL++,第一个就是,然后跟着要求进行下载. 2. 编译和安装 其实在作者的各种README文档里面已经写得很清楚了,现在对一些可能会出现问题的地方进行一下回顾. Wi ...
- 数据库SQL优化大总结之 百万级数据库优化方案 【转载】
网上关于SQL优化的教程很多,但是比较杂乱.近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充. 这篇文章我花费了大量的时间查找资料.修改.排版,希望大家阅读之后,感觉 ...
- PHP json_encode 让URL//不转义
$json_info=json_encode((object)$data,JSON_UNESCAPED_SLASHES);
- 使用递归函数,输出n个元素的所有子集
题目描述: 请编写一个递归函数,用来输出n个元素的所有子集.例如,三个元素{a,b,c}的所有子集是:{},{a},{b},{c},{a,c},{ac},{b,c},{a,b,c}. 解题思路: 根据 ...
- Python代码注释
1.单行注释使用# # Code 2.多行注释,成对使用'''或""",三个单撇号或三个双引号 “”” Code “”” 3.多行快捷注释 1).增加注释 选中待注释的多 ...
- jdbc中Statement和PreparedStatement有什么区别?哪个性能更好?
Statement和PreparedStatement的功能主要是对sql语句的执行 区别 (1)Statement每执行一条sql语句就需要生成一条执行计划,执行100条就需要100条执行计划Pre ...
- Luogu 2868 [USACO07DEC]观光奶牛Sightseeing Cows
01分数规划复习. 这东西有一个名字叫做最优比率环. 首先这个答案具有单调性,我们考虑如何检验. 设$\frac{\sum_{i = 1}^{n}F_i}{\sum_{i = 1}^{n}T_i} = ...