Coursera 机器学习 第8章(下) Dimensionality Reduction 学习笔记
8 Dimensionality Reduction
8.3 Motivation
8.3.1 Motivation I: Data Compression
第二种无监督问题:维数约简(Dimensionality Reduction)。
通过维数约简可以实现数据压缩(Data Compression),数据压缩可以减少计算机内存使用,加快算法运算速度。
什么是维数约简:降维。若数据库X是属于n维空间的,通过特征提取或者特征选择的方法,将原空间的维数降至m维,要求n远大于m,满足:m维空间的特性能反映原空间数据的特征,这个过程称之为维数约简。
做道题:

C
8.3.2 Motivation II: Visualization
数据降维可以可视化数据,使得数据便于观察。
做道题:

BD
8.4 Principal Component Analysis
8.4.1 Principal Component Analysis Problem Formulation
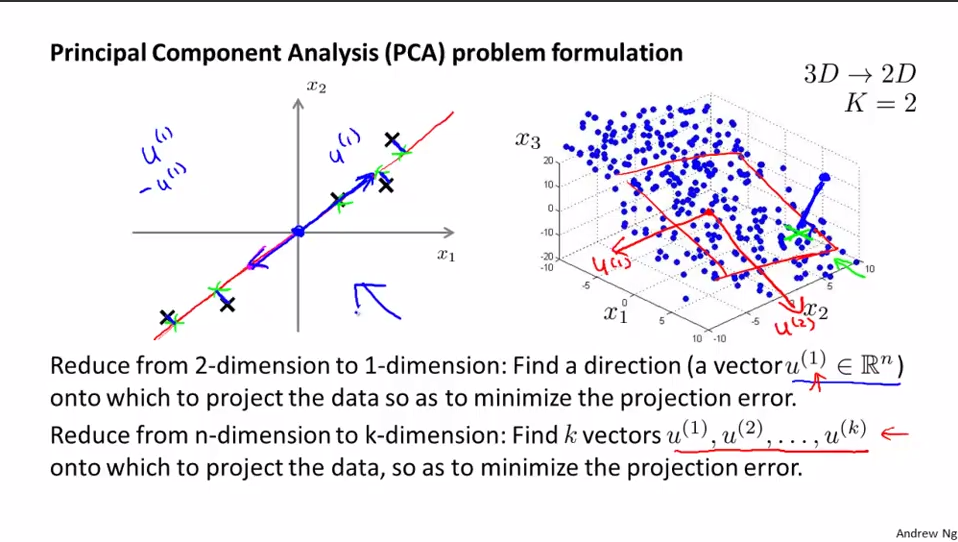
PCA的正式描述:将n维数据投影至由k个正交向量组成的线性空间(k维)并要求最小化投影误差(投影前后的点的距离)(Projection Error)的平方的一种无监督学习算法。
进行PCA之前,先进行均值归一化和特征规范化,使得数据在可比较的范围内。
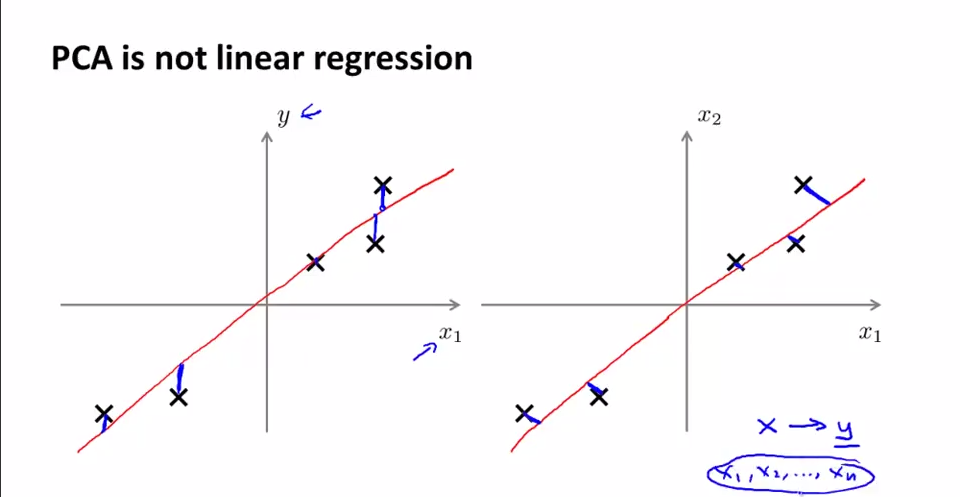
PCA和线性回归之间的关系。PCA不是线性回归。左图是线性回归,右图是PCA。几点不同:
1.最小化的目标不同。PCA衡量的是orthogonal distance, 而linear regression是所有x点对应的真实值y=g(x)与估计值f(x)之间的vertical distance距离。图中蓝线部分为各自最小化目标。
2.PCA中为的是寻找一个surface,将各feature{x1,x2,...,xn}投影到这个surface后使得各点间variance最大(跟y没有关系,是寻找最能够表现这些feature的一个平面);而Linear Regression是给出{x1,x2,...,xn},希望根据x去预测y。
8.4.2 Principal Component Analysis Algorithm
PCA的算法描述,如何将n维数据降至k维:
1.数据预处理。进行特征规范化(feature scaling)和均值归一化(mean normalization)。
均值归一化(mean normalization):对于某一特征j,求j特征下m个样本的均值uj=(Σm Xj(i)/m)/m,Xj(i)表示第i个样本的第j维特征的value。将m个样本的任一个样本i的j特征分量替换为x(i)j-uj。显然这时被替换掉的特征的均值为0。
特征缩放(feature scaling):当特征量的范围跨度很大时使用。x(i)j=(x(i)j-uj)/sj。sj可以是最大值-最小值或者是特征j的标准差。

2. 计算协方差矩阵sigma。对于整个数据集X,sigma=(1/m)*XT*X。X是m*n规模。
3.1 如何寻找这个surface?
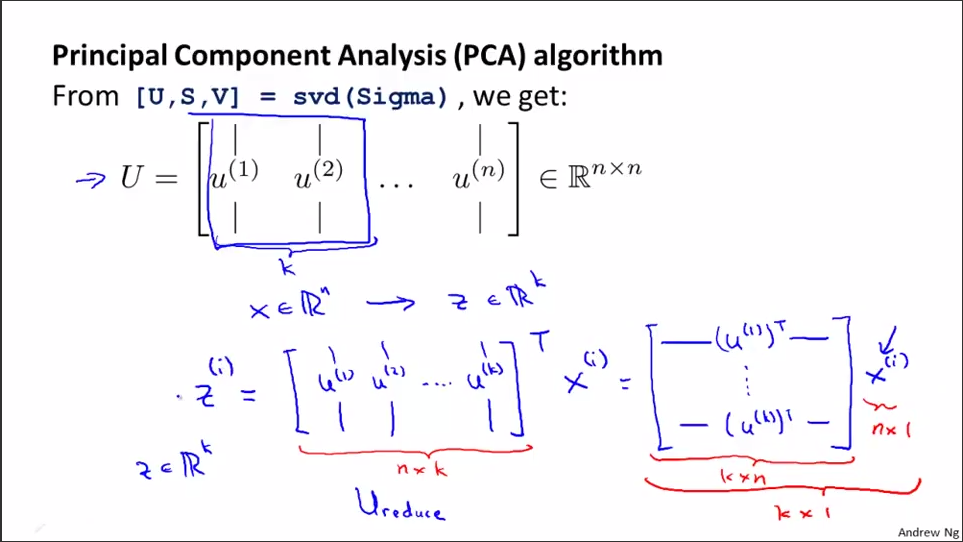
3.1.1 计算协方差矩阵的特征向量(eigenvectors)U。[U,S,V]=svd(sigma)。协方差均值满足对称正定(symmetric positive definite)。sigma和U的规模是n*n。其中,svd表示奇异值分解(singular value decomposition),比eig要稳定。在matlab中有函数[U,S,V] = svd(A) 返回一个与A同大小的对角矩阵S(由A的特征值组成),两个正交矩阵(实数化的酉矩阵)U和V,且满足A= U*S*V'。若A为m×n阵,则U为m×m阵,V为n×n阵。奇异值在S的对角线上,非负且按降序排列。
3.1.2 取U矩阵的前k列,记为Ureduce(n*k维),Ureduce是个正交矩阵。选出这n个特征中最重要的k个,也就是选出特征值最大的k个。
3.2 给定surface,怎样求点到surface投影的value?
3.2.1 Z=X*Ureduce。其中Z是m*k维的;X是m*n维的;Ureduce是n*k维;任一列x(i)没有x0=1一项,是X中的一个实例。
U是n维向量空间的基底,Z是n维数据集X变换至k维空间后对应的k维数据集(维度减少,个数不变)。
这里有个关于PCA算法上述实现数学证明,注意其中维度的变化:http://www.360doc.com/content/13/1124/02/9482_331688889.shtml

也可以看下面的2个图,和上面讲的相同。

做道题:

D
8.5 Applying PCA
8.5.1 Reconstruction from Compressed Representation
将压缩后的低纬度数据还原成原始高维度的方法:重构(Reconstruction)。这里的还原只是近似还原。
具体而言:
1. Z=X*Ureduce,所以只要X*Ureduce*Ureduce-1=Z*Ureduce-1就可以还原了。
2. Ureduce正交矩阵,满足Ureduce-1=UreduceT。
所以映射值Xapprox=X*Ureduce*Ureduce-1==Z*Ureduce-1==Z*UreduceT。这里Z是m*k维;Ureduce是n*k维。
做道题:

ABC
8.5.2 Choosing the Number of Principal Components
如何确定主成分的数量k。
理论上,不断尝试每个k=i(i≤n),计算下式(a):
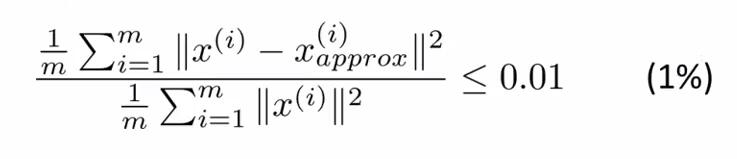
由小到大,取第一个满足(a)式的k的值为主成成分的k。
注意:
1.(a)式的分母是数据的总变差(Total Varuation)。
2.(a)式的分子是x和其映射值之间的平均距离。
3.x(i)approx是还原以后的数据。
4.式子右侧的0.01是可变的,可以取0.05,0.1等,用来衡量保留多少主成成分的指标。取0.01,意思是当前k值下,保留了99%的差异性。也是平方投影误差的测量指标,是衡量是否对原始数据做了一个好的近似的标准。
由于实际中的特征量通常具有高度相关性,所以压缩后保留99%的差异性还是有可能的。
但实际上不需要依次尝试不同的k下的(a)式的值来决定是否采用k。
[U,S,V]=svd(Sigma)中得到的S是一个对角矩阵,这里可以证明(1)和(2)等价(也可以这么理解,Sii表示的是数据从n维映射到k维以后的数据在第i维的方差,也就是映射以后数据在第i维的离散程度。(1)和(2)表示的都是映射以后的数据还保留原数据特征的程度大小,(1)从数据分布的离散程度,(2)从数据的可恢复程度):
(1)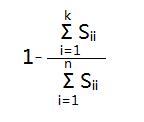
(2)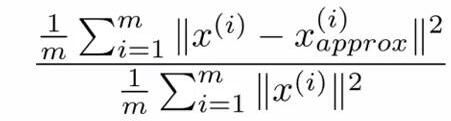
所以只要用(1)代替(2)嵌入到不同k的循环中就可以了。比如原来是求第一个满足(2)≤0.01的k值,那么就可以等价为第一个满足(1)≤0.01的k值。这样就简单很多。

做道题:

C
8.5.3 Advice for Applying PCA
PCA如何提高机器学习算法的速度并提供一些应用PCA的建议。
将PCA用于监督学习的加速。将训练集抽去对应标签y,对无标签的训练集运行PCA,可以得到映射关系。后期可以将这个关系用于交叉验证集和测试集,但不能用交叉验证集和测试集训练这个映射关系。

PCA的应用:数据压缩和可视化数据。

关于PCA的误用:
1.不能使用PCA来避免过拟合。如果要避免过拟合,还是要使用正则化技术。因为PCA实现时,不需要顾及样本的标签y,这意味着PCA丢弃了一些信息。PCA是在对数据标签毫不知情的情况下对数据进行降维。
2.不要盲目使用PCA。对于特定算法,可以先不使用PCA看一下运行效果,只有当算法收敛得非常慢,占用内存非常厉害,也就是x(i)的效果真的不好的时候,再考虑使用PCA。
做道题:

ABD
练习:
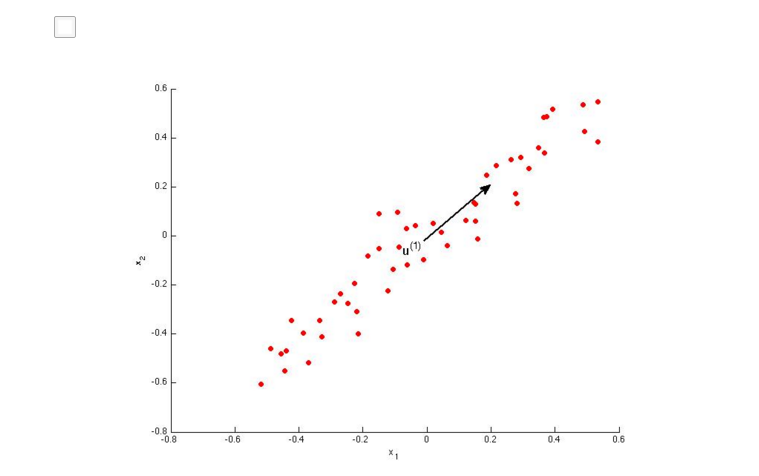
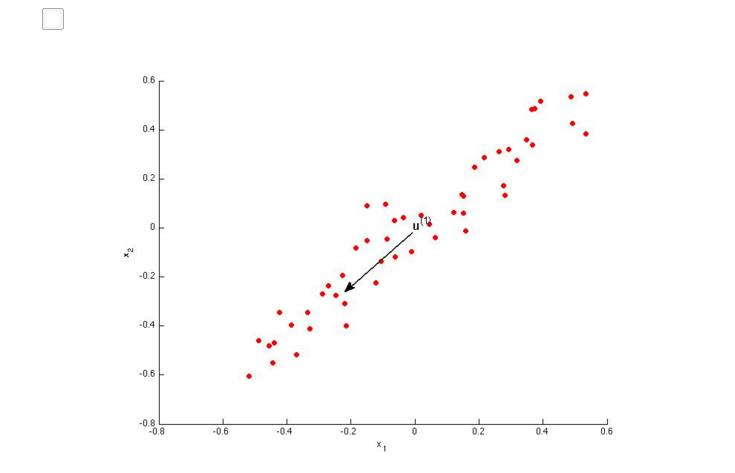
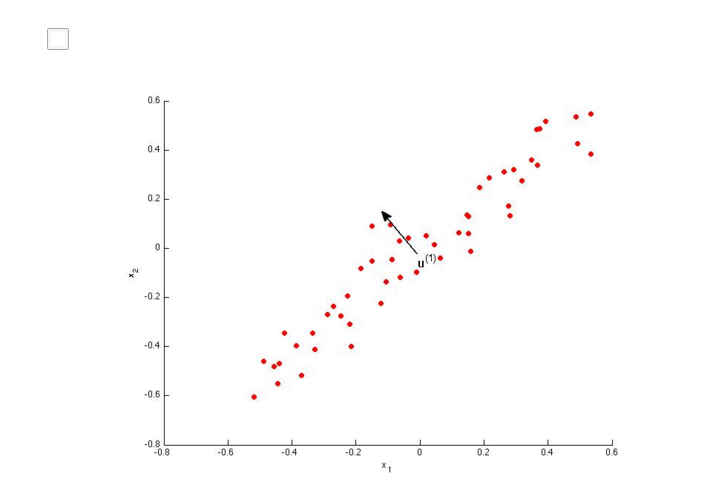
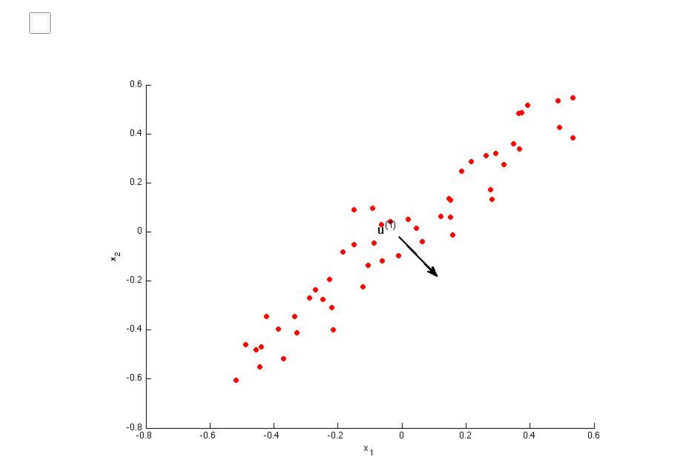
AB

B

C

BD

AB
Coursera 机器学习 第8章(下) Dimensionality Reduction 学习笔记的更多相关文章
- Coursera 机器学习 第7章 Support Vector Machines 学习笔记
7 Support Vector Machines7.1 Large Margin Classification7.1.1 Optimization Objective支持向量机(SVM)代价函数在数 ...
- Coursera 机器学习 第5章 Neural Networks: Learning 学习笔记
5.1节 Cost Function神经网络的代价函数. 上图回顾神经网络中的一些概念: L 神经网络的总层数. sl 第l层的单元数量(不包括偏差单元). 2类分类问题:二元分类和多元分类. 上 ...
- 【机器学习】决策树(Decision Tree) 学习笔记
[机器学习]决策树(decision tree) 学习笔记 标签(空格分隔): 机器学习 决策树简介 决策树(decision tree)是一个树结构(可以是二叉树或非二叉树).其每个非叶节点表示一个 ...
- 机器学习(十)-------- 降维(Dimensionality Reduction)
降维(Dimensionality Reduction) 降维的目的:1 数据压缩 这个是二维降一维 三维降二维就是落在一个平面上. 2 数据可视化 降维的算法只负责减少维数,新产生的特征的意义就必须 ...
- Coursera 机器学习 第6章(下) Machine Learning System Design 学习笔记
Machine Learning System Design下面会讨论机器学习系统的设计.分析在设计复杂机器学习系统时将会遇到的主要问题,给出如何巧妙构造一个复杂的机器学习系统的建议.6.4 Buil ...
- Coursera 机器学习 第9章(下) Recommender Systems 学习笔记
9.5 Predicting Movie Ratings9.5.1 Problem Formulation推荐系统.推荐系统的问题表述:电影推荐.根据用户对已看过电影的打分来推测用户对其未打分的电影将 ...
- Coursera 机器学习 第6章(上) Advice for Applying Machine Learning 学习笔记
这章的内容对于设计分析假设性能有很大的帮助,如果运用的好,将会节省实验者大量时间. Machine Learning System Design6.1 Evaluating a Learning Al ...
- Coursera 机器学习 第9章(上) Anomaly Detection 学习笔记
9 Anomaly Detection9.1 Density Estimation9.1.1 Problem Motivation异常检测(Density Estimation)是机器学习常见的应用, ...
- Coursera 机器学习 第8章(上) Unsupervised Learning 学习笔记
8 Unsupervised Learning8.1 Clustering8.1.1 Unsupervised Learning: Introduction集群(聚类)的概念.什么是无监督学习:对于无 ...
随机推荐
- 做ETL的时候用到的数据同步更新代码
这里是用的从一个库同步到另一个库,代码如下 private void IncrementalSyncUpdate(string fromConn, string toConn, Dictionary& ...
- c#设计模式之:组合模式(Composite)
一:引言 在软件开发过程中,我们经常会遇到处理简单对象和复合对象的情况,例如对操作系统中目录的处理,因为目录客园包括单独的文件,也可以包括文件夹,文件夹又是由文件组成的,由于简单对象和复合对象在功能上 ...
- Tensorflow报错:InvalidArgumentError: You must feed a value for placeholder tensor 'input_y' with dtype
此错误神奇之处是每次第一次运行不会报错,第二次.第三次第四次....就都报错了.关掉重启,又不报错了,运行完再运行一次立马报错!搞笑! 折磨了我半天,终于被我给解决了! 问题解决来源于这边博客:htt ...
- 单元测试unittest
unittest.TestSuite():用例集合 uinttest.defaultTestLoader.discover():寻找测试用例,去哪个目录下寻找测试用例,加载测试用例
- [Swift实际操作]八、实用进阶-(10)使用Swift创建一个二叉树BinaryTreeNode
1.二叉树的特点: (1).每个节点最多有两个子树(2).左子树和右子树是有顺序的,次序不能颠倒(3).即使某节点只有一个子树,也要区分左右子树 2.二叉查找树(Binary Search Tree) ...
- The server of Apache (一)——apache服务的基本安装过程
一.为了避免端口冲突,需要卸载linux系统中以RPM方式安装的httpd ~] # rpm -qa | grep httpd ~] # rpm -e httpd --nodeps (此处nodeps ...
- eclipse创建springmvc项目
一.在eclipse中创建maven-archetype-webapp项目: 1.新建项目选择maven项目 2.默认,下一步 3.选择maven-archetype-webapp,其他保持默认即可 ...
- 修复win10无法双击打开txt文档.reg
Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\.txt]@="txtfile""Content Type& ...
- Python中lambda表达式
一.lambda表达式形式 lambda后面跟一个或多个参数,紧跟一个冒号,以后是一个表达式.冒号前是参数,冒号后是返回值. lambda是一个表达式而不是一个语句. lambda表达式可以出现在Py ...
- Call requires API level 11 (current min is 8)报错
新建一个Android Application Project,其中MainActivity.java中报错如下 Call requires API level 11(current min is 8 ...