如何用Python做自动化特征工程
机器学习的模型训练越来越自动化,但特征工程还是一个漫长的手动过程,依赖于专业的领域知识,直觉和数据处理。而特征选取恰恰是机器学习重要的先期步骤,虽然不如模型训练那样能产生直接可用的结果。本文作者将使用Python的featuretools库进行自动化特征工程的示例。
机器学习越来越多地从手动设计模型转变为使用H20,TPOT和auto-sklearn等工具来自动优化的渠道。这些库以及随机搜索等方法旨在通过查找数据集的最优模型来简化模型选择和转变机器学习的部分,几乎不需要人工干预。然而,特征工程几乎完全是人工,这无疑是机器学习管道中更有价值的方面。
特征工程也称为特征创建,是从现有数据构建新特征以训练机器学习模型的过程。这个步骤可能比实际应用的模型更重要,因为机器学习算法只从我们提供的数据中学习,然而创建与任务相关的特征绝对是至关重要的。
通常,特征工程是一个漫长的手动过程,依赖于专业的领域知识,直觉和数据处理。这个过程可能非常繁琐,而且最终的特征将受到人类主观性和时间的限制。自动化特征工程旨在通过从数据集中自动创建许多候选特征来帮助数据科学家,并从中可以选择最佳特征用于训练。
在本文中,我们将使用Python 的featuretools库进行自动化特征工程的示例。我们将使用示例数据集来演示基础知识。
特征工程基础
特征工程意味着从现有数据中构建额外特征,这些数据通常分布在多个相关表中。特征工程需要从数据中提取相关信息并将其放入单个表中,然后可以使用该表来训练机器学习模型。
构建特征的过程非常地耗时,因为每个特征的构建通常需要一些步骤来实现,尤其是使用多个表中的信息时。我们可以将特征创建的步骤分为两类:转换和聚合。让我们看几个例子来了解这些概念的实际应用。
转换作用于单个表(从Python角度来看,表只是一个Pandas 数据框),它通过一个或多个现有的列创建新特征。
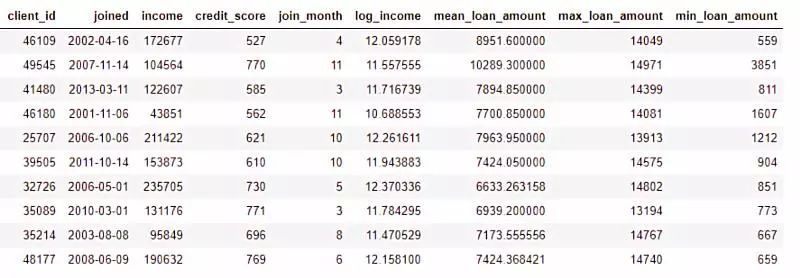
例如,如果我们有如下客户表。

我们可以通过查找joined列的月份或是获取income列的自然对数来创建特征。这些都是转换,因为它们仅使用来自一个表的信息。
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)

另一方面,聚合作用于多个表,并使用一对多的关系对观测值进行分组,然后计算统计数据。例如,如果我们有另一个包含客户贷款的信息表格,其中每个客户可能有多笔贷款,我们可以计算每个客户的贷款的平均值,最大值和最小值等统计数据。
此过程包括通过客户信息对贷款表进行分组,计算聚合,然后将结果数据合并到客户数据中。以下是我们如何使用Pandas库在Python中执行此操作。
这些操作本身并不困难,但如果我们有数百个变量分布在几十个表中,那么这个过程要通过手工完成是不可行的。理想情况下,我们需要一种能够跨多个表自动执行转换和聚合的解决方案,并将结果数据合并到一个表中。尽管Pandas库是一个很好的资源,但通过我们手工完成的数据操作是有限的。
Featuretools
幸运的是,featuretools正是我们正在寻找的解决方案。这个开源Python库将自动从一组相关表中创建许多特征。Featuretools基于一种称为“深度特征合成”的方法,这个名字听起来比实际的用途更令人印象深刻
深度特征合成实现了多重转换和聚合操作(在featuretools的词汇中称为特征基元),通过分布在许多表中的数据来创建特征。像机器学习中的大多数观念一样,它是建立在简单概念基础上的复合型方法。通过一次学习一个构造块的示例,我们就会容易理解这种强大的方法。
首先,我们来看看我们的示例数据。 我们已经看到了上面的一些数据集,完整的表集合如下:
客户:即有关信贷联盟中客户的基本信息。每个客户在此数据框中只有一行。
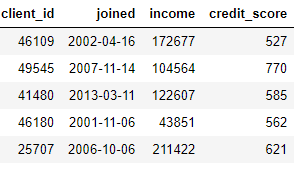
贷款:即客户贷款。每项贷款在此数据框中只有自己单独一行的记录,但客户可能有多项贷款。
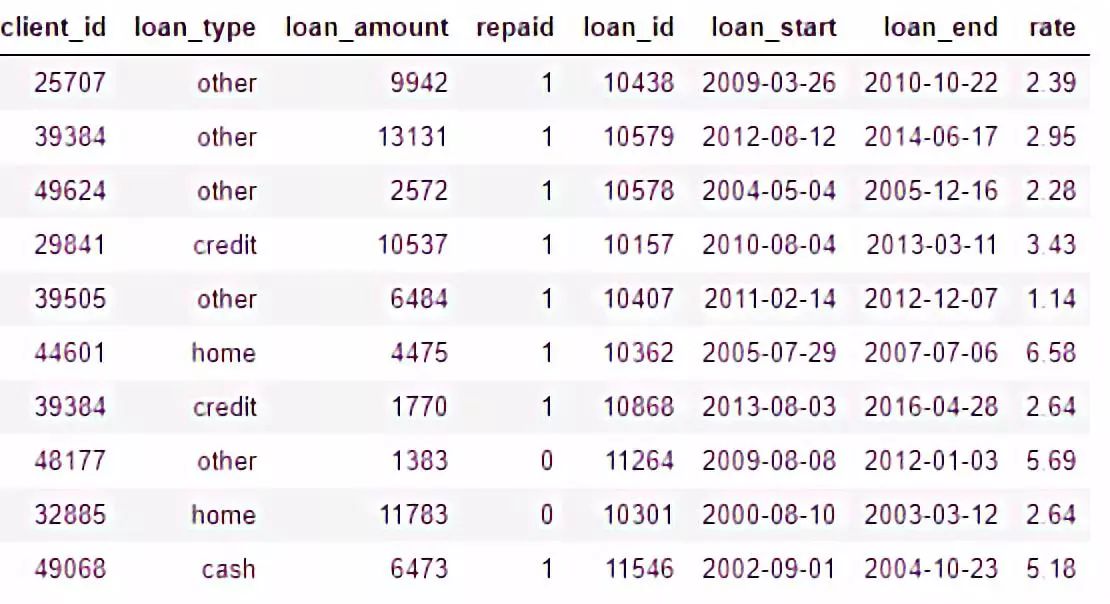
付款:即支付贷款。 每笔支付只有一行记录,但每笔贷款都有多笔支付记录。

如果我们有机器学习目标,例如预测客户是否将偿还未来贷款,我们希望将有关客户的所有信息组合到一个表中。这些表是相关的(通过client_id和loan_id变量),目前我们可以手动完成一系列转换和聚合过程。然而,不久之后我们就可以使用featuretools来自动化该过程。
实体和实体集
featuretools的前两个概念是实体和实体集。实体只是一个表(如果用Pandas库的概念来理解,实体是一个DataFrame(数据框))。
EntitySet(实体集)是表的集合以及它们之间的关系。可以将实体集视为另一个Python数据结构,该结构具有自己的方法和属性。)
我们可以使用以下命令在featuretools中创建一个空实体集:
import featuretools as ft
# Create new entityset
es = ft.EntitySet(id = 'clients')
现在我们添加实体。每个实体都必须有一个索引,该索引是一个包含所有唯一元素的列。也就是说,索引中的每个值只能出现在表中一次。
clients数据框中的索引是client_id,因为每个客户在此数据框中只有一行。 我们使用以下语法将一个现有索引的实体添加到实体集中:
# Create an entity from the client dataframe
# This dataframe already has an index and a time index
es = es.entity_from_dataframe(entity_id = 'clients', dataframe = clients, index = 'client_id', time_index = 'joined')
loans数据框还具有唯一索引loan_id,并且将其添加到实体集的语法与clients相同。但是,对于payments数据框,没有唯一索引。当我们将此实体添加到实体集时,我们需要传入参数make_index = True并指定索引的名称。此外,虽然featuretools会自动推断实体中每列的数据类型,但我们可以通过将列类型的字典传递给参数variable_types来覆盖它。
# Create an entity from the payments dataframe
# This does not yet have a unique index
es = es.entity_from_dataframe(entity_id = 'payments',
dataframe = payments,
variable_types = {'missed': ft.variable_types.Categorical},
make_index = True,
index = 'payment_id',
time_index = 'payment_date')
对于这个数据框,即使missed 的类型是一个整数,但也不是一个数字变量,因为它只能取2个离散值,所以我们告诉featuretools将缺失数据视作是一个分类变量。将数据框添加到实体集后,我们检查它们中的任何一个:
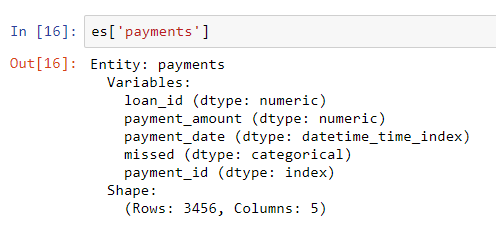
使用我们指定的修改模型能够正确推断列类型。接下来,我们需要指定实体集中的表是如何相关的。
数据表之间的关系
考虑两张数据表之间关系的最佳方式是用父对子的类比 。父与子是一对多的关系:每个父母可以有多个孩子。在数据表的范畴中,父表的每一行代表一位不同的父母,但子表中的多行代表的多个孩子可以对应到父表中的同一位父母。
例如,在我们的数据集中,clients客户数据框是loan 贷款数据框的父级,因为每个客户在客户表中只有一行,但贷款可能有多行。
同样,贷款loan数据是支付payments数据的父级,因为每笔贷款都有多笔付款。父级数据表通过共享变量与子级数据表关联。当我们执行聚合操作时,我们通过父变量对子表进行分组,并计算每个父项的子项之间的统计数据。
我们只需要指明将两张数据表关联的那个变量,就能用featuretools来建立表格见的关系 。
客户clients数据表和贷款loans数据表通过变量client_id
相互关联,而贷款loans数据表和支付payments数据表则通过变量loan_id相互关联。以下是建立关联并将其添加到entiytset的语法:
# Relationship between clients and previous loans
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_client_previous)
# Relationship between previous loans and previous payments
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# Add the relationship to the entity set
es = es.add_relationship(r_payments)
es
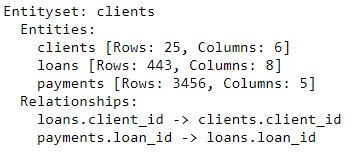
现在,在entityset中包含了三张数据表,以及三者间的关系。在添加entities并建立关联后,我们的entityset就算完成了,可以开始建立特征量了。
特征基元
在我们完全深入进行特征合成之前,我们需要了解特征基元。我们已经知道它们是什么了,但我们刚刚用不同的名字来称呼它们!这些只是我们用来形成新功能的基本操作:
聚合:基于父表与子表(一对多)关系完成的操作,按父表分组,并计算子表的统计数据。一个例子是通过client_id对贷款loan表进行分组,并找到每个客户的最大贷款额。
转换:在单个表上对一列或多列执行的操作。一个例子是在一个表中取两个列之间的差异或取一列的绝对值。
在featuretools中使用这些基元本身或堆叠多个基元,来创建新功能。下面是featuretools中一些特征基元的列表(我们也可以定义自定义基元)
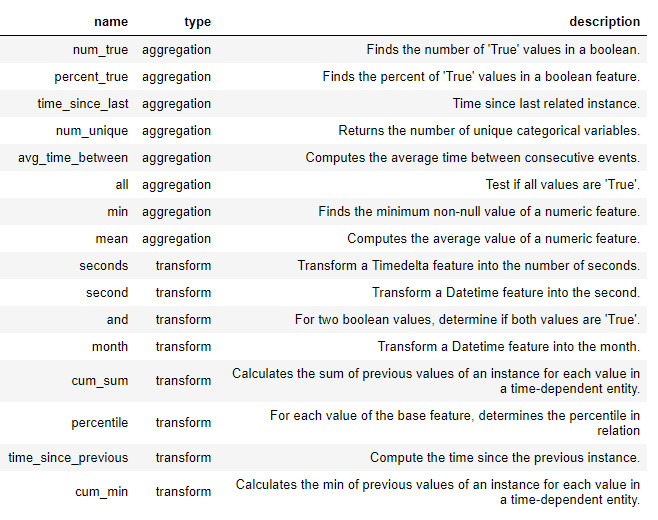
这些原语可以单独使用,也可以组合使用来创建特征量。要使用指定的基元制作特征,我们使用ft.dfs函数(代表深度特征合成)。我们传入entityset,target_entity,这是我们要添加特征的表,选择的trans_primitives(转换)和agg_primitives(聚合):
# Create new features using specified primitives
features, feature_names = ft.dfs(entityset = es, target_entity = 'clients',
agg_primitives = ['mean', 'max', 'percent_true', 'last'],
trans_primitives = ['years', 'month', 'subtract', 'divide'])
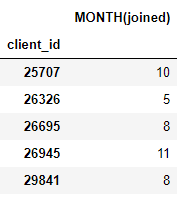
结果是每个客户端的新特征数据框(因为我们使客户端成为target_entity)。例如,我们有每个客户加入的月份,这是由转换特征基元生成的:
我们还有许多聚合基元,例如每个客户的平均付款金额:

我们还有许多聚合基元,例如每个客户的平均付款金额:

深度特征合成
我们现在已经做好准备来理解深度特征合成(dfs)。实际上,我们已经在之前的函数调用中执行了dfs!深度特征仅仅是堆叠多个基元的特征,而dfs是制作这些特征的过程名称。深度特征的深度是制作特征所需的基元的数量。

我们可以将功能堆叠到我们想要的任何深度,但在实践中,我从未用过超过2的深度。在此之后,生成的特征就很难解释,但我鼓励任何有兴趣的人尝试“更深入” 。
我们不必手动指定特征基元,而是可以让featuretools自动为我们选择特征。我们可以使用相同的ft.dfs函数调用,但不传入任何特征基元:
# Perform deep feature synthesis without specifying primitives
features, feature_names = ft.dfs(entityset=es, target_entity='clients',
max_depth = 2)
features.head()

Featuretools为我们构建了许多新特征。虽然此过程会自动创建新特征,但仍需要数据科学家来弄清楚如何处理所有这些特征。例如,如果我们的目标是预测客户是否会偿还贷款,我们可以寻找与指定结果最相关的特征。此外,如果我们有领域知识,我们可以使用它来选择特定的特征基元或种子深度特征合成候选特征。
例如,MEAN(payments.payment_amount)列是深度为1的深层特征,因为它是使用单个聚合创建的。深度为2的特征是LAST(贷款(MEAN(payments.payment_amount))这是通过堆叠两个聚合来实现的:最后一个(最近的)在MEAN之上。这表示每个客户最近贷款的平均支付额。
下一步
自动化特征工程虽然解决了一个问题,但又导致了另一个问题:特征太多。虽然在拟合模型之前很难说哪些特征很重要,但很可能并非所有这些特征都与我们想要训练模型的任务相关。此外,特征太多可能会导致模型性能不佳,因为一些不是很有用的特征会淹没那些更重要的特征。
特征过多的问题被称为维度诅咒 。随着特征数量的增加(数据的维度增加),模型越来越难以学习特征和目标之间的映射。实际上,模型执行所需的数据量随着特征数量呈指数级增长。
维度诅咒与特征缩减(也称为特征选择)相对应:删除不相关特征的过程。特征选择可以采用多种形式:主成分分析(PCA),SelectKBest,使用模型中的特征重要性,或使用深度神经网络进行自动编码。但是,减少功能是另一篇文章的另一个主题。目前,我们知道我们可以使用featuretools以最小的努力从许多表创建许多功能!
结论
与机器学习中的许多主题一样,使用featuretools的自动化特征工程是一个基于简单想法的复杂概念。使用实体集,实体和关系的概念,featuretools可以执行深度特征合成以新建特征。
聚合就是将深度特征合成依次将特征基元堆叠 ,利用了跨表之间的一对多关系,而转换是应用于单个表中的一个或多个列的函数,从多个表构建新特征。
在以后的文章中,我将展示如何使用这种技术解决现实中的问题,也就是目前正在Kaggle上主持的Home Credit Default Risk竞赛。请继续关注该帖子,同时阅读此介绍以开始参加比赛!我希望您现在可以使用自动化特征工程作为数据科学管道的辅助工具。模型的性能是由我们提供的数据所决定的,而自动化功能工程可以帮助提高建立新特征的效率。
如何用Python做自动化特征工程的更多相关文章
- 2022年Python顶级自动化特征工程框架⛵
作者:韩信子@ShowMeAI 机器学习实战系列:https://www.showmeai.tech/tutorials/41 本文地址:https://www.showmeai.tech/artic ...
- Auto-ML之自动化特征工程
1. 引言 个人以为,机器学习是朝着更高的易用性.更低的技术门槛.更敏捷的开发成本的方向去发展,且Auto-ML或者Auto-DL的发展无疑是最好的证明.因此花费一些时间学习了解了Auto-ML领域的 ...
- [特征工程]-------使用sklearn做单机特征工程[转载]
https://www.cnblogs.com/jasonfreak/p/5448385.html 使用sklearn做单机特征工程 目录 1 特征工程是什么?2 数据预处理 2.1 无量纲化 2.1 ...
- 使用sklearn做单机特征工程(Performing Feature Engineering Using sklearn)
本文转载自使用sklearn做单机特征工程 目录 目录 特征工程是什么 数据预处理 1 无量纲化 11 标准化 12 区间缩放法 13 标准化与归一化的区别 2 对定量特征二值化 3 对定性特征哑编码 ...
- 手把手教你用Python实现自动特征工程
任何参与过机器学习比赛的人,都能深深体会特征工程在构建机器学习模型中的重要性,它决定了你在比赛排行榜中的位置. 特征工程具有强大的潜力,但是手动操作是个缓慢且艰巨的过程.Prateek Joshi,是 ...
- 如何用Python做Web开发?——Django环境配置
用Python做Web开发,Django框架是个非常好的起点.如何从零开始,配置好Django开发环境呢?本文带你一步步无痛上手. 概念 最近有个词儿很流行,叫做“全栈”(full stack ...
- 自动化特征工程—Featuretools
Featuretools是一个可以自动进行特征工程的python库,主要原理是针对多个数据表以及它们之间的关系,通过转换(Transformation)和聚合(Aggregation)操作自动生成新的 ...
- 使用sklearn做单机特征工程
目录 1 特征工程是什么?2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 标准化与归一化的区别 2.2 对定量特征二值化 2.3 对定性特征哑编码 2.4 缺 ...
- 【转】使用sklearn做单机特征工程
这里是原文 说明:这是我用Markdown编辑的第一篇随笔 目录 1 特征工程是什么? 2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 无量纲化与正则化的区别 ...
随机推荐
- xcode选择开发者时"The Apple Developer Program License Agreement has been updated"
解决方法:进入开发者中心查看红色提示信息,同意就行
- 別人寫的git的總結,寫自己這裡學習用
這裡是原文,http://www.cnblogs.com/ang-/p/7352909.html 貼這裡慢慢學. git入门大全 阅读目录 前言 基本概念 文件几种状态 创建新仓库 配置 检出仓库 ...
- sql server 某列去重
例如:某个表中,插入了两条除id外其他字段都一样的数据,但是查询的时候只想查到一条. select * from 表名 where 主键 in ( select max(主键) from 表名 gro ...
- 【Leetcode】【Easy】String to Integer (atoi)
Implement atoi to convert a string to an integer. Hint: Carefully consider all possible input cases. ...
- 【Leetcode】【Easy】Maximum Depth of Binary Tree
Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the long ...
- March 11 2017 Week 10 Saturday
Wisdom outweighs any wealth. 智慧比财富更有价值. Wisdom can create wealth if used in proper ways, it can help ...
- URL地址解析
URL的一般格式为(带方括号[]的为可选项): protocol :// hostname[:port] / path /[?query]#fragment 1.protocol :// 为传输协 ...
- C++中临时对象的产生与优化
看到了几篇讲的不错的博客,这里收集起来 不明白的地方互相参考 https://blog.csdn.net/fangqingan_java/article/details/9320769 https:/ ...
- 前端开发css禁止选中文本
在我们日常的Java web前端开发的过程中呢,程序员们会遇到各种各样的要求,所以不每天学的东西感觉自己都退步了,都更不上时代的发展了. 每天应对各种需求,每天活在疑问中就是我们程序员的真是写照.但我 ...
- python:协程
1,如何实现在两个函数之间的切换? def func1(): print(l) yield print(3) yield def func2(): g =func1() next(g) print(2 ...