ConcurrentHashMap的JDK1.8实现
今天我们介绍一下ConcurrentHashMap在JDK1.8中的实现。
基本结构
ConcurrentHashMap在1.8中的实现,相比于1.7的版本基本上全部都变掉了。首先,取消了Segment分段锁的数据结构,取而代之的是数组+链表(红黑树)的结构。而对于锁的粒度,调整为对每个数组元素加锁(Node)。然后是定位节点的hash算法被简化了,这样带来的弊端是Hash冲突会加剧。因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。这样一来,查询的时间复杂度就会由原先的O(n)变为O(logN)。下面是其基本结构:
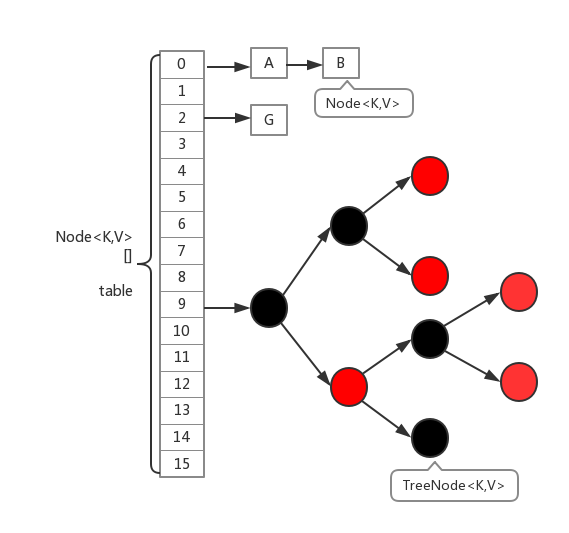
相关属性
- private transient volatile int sizeCtl;
sizeCtl用于table[]的初始化和扩容操作,不同值的代表状态如下:
- -1:table[]正在初始化。
- -N:表示有N-1个线程正在进行扩容操作。
非负情况:
- 如果table[]未初始化,则表示table需要初始化的大小。
- 如果初始化完成,则表示table[]扩容的阀值,默认是table[]容量的0.75 倍。
- private static finalint DEFAULT_CONCURRENCY_LEVEL = 16;
- DEFAULT_CONCURRENCY_LEVEL:表示默认的并发级别,也就是table[]的默认大小。
- private static final float LOAD_FACTOR = 0.75f;
- LOAD_FACTOR:默认的负载因子。
- static final int TREEIFY_THRESHOLD = 8;
- TREEIFY_THRESHOLD:链表转红黑树的阀值,当table[i]下面的链表长度大于8时就转化为红黑树结构。
- static final int UNTREEIFY_THRESHOLD = 6;
- UNTREEIFY_THRESHOLD:红黑树转链表的阀值,当链表长度<=6时转为链表(扩容时)。
构造函数
- public ConcurrentHashMap(int initialCapacity,
- float loadFactor, int concurrencyLevel) {
- if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
- throw new IllegalArgumentException();
- if (initialCapacity < concurrencyLevel) // 初始化容量至少要为concurrencyLevel
- initialCapacity = concurrencyLevel;
- long size = (long)(1.0 + (long)initialCapacity / loadFactor);
- int cap = (size >= (long)MAXIMUM_CAPACITY) ?
- MAXIMUM_CAPACITY : tableSizeFor((int)size);
- this.sizeCtl = cap;
- }
从上面代码可以看出,在创建ConcurrentHashMap时,并没有初始化table[]数组,只对Map容量,并发级别等做了赋值操作。
相关节点
- Node:该类用于构造table[],只读节点(不提供修改方法)。
- TreeBin:红黑树结构。
- TreeNode:红黑树节点。
- ForwardingNode:临时节点(扩容时使用)。
put()操作
- public V put(K key, V value) {
- return putVal(key, value, false);
- }
- final V putVal(K key, V value, boolean onlyIfAbsent) {
- if (key == null || value == null) throw new NullPointerException();
- int hash = spread(key.hashCode());
- int binCount = 0;
- for (Node<K,V>[] tab = table;;) {
- Node<K,V> f; int n, i, fh;
- if (tab == null || (n = tab.length) == 0)// 若table[]未创建,则初始化
- tab = initTable();
- else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// table[i]后面无节点时,直接创建Node(无锁操作)
- if (casTabAt(tab, i, null,
- new Node<K,V>(hash, key, value, null)))
- break; // no lock when adding to empty bin
- }
- else if ((fh = f.hash) == MOVED)// 如果当前正在扩容,则帮助扩容并返回最新table[]
- tab = helpTransfer(tab, f);
- else {// 在链表或者红黑树中追加节点
- V oldVal = null;
- synchronized (f) {// 这里并没有使用ReentrantLock,说明synchronized已经足够优化了
- if (tabAt(tab, i) == f) {
- if (fh >= 0) {// 如果为链表结构
- binCount = 1;
- for (Node<K,V> e = f;; ++binCount) {
- K ek;
- if (e.hash == hash &&
- ((ek = e.key) == key ||
- (ek != null && key.equals(ek)))) {// 找到key,替换value
- oldVal = e.val;
- if (!onlyIfAbsent)
- e.val = value;
- break;
- }
- Node<K,V> pred = e;
- if ((e = e.next) == null) {// 在尾部插入Node
- pred.next = new Node<K,V>(hash, key,
- value, null);
- break;
- }
- }
- }
- else if (f instanceof TreeBin) {// 如果为红黑树
- Node<K,V> p;
- binCount = 2;
- if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
- value)) != null) {
- oldVal = p.val;
- if (!onlyIfAbsent)
- p.val = value;
- }
- }
- }
- }
- if (binCount != 0) {
- if (binCount >= TREEIFY_THRESHOLD)// 到达阀值,变为红黑树结构
- treeifyBin(tab, i);
- if (oldVal != null)
- return oldVal;
- break;
- }
- }
- }
- addCount(1L, binCount);
- return null;
- }
从上面代码可以看出,put的步骤大致如下:
- 参数校验。
- 若table[]未创建,则初始化。
- 当table[i]后面无节点时,直接创建Node(无锁操作)。
- 如果当前正在扩容,则帮助扩容并返回最新table[]。
- 然后在链表或者红黑树中追加节点。
- 最后还回去判断是否到达阀值,如到达变为红黑树结构。
除了上述步骤以外,还有一点我们留意到的是,代码中加锁片段用的是synchronized关键字,而不是像1.7中的ReentrantLock。这一点也说明了,synchronized在新版本的JDK中优化的程度和ReentrantLock差不多了。
get()操作
- public V get(Object key) {
- Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
- int h = spread(key.hashCode());// 定位到table[]中的i
- if ((tab = table) != null && (n = tab.length) > 0 &&
- (e = tabAt(tab, (n - 1) & h)) != null) {// 若table[i]存在
- if ((eh = e.hash) == h) {// 比较链表头部
- if ((ek = e.key) == key || (ek != null && key.equals(ek)))
- return e.val;
- }
- else if (eh < 0)// 若为红黑树,查找树
- return (p = e.find(h, key)) != null ? p.val : null;
- while ((e = e.next) != null) {// 循环链表查找
- if (e.hash == h &&
- ((ek = e.key) == key || (ek != null && key.equals(ek))))
- return e.val;
- }
- }
- return null;// 未找到
- }
get()方法的流程相对简单一点,从上面代码可以看出以下步骤:
- 首先定位到table[]中的i。
- 若table[i]存在,则继续查找。
- 首先比较链表头部,如果是则返回。
- 然后如果为红黑树,查找树。
- 最后再循环链表查找。
从上面步骤可以看出,ConcurrentHashMap的get操作上面并没有加锁。所以在多线程操作的过程中,并不能完全的保证一致性。这里和1.7当中类似,是弱一致性的体现。
size()操作
- // 1.2时加入
- public int size() {
- long n = sumCount();
- return ((n < 0L) ? 0 :
- (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
- (int)n);
- }
- // 1.8加入的API
- public long mappingCount() {
- long n = sumCount();
- return (n < 0L) ? 0L : n; // ignore transient negative values
- }
- final long sumCount() {
- CounterCell[] as = counterCells; CounterCell a;
- long sum = baseCount;
- if (as != null) {
- for (int i = 0; i < as.length; ++i) {
- if ((a = as[i]) != null)
- sum += a.value;
- }
- }
- return sum;
- }
从上面代码可以看出来,JDK1.8中新增了一个mappingCount()的API。这个API与size()不同的就是返回值是Long类型,这样就不受Integer.MAX_VALUE的大小限制了。
两个方法都同时调用了,sumCount()方法。对于每个table[i]都有一个CounterCell与之对应,上面方法做了求和之后就返回了。从而可以看出,size()和mappingCount()返回的都是一个估计值。(这一点与JDK1.7里面的实现不同,1.7里面使用了加锁的方式实现。这里面也可以看出JDK1.8牺牲了精度,来换取更高的效率。)
ConcurrentHashMap的JDK1.8实现的更多相关文章
- Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进(转)
一.简单回顾ConcurrentHashMap在jdk1.7中的设计 先简单看下ConcurrentHashMap类在jdk1.7中的设计,其基本结构如图所示: 每一个segment都是一个HashE ...
- Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进
一.简单回顾ConcurrentHashMap在jdk1.7中的设计 先简单看下ConcurrentHashMap类在jdk1.7中的设计,其基本结构如图所示: 每一个segment都是一个HashE ...
- ConcurrentHashMap基于JDK1.8源码剖析
前言 声明,本文用的是jdk1.8 前面章节回顾: Collection总览 List集合就这么简单[源码剖析] Map集合.散列表.红黑树介绍 HashMap就是这么简单[源码剖析] LinkedH ...
- 源码分析(4)-ConcurrentHashMap(JDK1.8)
一.UML类图 ConcurrentHashMap键值不能为null:底层数据结构是数组+链表/红黑二叉树:采用CAS(比较并交换)和synchronized来保证并发安全. CAS文章:https: ...
- ConcurrentHashMap (jdk1.7)源码学习
一.介绍 1.Segment(分段锁) 1.1 Segment 容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并 ...
- 多线程之并发容器ConcurrentHashMap(JDK1.6)
简介 ConcurrentHashMap 是 util.concurrent 包的重要成员.本文将结合 Java 内存模型,分析 JDK 源代码,探索 ConcurrentHashMap 高并发的具体 ...
- java 并发容器一之ConcurrentHashMap(基于JDK1.8)
上一篇文章简单的写了一下,BoundedConcurrentHashMap,觉得https://www.cnblogs.com/qiaoyutao/p/10903813.html用的并不多:今天着重写 ...
- 【JUC】JDK1.8源码分析之ConcurrentHashMap(一)
一.前言 最近几天忙着做点别的东西,今天终于有时间分析源码了,看源码感觉很爽,并且发现ConcurrentHashMap在JDK1.8版本与之前的版本在并发控制上存在很大的差别,很有必要进行认真的分析 ...
- ConcurrentHashmap详解以及在JDK1.8的更新
因为hashmap本身是非线程安全的,如果多线程对hashmap进行put操作的话,就会导致死循环等现象.ConcurrentHashMap主要就是为了应对hashmap在并发环境下不安全而诞生的,C ...
随机推荐
- [Contest20180311]朋友
是毒瘤的friends呢~ 注意到“产生感情”和后缀自动机的$Right$集合定义很像,所以先对所有串建广义sam,那么一个节点$s$里的所有串都互相产生感情,而从起点走到$s$走最长路所经过的节点里 ...
- 【2-SAT】Codeforces Round #403 (Div. 2, based on Technocup 2017 Finals) D. Innokenty and a Football League
先反复地扫(不超过n次),把所有可以确定唯一取法的给确定下来. 然后对于剩下的不能确定的,跑2-SAT.输出可行解时,对于a和¬a,如果a所在的强连通分量序号在¬a之前,则取a,否则不取a.如果a和¬ ...
- 【博弈论】【SG函数】【找规律】Divide by Zero 2017 and Codeforces Round #399 (Div. 1 + Div. 2, combined) E. Game of Stones
打表找规律即可. 1,1,2,2,2,3,3,3,3,4,4,4,4,4... 注意打表的时候,sg值不只与剩下的石子数有关,也和之前取走的方案有关. //#include<cstdio> ...
- 【R笔记】R的内存管理和垃圾清理
笔记: 1.R输入命令时速度不要太快,终究是个统计软件,不是编程! 2.memory.limit()查看当前操作系统分配内存给R的最大限度(单位是M?) 3.要经常 rm(object) 或者 rm( ...
- apk打包
1.在导航栏中选择Builder->Generate Signed Apk 2.新建点击Creat new... 3.注意路径后面写apk的名字(这个名字将会显示在手机软件的下方)
- HDU 4606 Occupy Cities (计算几何+最短路+二分+最小路径覆盖)
Occupy Cities Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- Admin Finder
#Created for coded32 and his teamopenfire Eliminated Some bugs from my last code shared here as Gues ...
- javascript快速入门20--Cookie
Cookie 基础知识 我们已经知道,在 document 对象中有一个 cookie 属性.但是 Cookie 又是什么?“某些 Web 站点在您的硬盘上用很小的文本文件存储了一些信息,这些文件就称 ...
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
一.介绍 本例子用Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据()的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯 ...
- Scala快学笔记(三)
一 ,文件操作: 1,读取行:val source=Source.fromFile("fileName","utf-8) 形成一个字符串:source.mkString ...