spark学习2-1(hive1.2安装)
由于前面安装版本过老,导致学习过程中出现了很多问题,今天安装了一个新一点的版本。安装结束启动时遇到一点问题,记录在这里。
第一步:hive-1.2安装
通过WinSCP将apache-hive-1.2.1-bin.tar.gz上传到/usr/hive/目录下
[root@spark1 hive]# chmod u+x apache-hive-1.2.1-bin.tar.gz #增加执行权限
[root@spark1 hive]# tar -zxvf apache-hive-1.2.1-bin.tar.gz #解压
[root@spark1 hive]# mv apache-hive-1.2.1-bin hive-1.2
[root@spark1 hive]# vi /etc/profile #配置环境变量
export HIVE_HOME=/usr/hive/hive-1.2
export PATH=$HIVE_HOME/bin
[root@spark1 hive]# source /etc/profile #是环境变量生效
[root@spark1 hive]# which hive #查看安装路径
第二步:安装mysql
[root@spark1 hive]# yum install -y mysql-server #下载安装
[root@spark1 hive]# service mysqld start #启动mysql
[root@spark1 hive]# chkconfig mysqld on #设置开机自动启动
[root@spark1 hive]# yum install -y mysql-connector-java #yum安装mysql connector
[root@spark1 hive]# cp /usr/share/java/mysql-connector-java-5.1.17.jar /usr/hive/hive-0.13/lib #拷贝到hive中的lib目录下
第三步:在mysql上创建hive元数据库,并对hive进行授权
mysql> create database if not exists hive_metadata;
mysql> grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
mysql> grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
mysql> grant all privileges on hive_metadata.* to 'hive'@'spark1' identified by 'hive';
mysql> flush privileges;
mysql> use hive_metadata;
mysql> exit
第四步:配置文件
[root@spark1 hive]# cd /usr/hive/hive-1.2/conf #进入到conf目录
[root@spark1 conf]# mv hive-default.xml.template hive-site.xml #重命名
[root@spark1 conf]# vi hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://spark1:3306/hive_metadata?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
[root@spark1 conf]# mv hive-env.sh.template hive-env.sh #重命名
[root@spark1 ~]# vi /usr/hive/hive-1.2/bin/hive-config.sh #加入java、hive、hadoop 路径
export JAVA_HOME=/usr/java/jdk1.8
export HIVE_HOME=/usr/hive/hive-1.2
export HADOOP_HOME=/usr/hadoop/hadoop-2.6.0
[hadoop@spark1 hive]$ cd hive-1.2
[hadoop@spark1 hive-1.2]$ hive #进入hive开始使用
测试hive
hive> hive;
启动报错
Exception in thread "main" java.lang.RuntimeException: java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: \({system:java.io.tmpdir%7D/\)%7Bsystem:user.name%7D
启动hive-1.2报错1
Exception in thread "main" java.lang.RuntimeException: java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: \({system:java.io.tmpdir%7D/\)%7Bsystem:user.name%7D
解决办法
将hive-site.xml中三个含有system:java.io.tmpdir配置项的值修改为 $HIVE_HOME/iotmp 即:
/usr/hive/hive-1.2/iotmp
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/hive/hive-1.2/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/hive/hive-1.2/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/hive/hive-1.2/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
搞定1之后报错2
[ERROR] Terminal initialization failed; falling back to unsupported
原因是hadoop目录下存在老版本jline:
/usr/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib/jline-0.9.94.jar
解决方法:
将hive目录/usr/hive/hive-1.2/lib下的新版本jline的JAR包拷贝到hadoop下:
cp jline-2.12.jar /usr/hadoop/hadoop-2.6.0/share/hadoop/yarn/lib
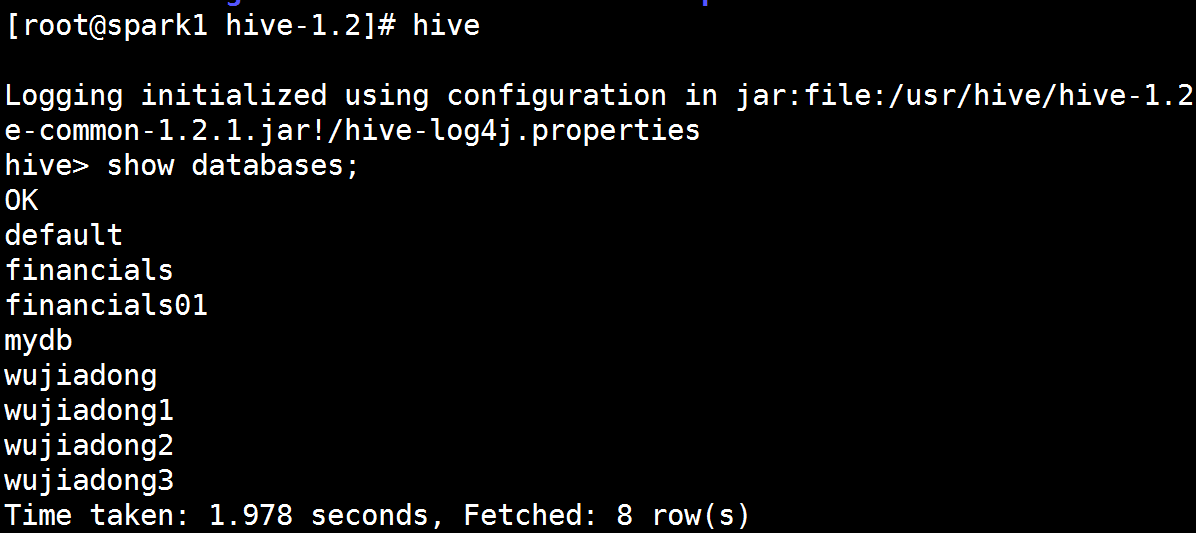
结果如下图

spark学习2-1(hive1.2安装)的更多相关文章
- spark学习(2)--hadoop安装、配置
环境: 三台机器 ubuntu14.04 hadoop2.7.5 jdk-8u161-linux-x64.tar.gz (jdk1.8) 架构: machine101 :名称节点.数据节点.Secon ...
- spark学习2(hive0.13安装)
第一步:hive安装 通过WinSCP将apache-hive-0.13.1-bin.tar.gz上传到/usr/hive/目录下 [root@spark1 hive]# chmod u+x apac ...
- Spark学习(一) -- Spark安装及简介
标签(空格分隔): Spark 学习中的知识点:函数式编程.泛型编程.面向对象.并行编程. 任何工具的产生都会涉及这几个问题: 现实问题是什么? 理论模型的提出. 工程实现. 思考: 数据规模达到一台 ...
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
- 用Spark学习FP Tree算法和PrefixSpan算法
在FP Tree算法原理总结和PrefixSpan算法原理总结中,我们对FP Tree和PrefixSpan这两种关联算法的原理做了总结,这里就从实践的角度介绍如何使用这两个算法.由于scikit-l ...
- 用Spark学习矩阵分解推荐算法
在矩阵分解在协同过滤推荐算法中的应用中,我们对矩阵分解在推荐算法中的应用原理做了总结,这里我们就从实践的角度来用Spark学习矩阵分解推荐算法. 1. Spark推荐算法概述 在Spark MLlib ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- spark 学习路线及参考课程
一.Scala编程详解: 第1讲-Spark的前世今生 第2讲-课程介绍.特色与价值 第3讲-Scala编程详解:基础语法 第4讲-Scala编程详解:条件控制与循环 第5讲-Scala编程详解:函数 ...
- spark学习及环境配置
http://dblab.xmu.edu.cn/blog/spark/ 厦大数据库实验室博客 总结.分享.收获 实验室主页 首页 大数据 数据库 数据挖掘 其他 子雨大数据之Spark入门教程 林子 ...
随机推荐
- java内部类详细介绍
0.内部类与一般类有所不同,它是放在外部类的内部即可作为外部类的成员变量,也可放在方法内部作为局部变量,既然是变量,那么它可以用 private static 修饰符修饰,而外部类则不能,这也是内部类 ...
- javaScript Number对象
Number 对象 Number 对象是原始数值的包装对象. 创建 Number 对象的语法: var myNum=new Number(value); var myNum=Number(value) ...
- iOS CGAffineTransform你了解多少?
CGAffineTransform介绍 概述 CGAffineTransform是一个用于处理形变的类,其可以改变控件的平移.缩放.旋转等,其坐标系统采用的是二维坐标系,即向右为x轴正方向,向下为y轴 ...
- python字符串拼接相关
#字符串拼接#str.join(元组.列表.字典.字符串) 之后生成的只能是字符串.str = "-";seq = ("a", "b", & ...
- event对象及各种事件
事件(event) event对象 (1)什么是event对象? Event 对象代表事件的状态,比如事件在其中发生的元素.键盘按键的状态.鼠标的位置.鼠标按钮的状态.事件通常与函数结合使用,函数不会 ...
- git的安装-环境变量配置
windows安装git和环境变量配置 2015.10.12 评论(0) 10,729 点此嗨一下 Git是一款免费.开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目. Git是一个开源 ...
- PowerPC架构与X86架构
PowerPC架构 PowerPC是一种精简指令集(RISC)架构的中央处理器(CPU),其基本的设计源自IBM(国际商用机器公司)的POWER(Performance Optimized With ...
- Get Region Information from IP Address with Taobao API
通过淘宝的API "http://ip.taobao.com/service/getIpInfo.php?ip=*.*.*.*" 来获得你要查询的IP地址的国家,地区,城市,ISP ...
- openstack ocata版(脚本)控制节点安装
一.初始化环境: 1.更换yum源: yum install -y wget mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS- ...
- 前端 css续
CSS选择器 1.标签选择器 为类型标签设置样式例如:<div>.<a>.等标签设置一个样式,代码如下: <style> /*标签选择器,找到所有的标签应用以下样式 ...