Spark Streamming 基本输入流I(-) :File/Hdfs
Spark Streamming 基本输入流I(-):从文件中进行读取
文件读取1:本地文件读取
这里我只给出实现代码及操作步骤
1、在本地目录下创建目录,这里我们创建目录为~/log/
2、然后手动在~/目录下创建两个文件夹。t1.dat ,t2.dat
t1.dat 格式如下:
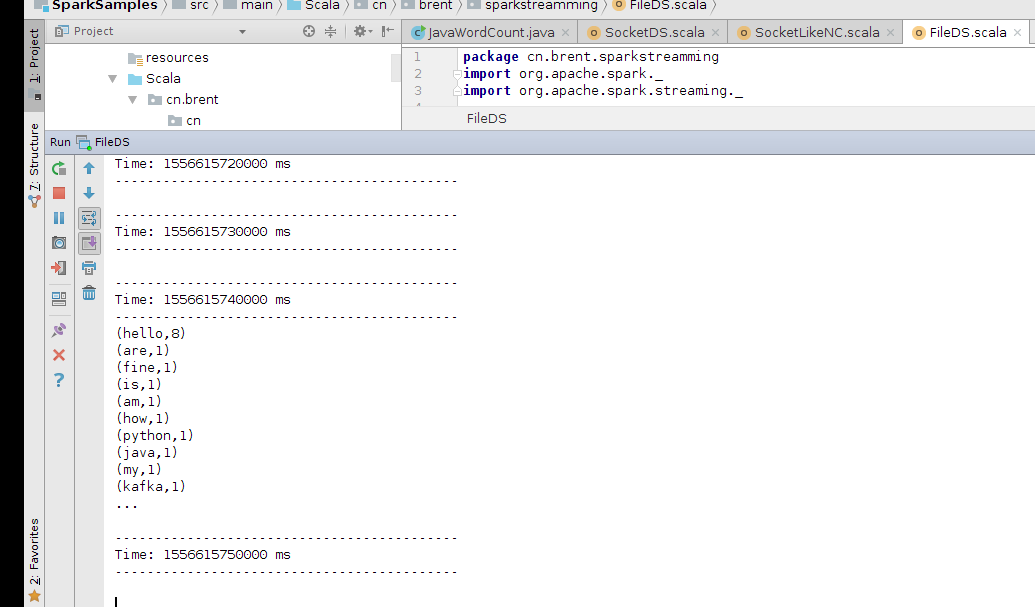
hello hadoop
hello spark
hello Java
hellp hbase
hello scala
t2.dat格式如下:
My name is Brent,
how are you
nice to meet you
3、编写spark streamming程序,并将其运行起来。
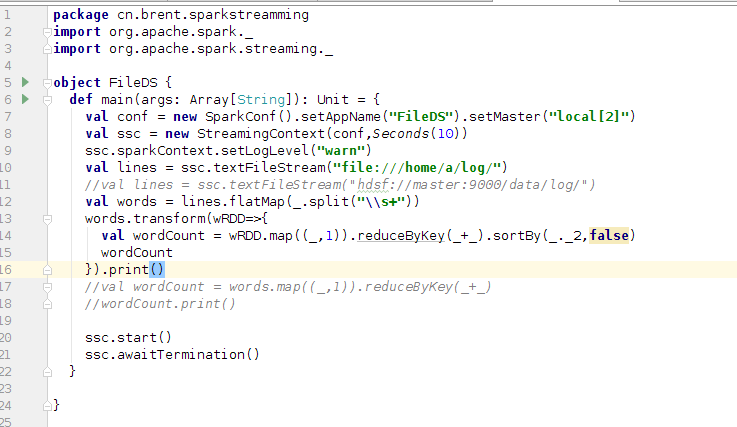
4、使用命令cp ~/t*.dat ./log/ 将t1.dat ,t2.dat移动到~/log目录下,
5、查看spark Streamming程序的运行情况。
文件读取2:HDFS文件读取
HDFS文件读取和本地是相差无几的,
不同之处如下
程序中修改文件引入路径//val lines = ssc.textFileStream("hdsf://master:9000/data/log/")
本地文件t1.dat 和 t2.dat 需要上传到hdfs://master:9000/data/log下
hdfs dfs -mkdir data/log 创建目录。
hdfs dfs -put t*.dat data/log/
注意点:
文件作为输入流容易出错的一点就是,目录下面的文件一定要是cp进来,而不是mv进来了,因为cp进行的文件时间戳是改变的,而mv进来的时间戳没有改变,spark Streamming就不会进行处理。
Spark Streamming 基本输入流I(-) :File/Hdfs的更多相关文章
- Spark Streamming 基本输入流(二) :Socket
Spark Streamming 可以通过socket 进行数据监听. socket的输入方可以通过nc 或者自己开发nc功能的程序. 1.系统自带的nc su root a yum install ...
- Spark2.x(五十五):在spark structured streaming下sink file(parquet,csv等),正常运行一段时间后:清理掉checkpoint,重新启动app,无法sink记录(file)到hdfs。
场景: 在spark structured streaming读取kafka上的topic,然后将统计结果写入到hdfs,hdfs保存目录按照month,day,hour进行分区: 1)程序放到spa ...
- ParquetDecodingException: Can not read value at 0 in block -1 in file hdfs:...
: jdbc:hive2://master01.hadoop.dtmobile.cn:1> select * from cell_random_grid_tmp2 limit 1; INFO : ...
- kettle在本地执行向远程hdfs执行转换错误"Couldn't open file hdfs"
kettle在本地执行向远程hdfs执行转换时,会出现以下错误: ToHDFS.0 - ERROR (version 7.1.0.0-12, build 1 from 2017-05-16 17.18 ...
- ERROR: Found lingering reference file hdfs
Found lingering reference异常 ERROR: Found lingering reference file hdfs://jiujiang1:9000/hbase/month_ ...
- Spark No FileSystem for scheme file 解决方法
在给代码带包成jar后,放到环境中运行出现如下错误: Exception in thread "main" java.io.IOException: No FileSystem f ...
- 通过Spark SQL关联查询两个HDFS上的文件操作
order_created.txt 订单编号 订单创建时间 -- :: -- :: -- :: -- :: -- :: order_picked.txt 订单编号 订单提取时间 -- :: ...
- MapReduce 踩坑 - hadoop No FileSystem for scheme: file/hdfs
一.场景 hadoop-3.0.2 + hbase-2.0.0 一个mapreduce任务,在IDEA下本地提交到hadoop集群可以正常运行. 现在需要将IDEA本地项目通过maven打成jar包, ...
- Spark设置自定义的InputFormat读取HDFS文件
本文通过MetaWeblog自动发布,原文及更新链接:https://extendswind.top/posts/technical/problem_spark_reading_hdfs_serial ...
随机推荐
- .reverse ,join,split区分
* 1:arrayObject.reverse() * 注意: 该方法会改变原来的数组,而不会创建新的数组. * 2:arrayObject.join() * 注意:join() 方法用于把数组中的所 ...
- vm12下Centos6的javaweb环境搭建
配置linux的javaweb环境之前: 1.在windows安装xshell(非必需,但是推荐) 2.在linux安装Linux与windows文件传输工具RZSZ[root@192 ~]# yum ...
- Python编程:基础学习常见错误整理
# Python学习之错误整理: # 错误一:# TypeError: cannot concatenate 'str' and 'int' objects# 不能连接str和int对象age = 2 ...
- oracle12C--新特性
Orcle 12c 新特性-使用DBCA创建物理备库 >>点击这里<< Orcle 12c DG 新特性-Far Sync >>点击这里<< Orcle ...
- Oracle 客户端、服务器、数据库、数据库对象(表、视图等)的关系
1.数据库服务器 所谓数据库服务器,只是在机器上安装了一个数据库管理软件,这个软件可以管理多个数据库.一般开发人员会针对每一个应用创建一个数据库 2.单实例数据库模式下的数据库服务器.数据库.数据库实 ...
- SQL更新派工单数量=任务数量的
select b.FCommitQty '任务数量',a.FQty '派工数量',a.FSourceBillNo '派工单号',b.FBillNo '任务单号',a.FStatus '派工状态' fr ...
- mysql应用学习-在cmd命令窗口下创建数据库和表
运行以下操作,请确认您已经正确安装和配置了mysql. 首先要运行cmd.exe,进入命令窗口. step1. 进入MySQL monitor 如果您已登录mysql,可直接进入step2;若未登录请 ...
- JavaScript typeof运算符和数据类型
// js有6种数据类型:Undefined.Null.Boolean.String.Number.Object //(01)typeof console.log(typeof undefined); ...
- (四) HTML之表单元素
HTML中的表单元素,是构成动态网页的重要组成部分,因此,熟知表单元素是十分重要的.下面将根据表单中的一些常用标签进行介绍 1.单选按钮 <input type="radio" ...
- mybatis一对多映射
场景: A:SecControlRulePojo.java B:SecControlSubRulePojo C:SecControlSubRuleManyPojo 实体A中包含List<B> ...