elasticsearch5.6.8中文分词器
安装分词器,务必确保版本一致!
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
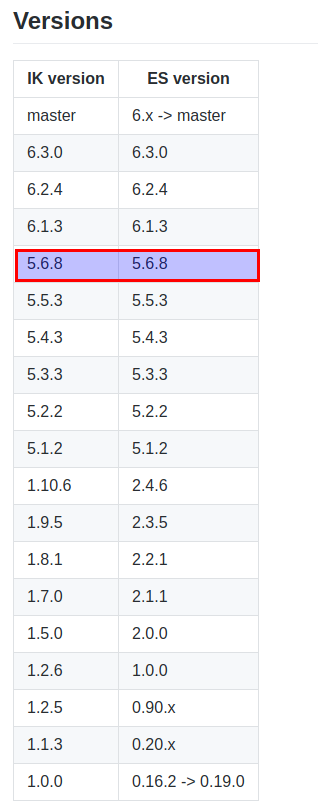
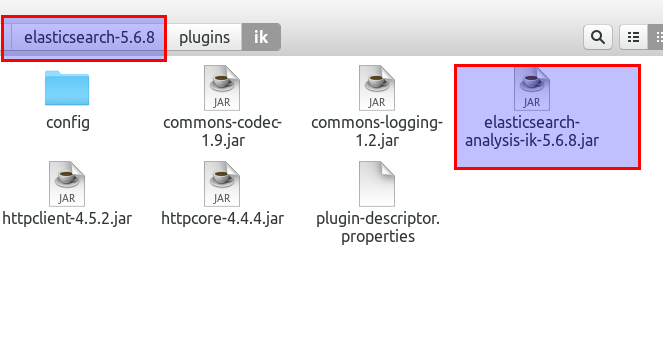
为了保证一致,我特地将elasticsearch进行降级。
ik_smart
GET _analyze?pretty
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 1
}
]
}
ik_max_word
GET _analyze?pretty
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 8
},
{
"token": "国歌",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 9
}
]
}
elasticsearch5.6.8中文分词器的更多相关文章
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- ElasticSearch安装中文分词器IK
1.安装IK分词器,下载对应版本的插件,elasticsearch-analysis-ik中文分词器的开发者一直进行维护的,对应着elasticsearch的版本,所以选择好自己的版本即可.IKAna ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- 11大Java开源中文分词器的使用方法和分词效果对比
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Solr入门之(8)中文分词器配置
Solr中虽然提供了一个中文分词器,但是效果很差,可以使用IKAnalyzer或Mmseg4j 或其他中文分词器. 一.IKAnalyzer分词器配置: 1.下载IKAnalyzer(IKAnalyz ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- solr4.7中文分词器(ik-analyzer)配置
solr本身对中文分词的处理不是太好,所以中文应用很多时候都需要额外加一个中文分词器对中文进行分词处理,ik-analyzer就是其中一个不错的中文分词器. 一.版本信息 solr版本:4.7.0 需 ...
随机推荐
- JNI_Z_02_函数参数_JNIEnv*_jclass_jobject
1. 1.1.JNIEXPORT void JNICALL Java_包名_类名_函数名01(JNIEnv * env, jclass clazz) // Java代码中的 静态函数 1.2.JNIE ...
- FM算法 的总结
FM的总结: 1.FM算法与线性回归相比增加了特征的交叉.自动选择了所有特征的两两组合,并且给出了两两组合的权重. 2.上一条所说的,如果给两两特征的组合都给一个权重的话,需要训练的参数太多了.比如我 ...
- codeforces 814B.An express train to reveries 解题报告
题目链接:http://codeforces.com/problemset/problem/814/B 题目意思:分别给定一个长度为 n 的不相同序列 a 和 b.这两个序列至少有 i 个位置(1 ≤ ...
- 负载均衡之DNS域名解析
转载请说明出处:http://blog.csdn.net/cywosp/article/details/38017027 在上一篇文章(http://blog.csdn.net/cywosp/arti ...
- Django进阶Model篇003 - 数据库同步技巧
一.认识一个目录 目录名:migrations 作用:用来存放通过makemigrations命令生成的数据库脚本,不熟悉的情况下,里面生成的脚本不要轻易修改.app目录下必须要有migrations ...
- poj32072-sat模板题
tarjan扫一遍后直接判断 最关键的地方就是建边(x[i] <= x[j] && y[i] >= x[j] && y[i] <= y[j]) || ...
- linux应用之wget命令详解
wget是linux最常用的下载命令, 一般的使用方法是: wget + 空格 + 要下载文件的url路径 例如: # wget linuxsense.org/xxxx/xxx.tar.gz" ...
- hdu 5975 Aninteresting game
Aninteresting game Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Other ...
- Isilon
Isilon编辑 本词条缺少信息栏,补充相关内容使词条更完整,还能快速升级,赶紧来编辑吧! 美国Isilon公司是全球群集存储系统的主要供应商,是该领域的领导者.总部位于美国华盛顿州的西雅图.创建于2 ...
- SQLSERVER store procedure 临时表
有些时候显示重复数据时,使用: ) 但有些时候表A过大或者逻辑复杂.显示数据时,会造成性能的影响,这时你就可以使用临时表: ) create table #temp( XXX , XXX) )in ...