巨蟒python全栈开发django6: FBV&CBV&&单表查询的其他方法
练习CBV用法

截图中的action="/cbv/",应该是这样


上边红图,说明mysql有问题,需要重启一下
返回,输入的内容
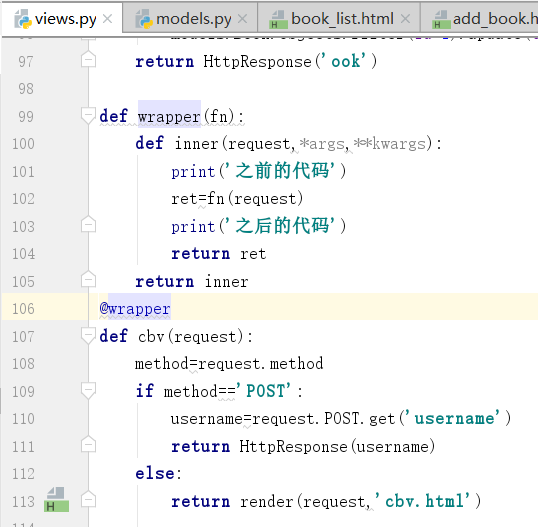
@wrapper==>cbv=wrapper(cbv)
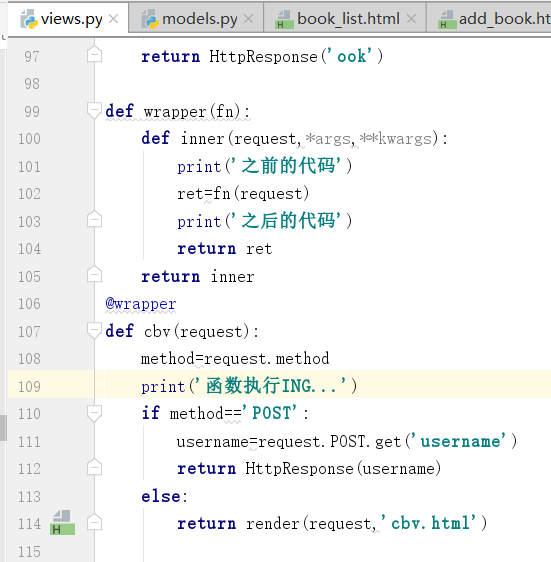
运行重启:
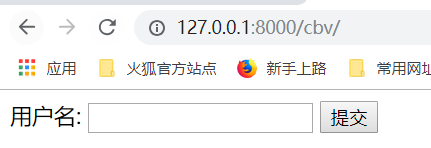
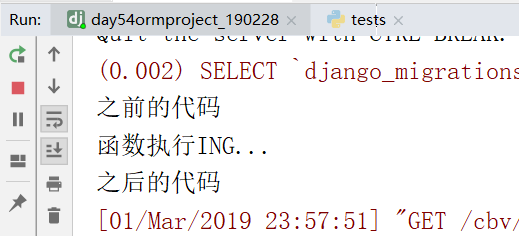
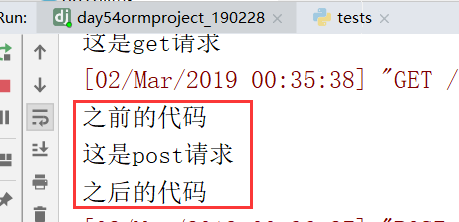
提交数据123,之后,返回123
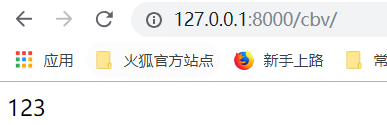
服务端得到结果:
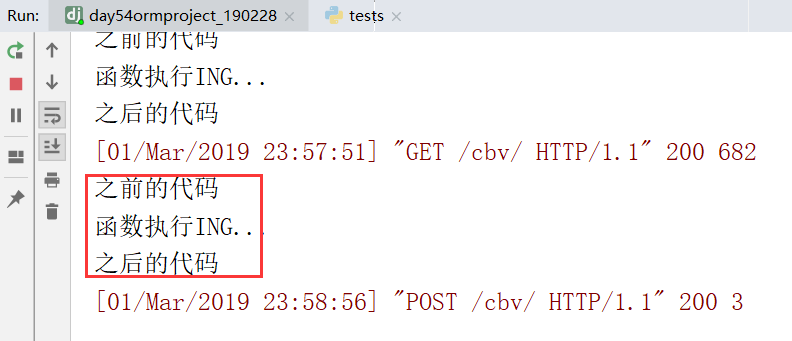
上边是FBV装饰器的使用
下边是CBV装饰器的使用:
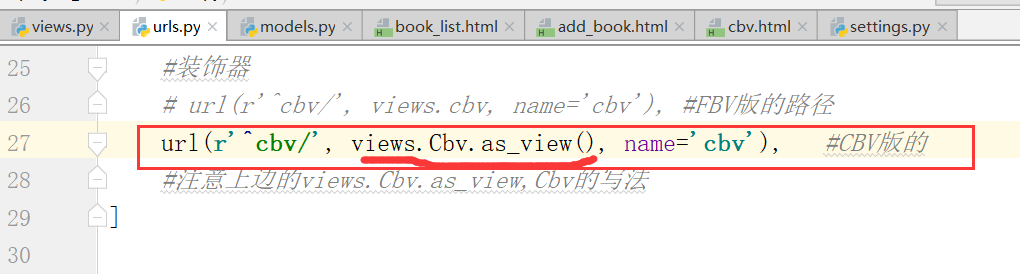
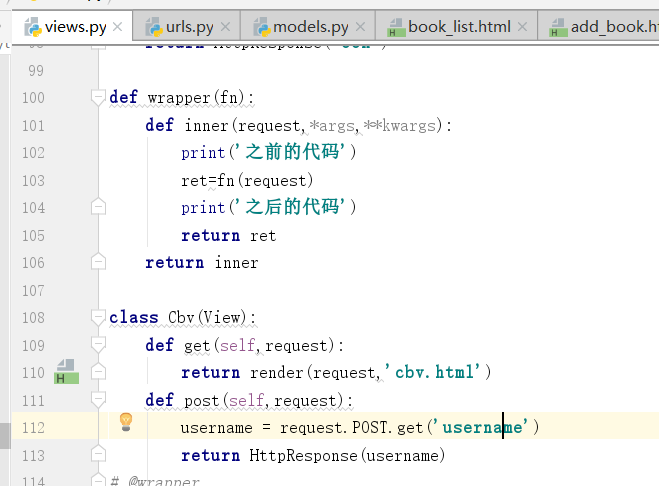

下面我们进行,加装饰器
,先演示dispatch
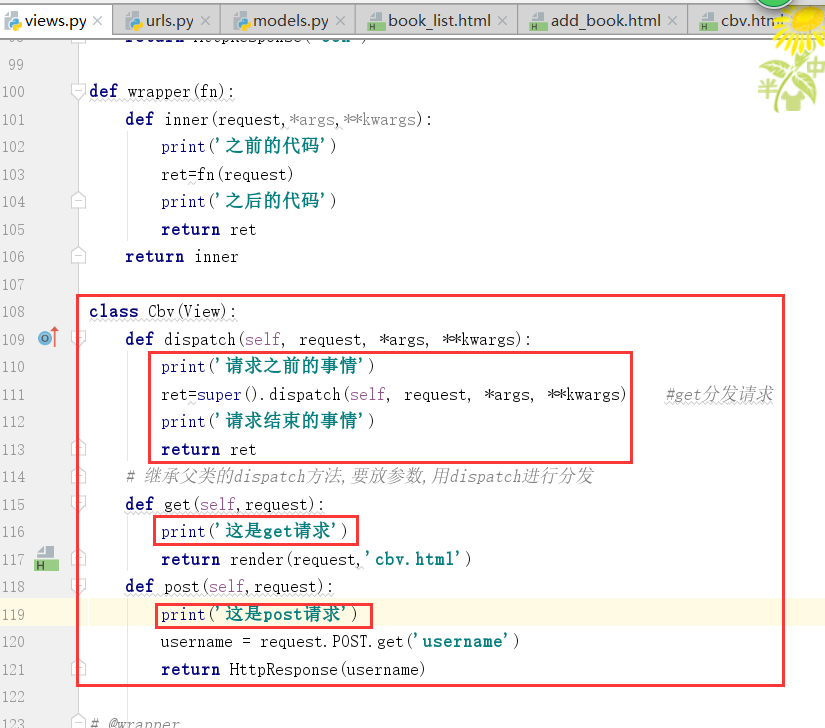
注意,上边的dispatch里边的,第一个框,没有self
这时候,我们再重启看效果.
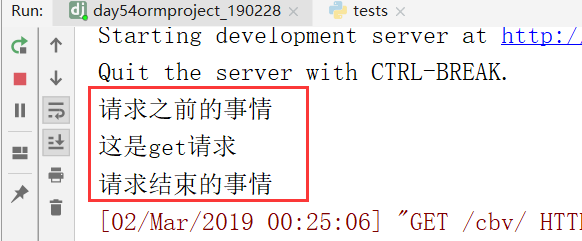
现在开始写装饰器,

开始,加入方法装饰器,
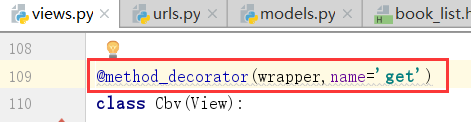
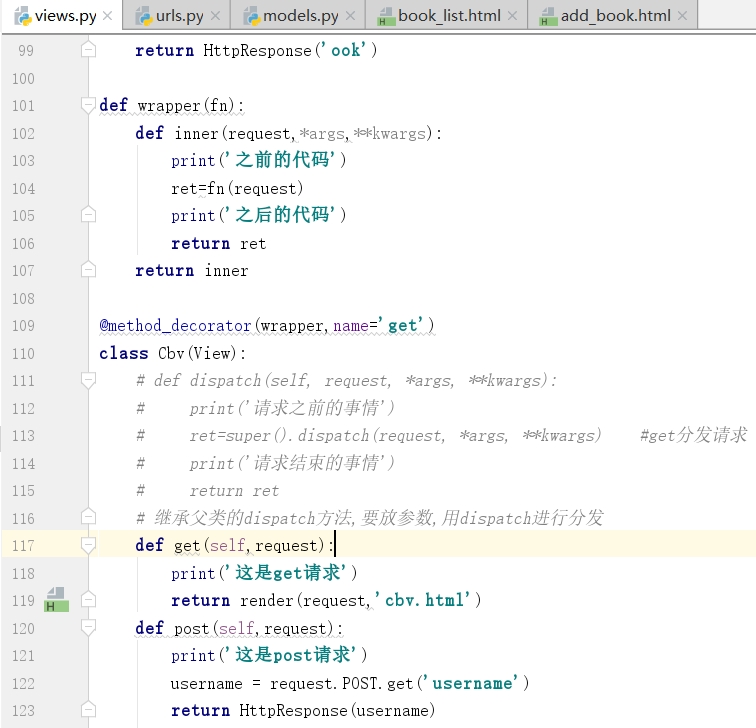

装饰器加成功了

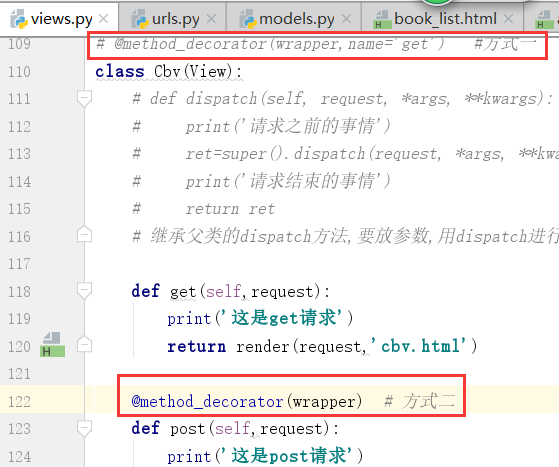
第二种加法
运行


如果,想要两个都加,加在dispatch方法上边,

运行:

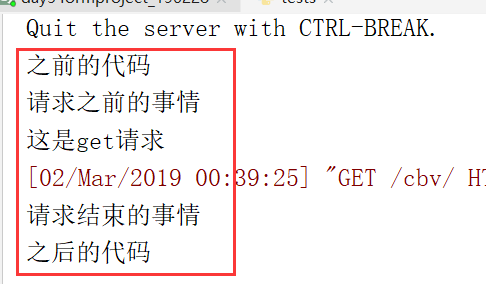

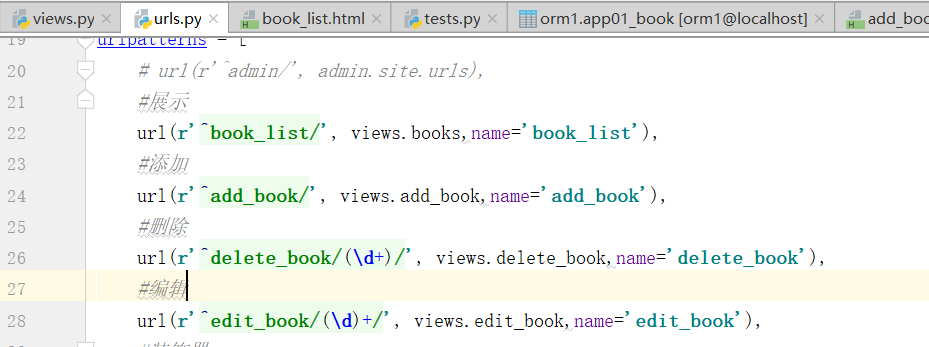
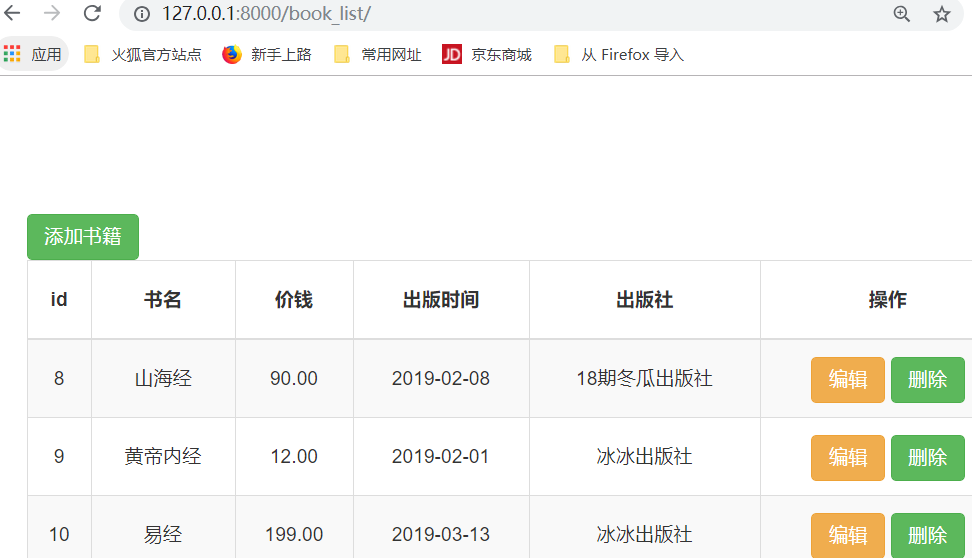
1.删除和编辑制图
首先,我们先添加几本书,
运行程序,
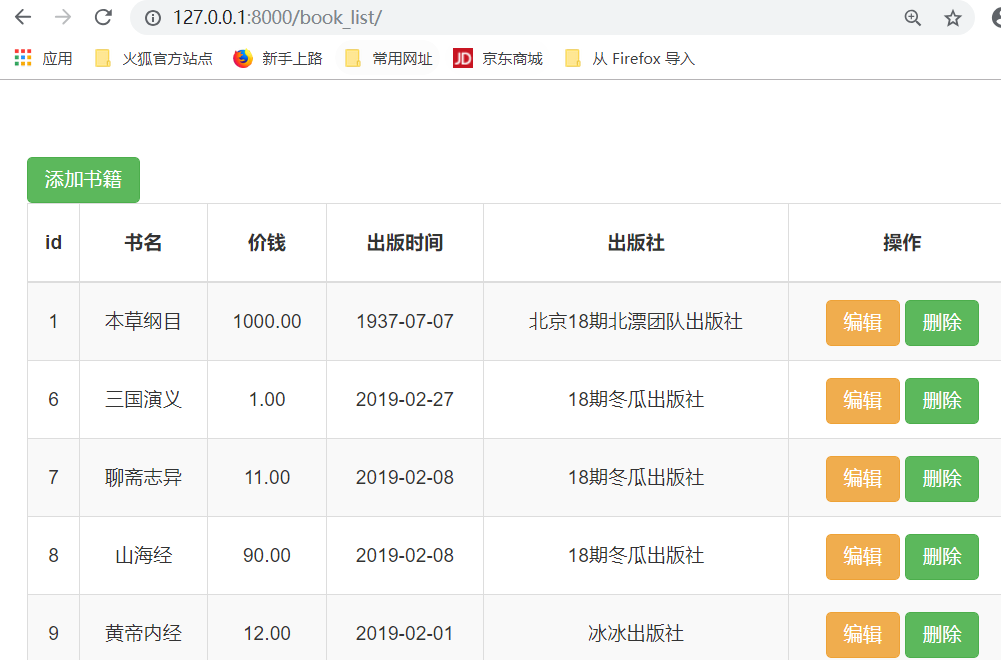
点击"添加书籍"
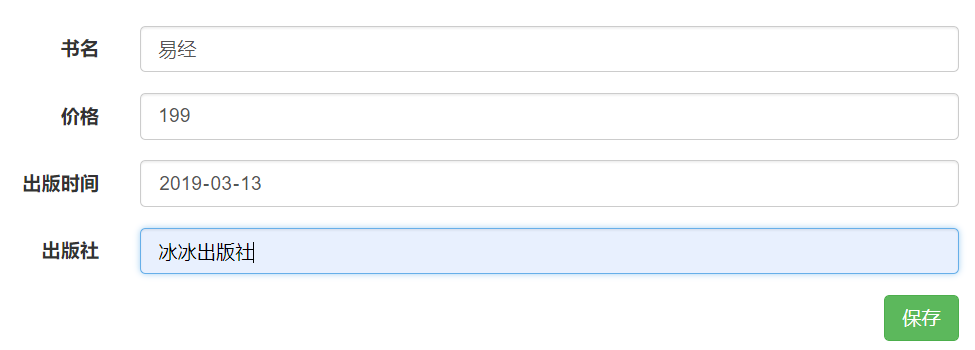
点击"保存"
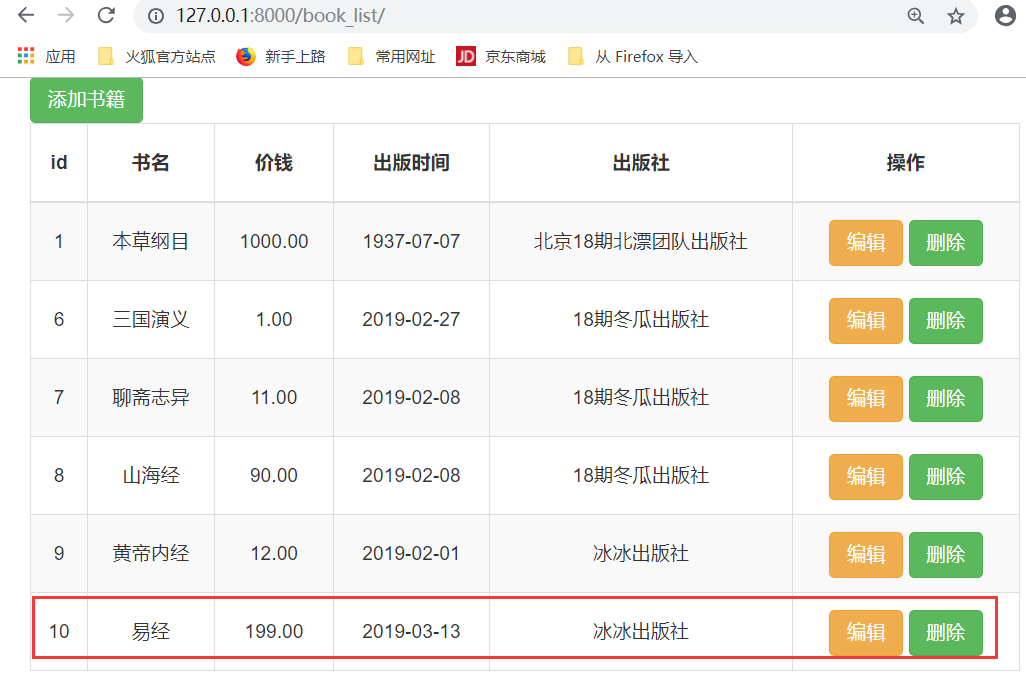
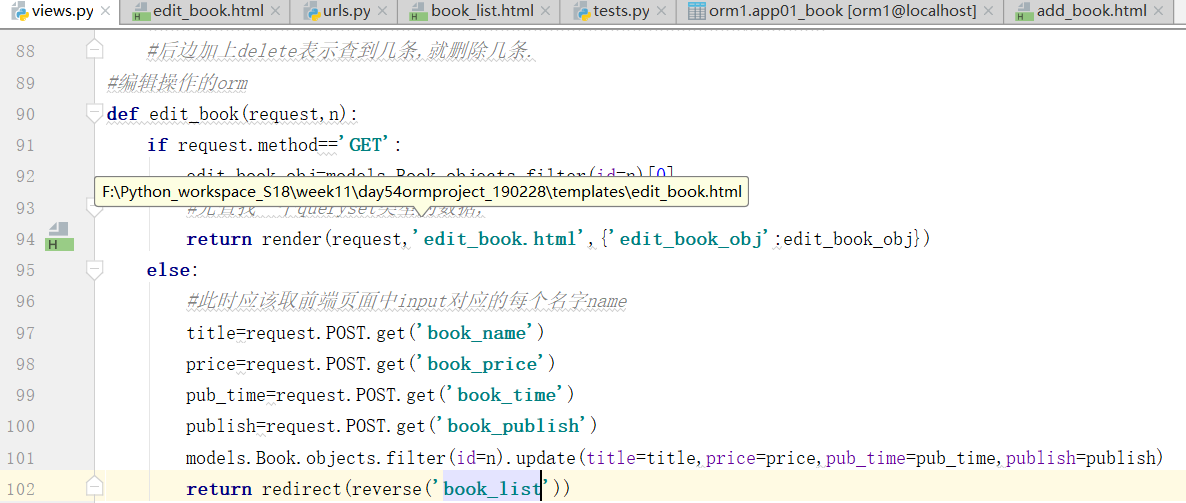
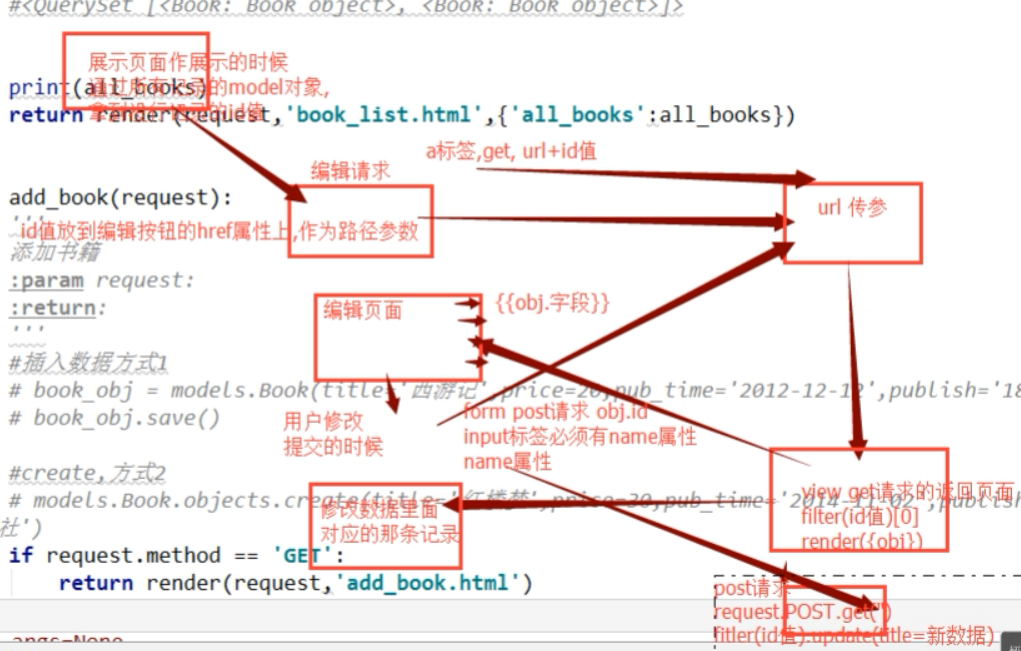
首先考虑,编辑和删除的这个过程应该干什么,第一步点击一下,向后端发送一个请求,点击删除,将后端数据库的内容删除,思考,点击删除怎么发送请求,思考,怎样就是这条数据,把这条数据删除???首先配置URL,前端和后端还没有写完.
删除这一页,要让用户,知道你已经删除了这一页
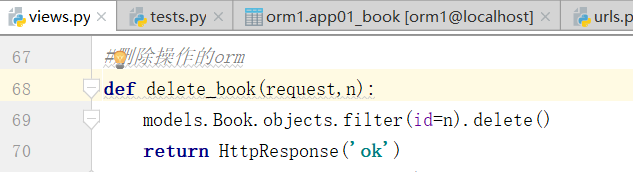
也就是让浏览器,再请求一次请求book_list

原来的删除按钮:
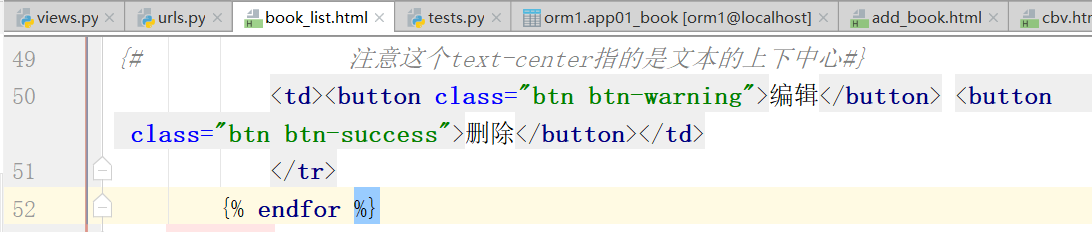
改成下面的删除按钮,button改成a,也就是一个连接(前端,找到后端的url路径,路径再找到函数处理列表,最后,再返回book_list)
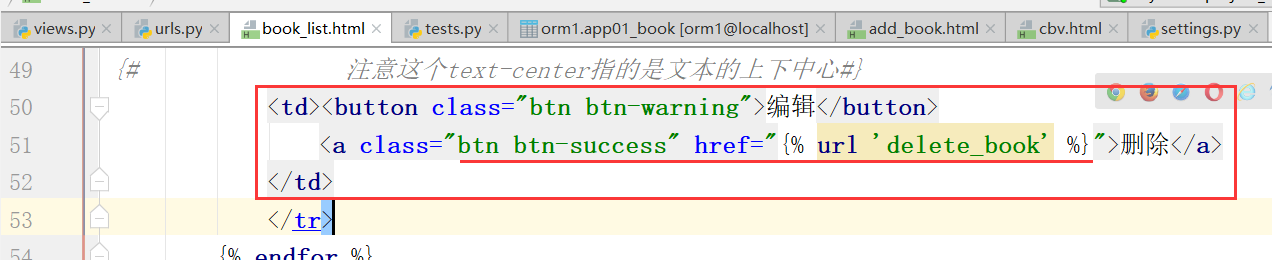
最后,还需要添加这本书的ID进行添加,

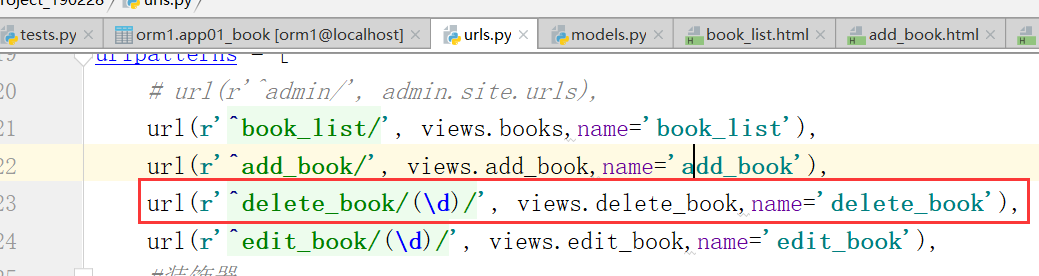
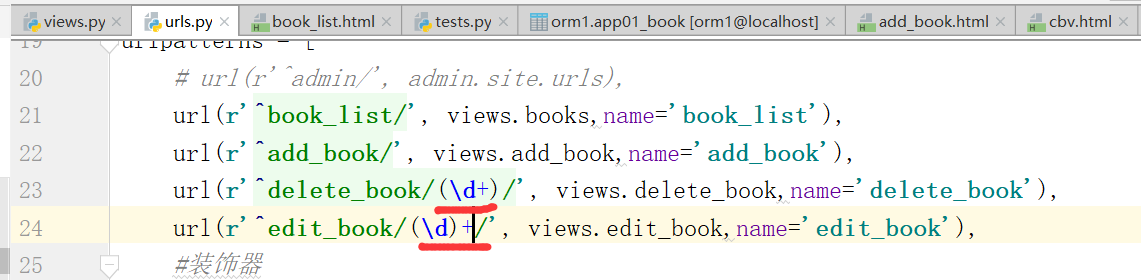
注意,这个url配置,需要加上数字,进行匹配,可能是多个数字
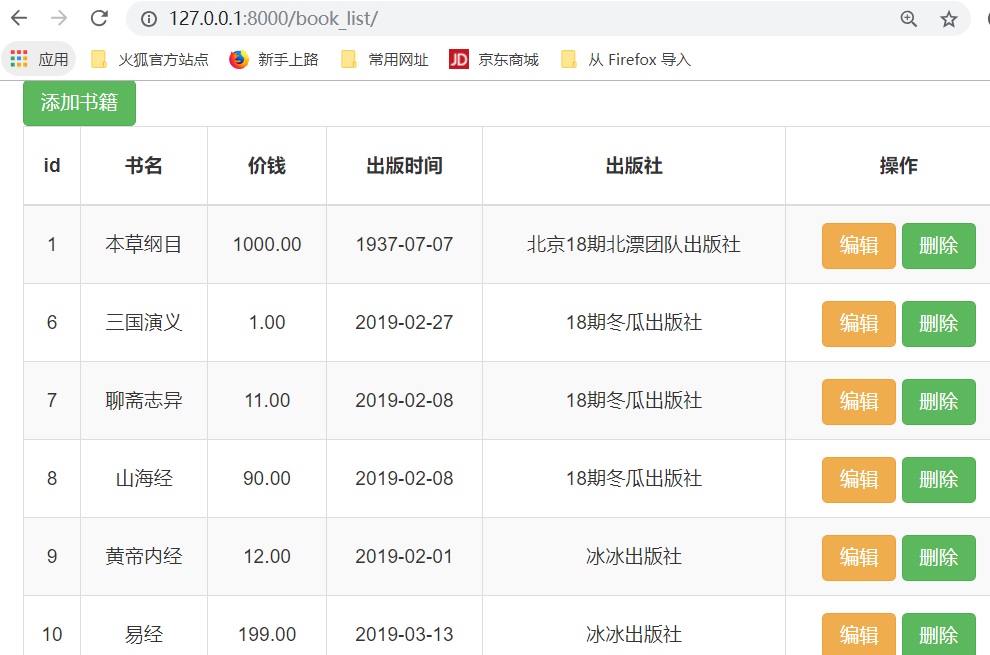
得到结果:

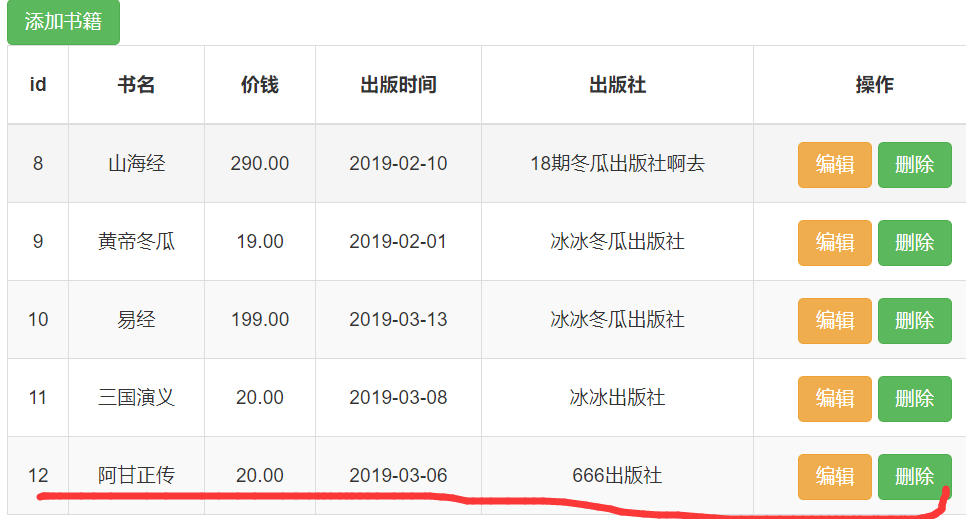
点击第一本书的,"删除",连续多次,得到下面的结果
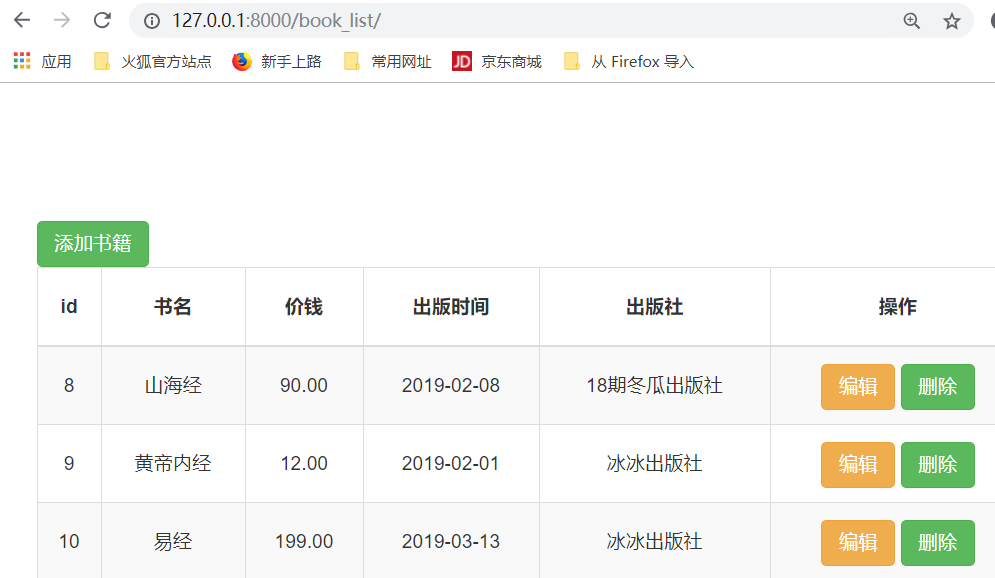
重定向,就是反复请求数据,得到最后一次刷新之后的结果
redirect就是发送给浏览器一个重定向的请求,浏览器拿到重定向的请求之后,调用location的方法,指定一个href,也就是自己指定的一个redirect,
返回指定的路径,拿到最新的数据,主动刷新页面
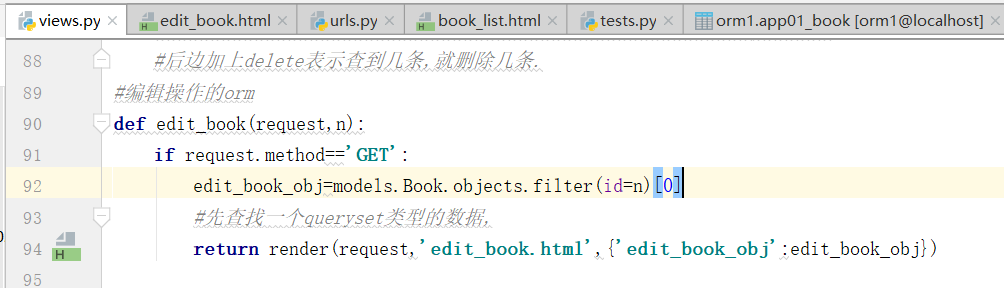
同样,编辑也是这样,(但是,后边这个one_book.id,虽然不是唯一的凡是,但是是最合适的,因为ID是唯一的自增的不重复的属性字段)


逻辑的写法
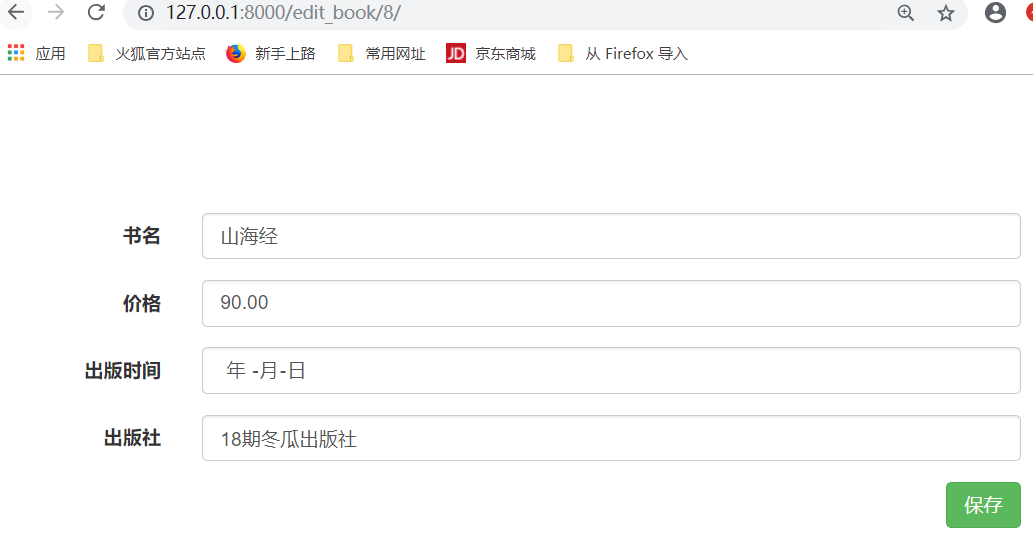
先写html页面,直接复制add_list复制,修改成edit页面

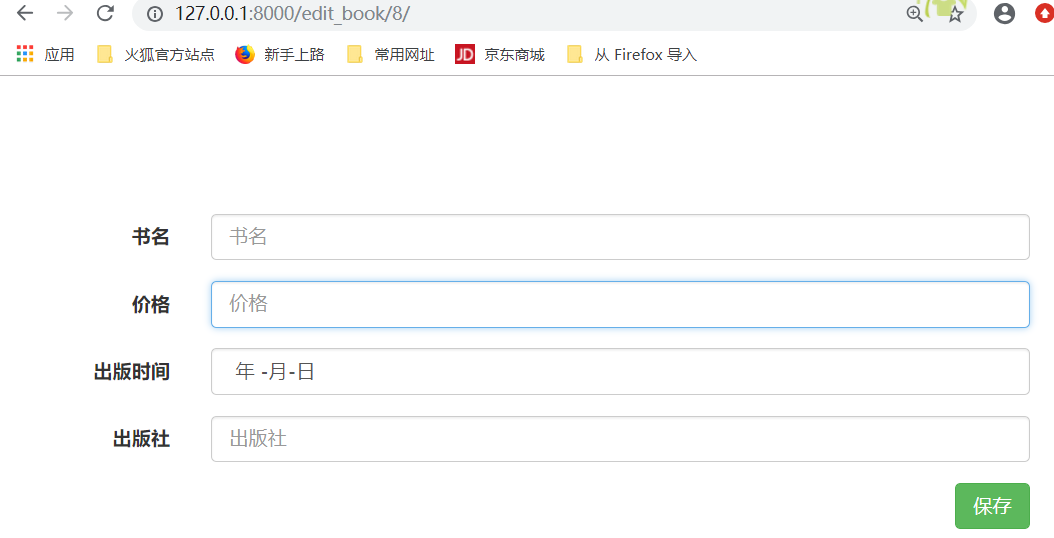
运行: 得到如下结果,点击编辑

点击编辑,得到如下结果:
如何把默认值,放到指定的位置,在编辑页面,依次在input标签中添加,默认属性
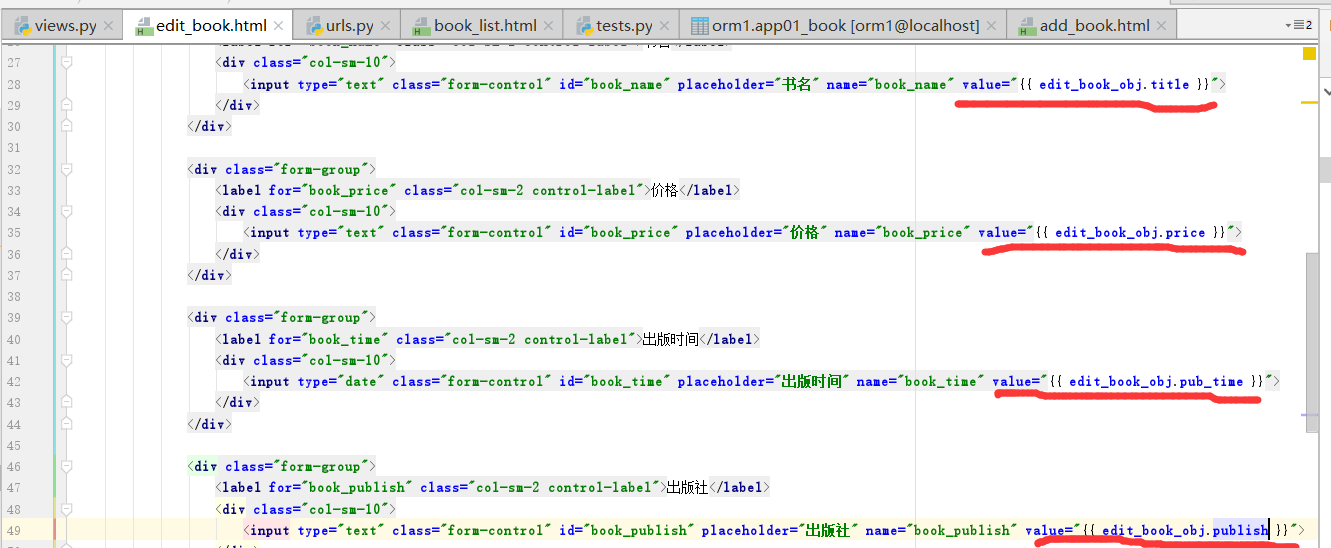
运行:
点击编辑,
发现日期没有默认值,日期这个地方需要过滤器进行处理,才能过滤出来

刷新一下,就出现"出版时间"了

可以进行编辑,保存之后,跳转到book_list页面,
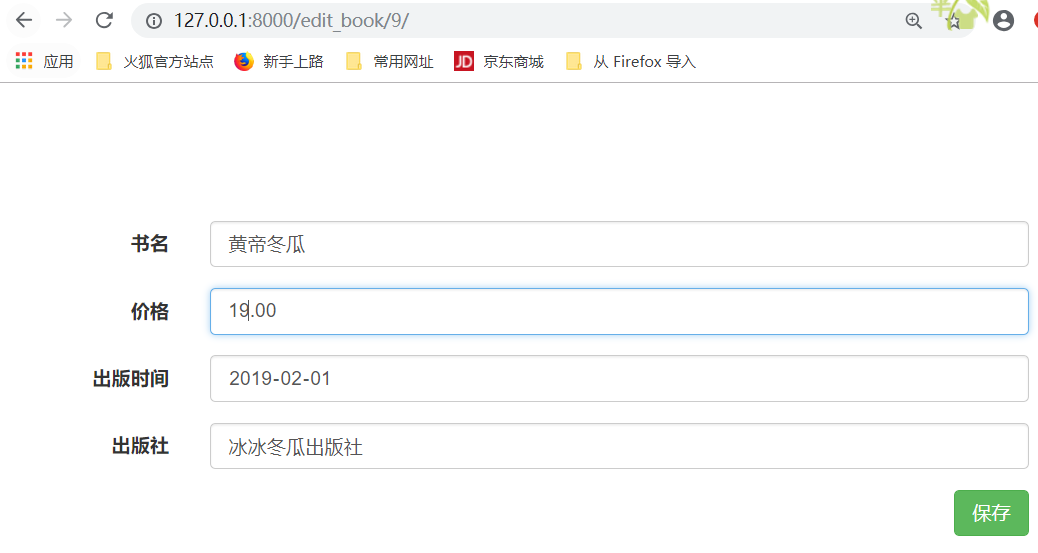
点击"保存",

此时,已经完成了修改.
2.编辑按钮的流程分析(这个地方还需要多推敲几遍)
3.
13条查询的api,每条都是重点
<> all(): 查询所有结果,结果是queryset类型 <> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象,结果也是queryset类型 Book.objects.filter(title='linux',price=) #里面的多个条件用逗号分开,并且这几个条件必须都成立,是and的关系,or关系的我们后面再学,直接在这里写是搞不定or的 <> get(**kwargs): 返回与所给筛选条件相匹配的对象,不是queryset类型,是行记录对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。捕获异常try。 Book.objects.get(id=) <> exclude(**kwargs): 排除的意思,它包含了与所给筛选条件不匹配的对象,没有不等于的操作昂,用这个exclude,返回值是queryset类型 Book.objects.exclude(id=),返回id不等于6的所有的对象,或者在queryset基础上调用,Book.objects.all().exclude(id=)
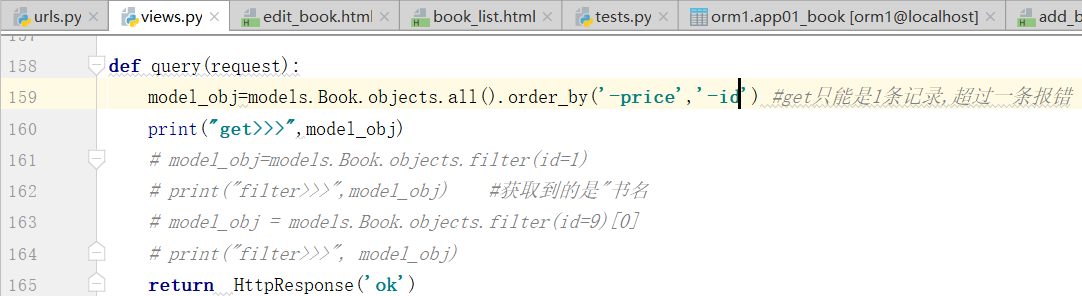
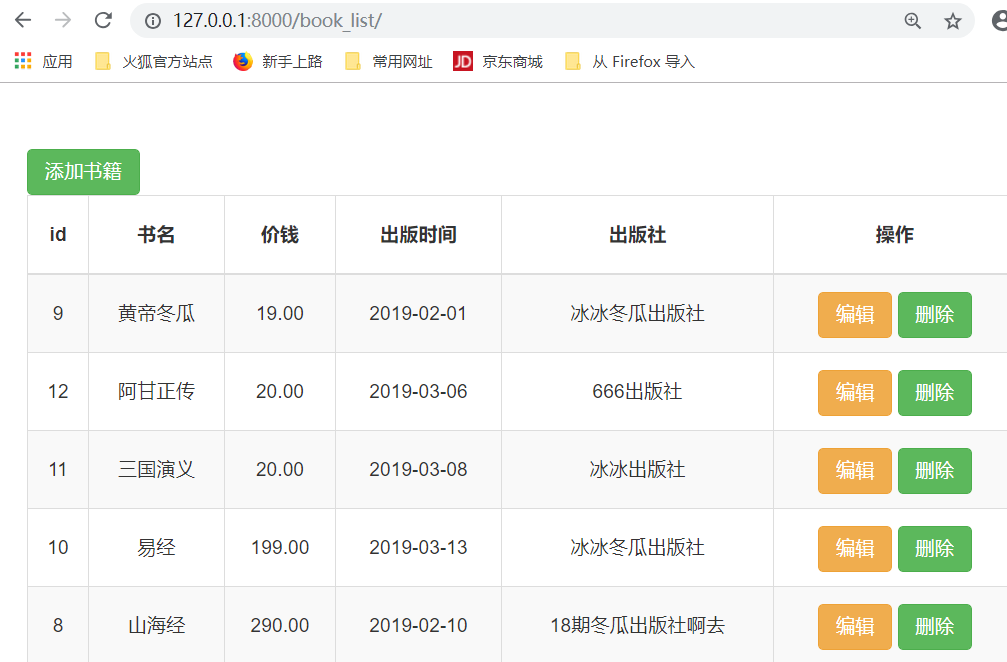
<> order_by(*field): queryset类型的数据来调用,对查询结果排序,默认是按照id来升序排列的,返回值还是queryset类型
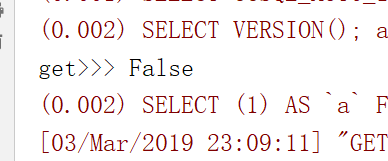
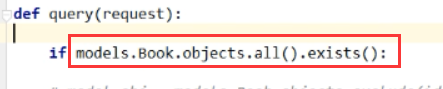
models.Book.objects.all().order_by('price','id') #直接写price,默认是按照price升序排列,按照字段降序排列,就写个负号就行了order_by('-price'),order_by('price','id')是多条件排序,按照price进行升序,price相同的数据,按照id进行升序 <> reverse(): queryset类型的数据来调用,对查询结果反向排序,返回值还是queryset类型 <> count(): queryset类型的数据来调用,返回数据库中匹配查询(QuerySet)的对象数量。 <> first(): queryset类型的数据来调用,返回第一条记录 Book.objects.all()[] = Book.objects.all().first(),得到的都是model对象,不是queryset <> last(): queryset类型的数据来调用,返回最后一条记录 <> exists(): queryset类型的数据来调用,如果QuerySet包含数据,就返回True,否则返回False
空的queryset类型数据也有布尔值True和False,但是一般不用它来判断数据库里面是不是有数据,如果有大量的数据,你用它来判断,那么就需要查询出所有的数据,效率太差了,用count或者exits
例:all_books = models.Book.objects.all().exists() #翻译成的sql是SELECT () AS `a` FROM `app01_book` LIMIT ,就是通过limit ,取一条来看看是不是有数据 <> values(*field): 用的比较多,queryset类型的数据来调用,返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列,只要是返回的queryset类型,就可以继续链式调用queryset类型的其他的查找方法,其他方法也是一样的。
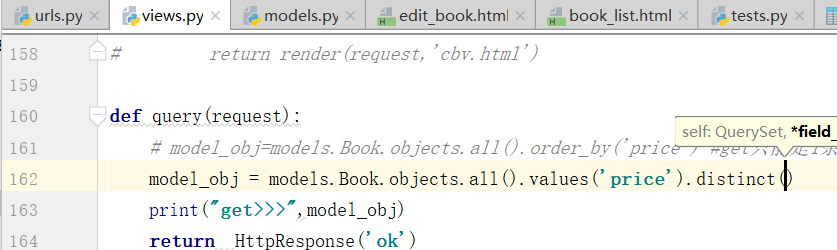
<> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <> distinct(): values和values_list得到的queryset类型的数据来调用,从返回结果中剔除重复纪录
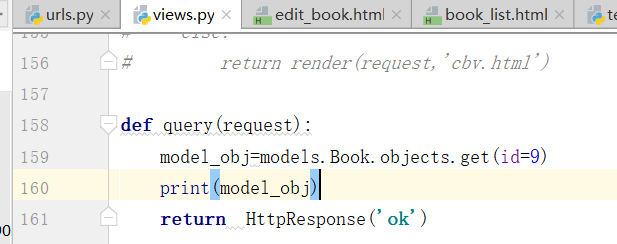

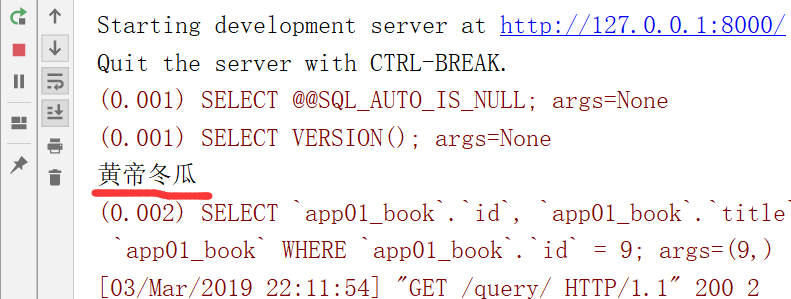





刚才,+写在括号外边
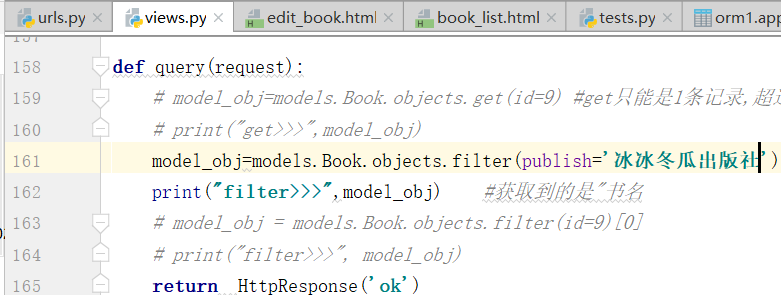
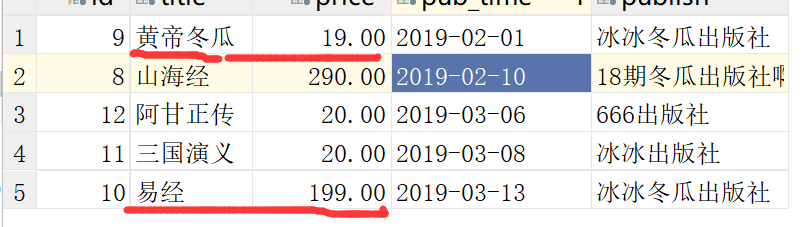
将易经的出版社,改成,冰冰冬瓜出版社

得到两条记录

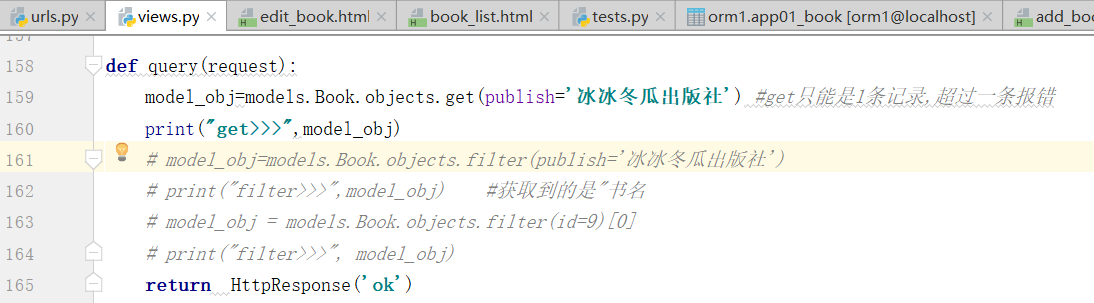
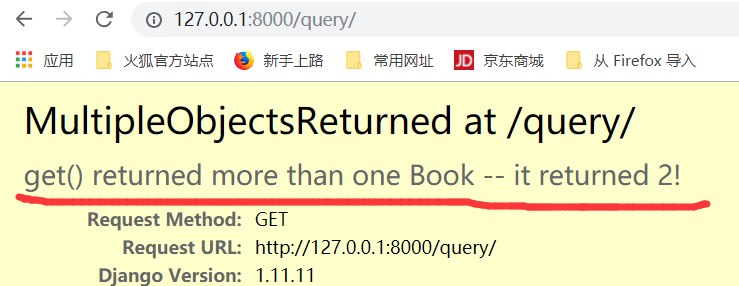
不能找的东西超过两个
get在找不到的情况下,会显示什么样呢?

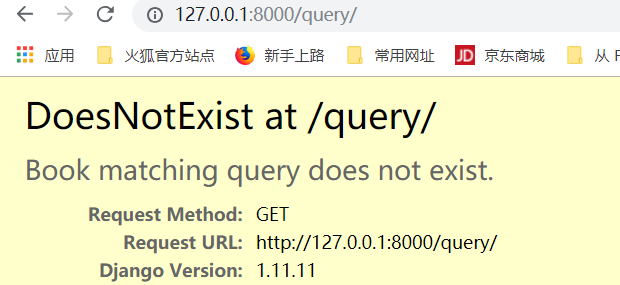

返回的是空,并且不报错,这个筛选器更加强大一些
!是否可以得到内容?
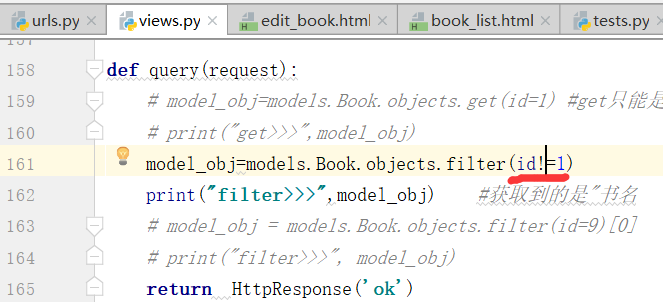
结果:布尔值是不可以迭代的 ,filter是循环多个条件的
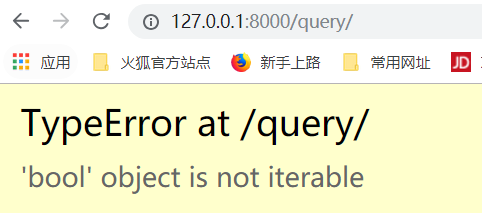
exclude,取反查询
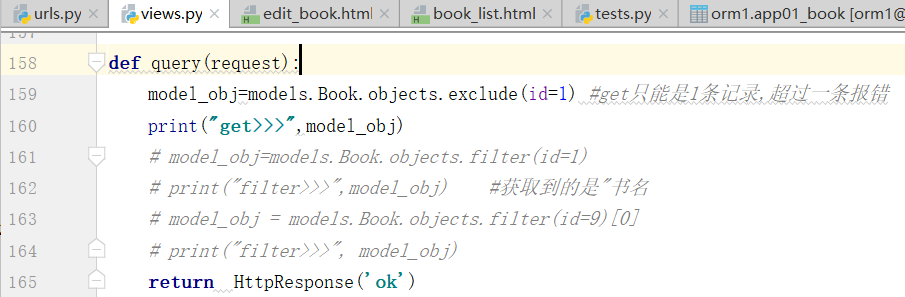

下面是连续操作,也叫链接查询



按照价格排序的结果:
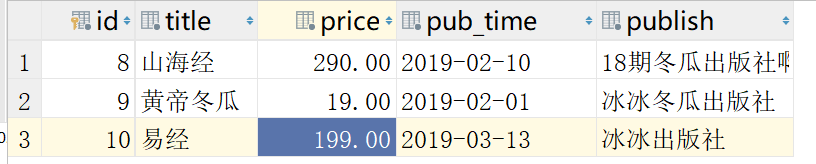
加上负号,表示倒序排列


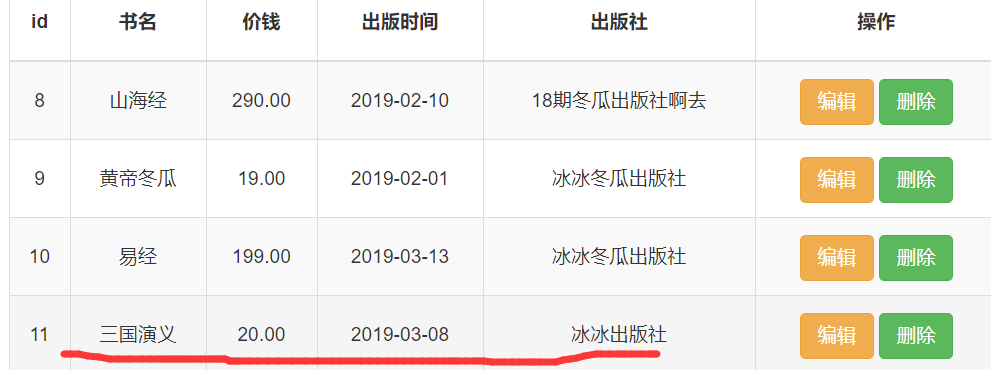
价钱相同的再排序,第一个相同,按照第二个条件排序
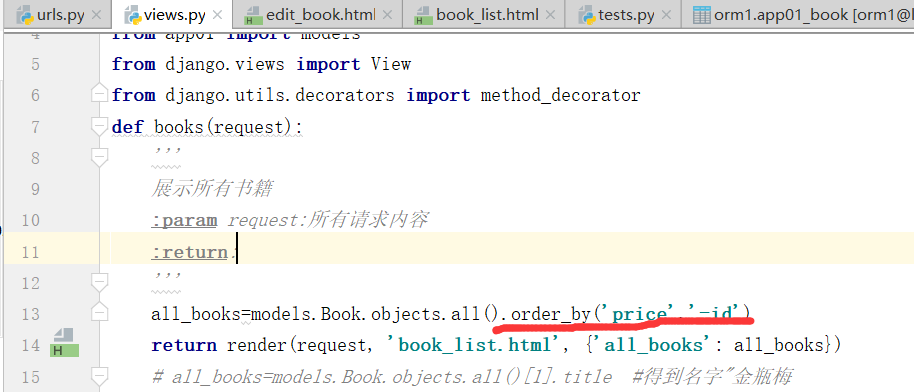
先按照价格排序,再按照id的倒序排序.


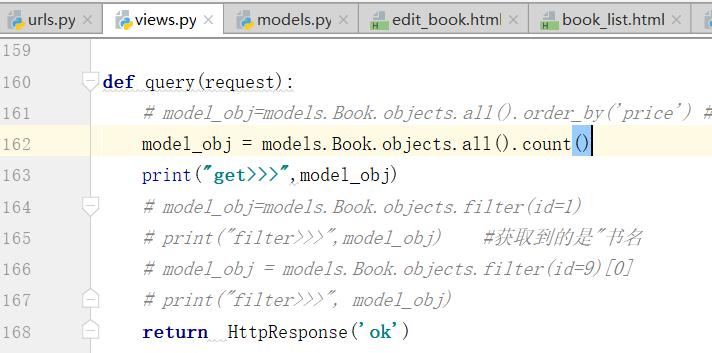
查看总共有多少个对象


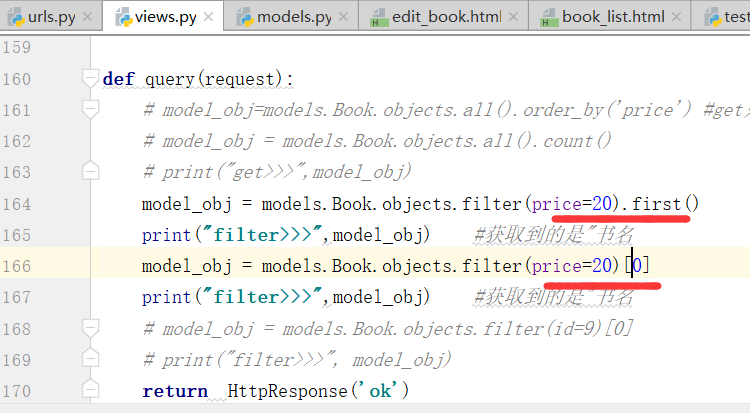

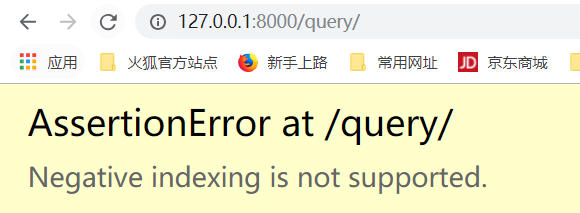
注意,这个地方不支持写-1
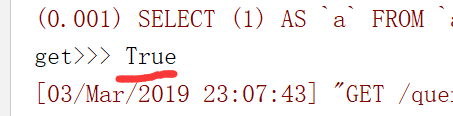
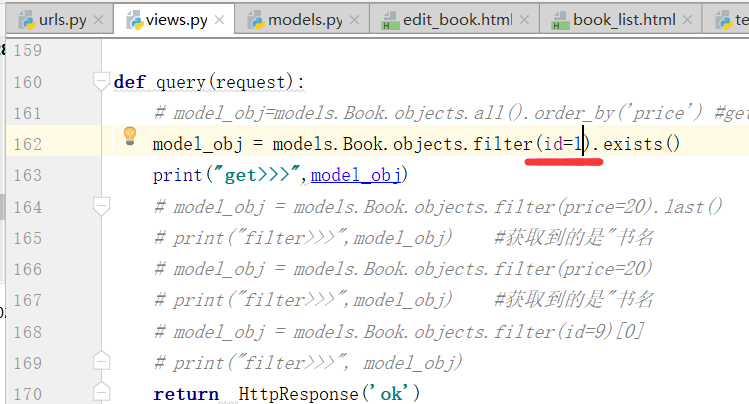
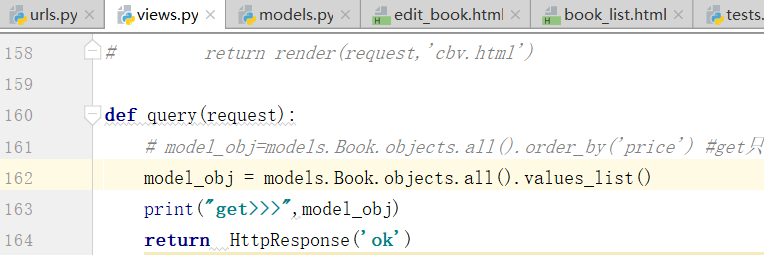
取其中一条进行判断,提高效率,在这个地方如果只写all()的话,效率会比较低

计数用count也是可以的.



values()整个过程类似下图:

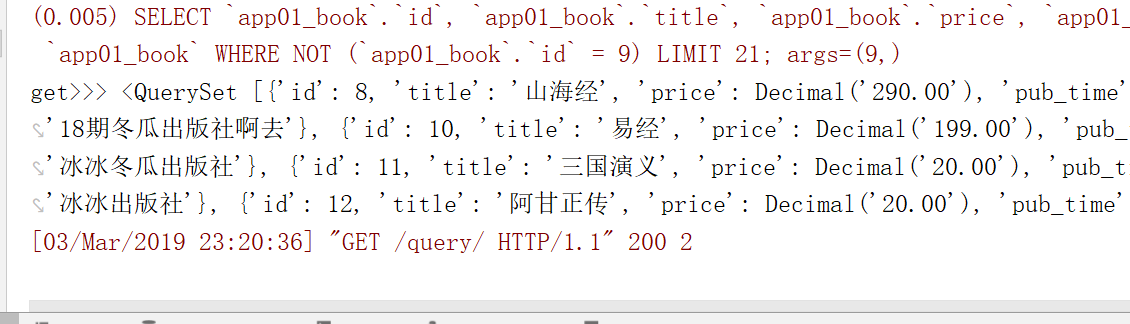
排除id=9的方法
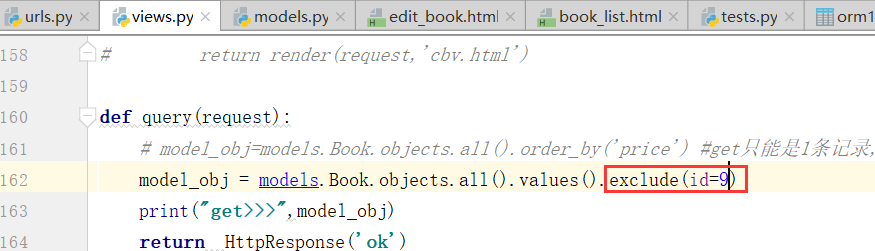
结果已经没有9了
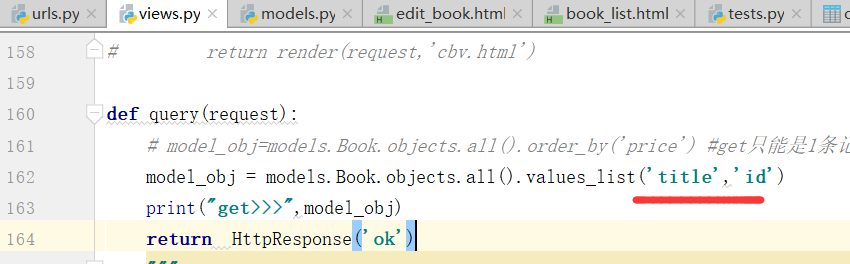
values_list()

最终,里边的数据,变成了元组
参数的妙用,values,也和下图一样
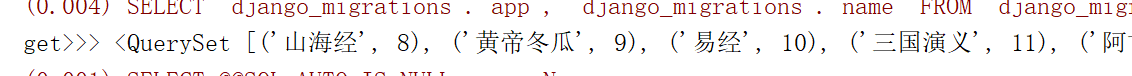


mysql的写法
select distinct name from xxx;
select distinct name title from xxx;
4.单表查询的其他方法
模糊查询:
_:一个字符
%:所有
like
正则
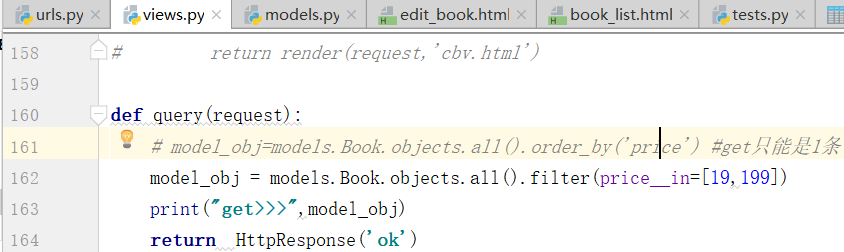
Book.objects.filter(price__in=[,,]) #price值等于这三个里面的任意一个的对象
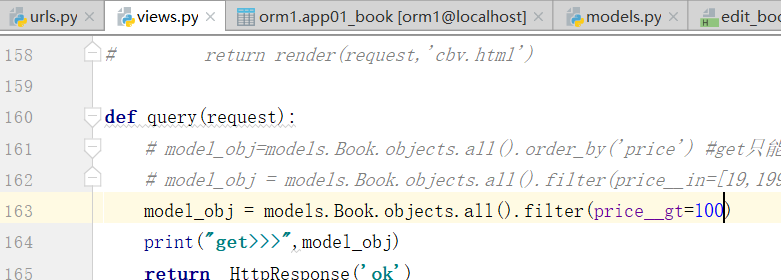
Book.objects.filter(price__gt=) #大于,大于等于是price__gte=,别写price>,这种参数不支持
Book.objects.filter(price__lt=)
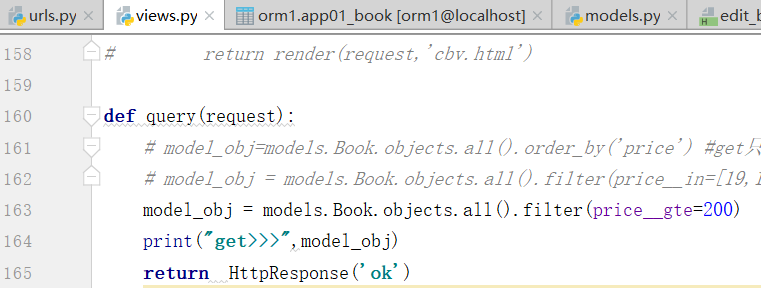
Book.objects.filter(price__range=[,]) #sql的between and,大于等于100,小于等于200
Book.objects.filter(title__contains="python") #title值中包含python的
Book.objects.filter(title__icontains="python") #不区分大小写
Book.objects.filter(title__startswith="py") #以什么开头,istartswith 不区分大小写
Book.objects.filter(pub_date__year=)
面试的SQL语句:多表查询,&&左右连接等等.



因为失去问题,
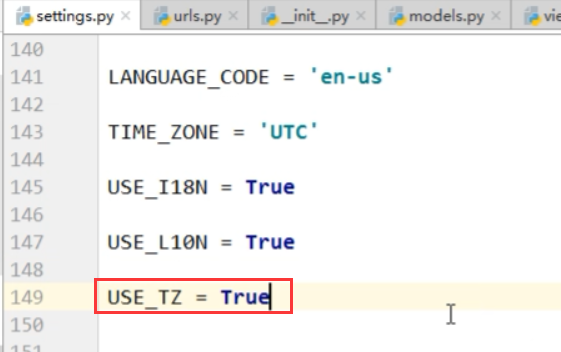
修改下面的属性,变成本地的时间
本地时间localtime和UTC相差8个小时.
注意:
删除的时候get和filter两种方法都能用
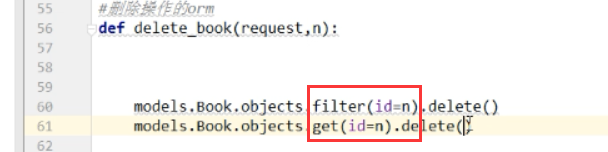
而update更新,必须是queryset(也就是filter),也就是update无法调用models,而必须是queryset类型才能调用更新,不能用get方法

巨蟒python全栈开发django6: FBV&CBV&&单表查询的其他方法的更多相关文章
- 巨蟒python全栈开发django5:组件&&CBV&FBV&&装饰器&&ORM增删改查
内容回顾: 补充反向解析 Html:{% url ‘别名’ 参数 %} Views:reverse(‘别名’,args=(参数,)) 模板渲染 变量 {{ 变量名 }} 逻辑相关 {% %} 过滤器: ...
- 巨蟒python全栈开发-第19天 核能来袭-反射
一.今日主要内容 1.isinstance,type,issubclass A.isinstance: 判断你给对象是否是xx类型的. (向上判断) B.type: 返回xxx对象的数据类型 C.is ...
- 巨蟒python全栈开发django10:ajax&&登录认证
通过题目进行知识点回顾: 聚合查询 From django.db.models import Avg,Min,Max,F,Q,Count,Sum #查询书籍的平均值 Ret= Models.Book. ...
- 巨蟒python全栈开发django8:基于对象和基于双下划线的多表查询
1.编辑删除&&多对多关系的其他方法 提交,数据,得到结果 查看运行 给编辑和删除,添加样式 我们点击删除,可以成功删除 打印sql语句的,在settings.py里边的配置 LOGG ...
- python 全栈开发,Day73(django多表添加,基于对象的跨表查询)
昨日内容回顾 多表方案: 如何确定表关系呢? 表关系是在2张表之间建立的,没有超过2个表的情况. 那么相互之间有2条关系线,先来判断一对多的关系. 如果其中一张表的记录能够对应另外一张表的多条记录,那 ...
- 巨蟒python全栈开发linux之centos1
1.linux服务器介绍 2.linux介绍 3.linux命令学习 linux默认有一个超级用户root,就是linux的皇帝 注意:我的用户名是s18,密码是centos 我们输入密码,点击解锁( ...
- 巨蟒python全栈开发-第20天 核能来袭-约束 异常处理 MD5 日志处理
一.今日主要内容 1.类的约束(对下面人的代码进行限制;项目经理的必备技能,要想走的长远) (1)写一个父类,父类中的某个方法要抛出一个异常 NotImplementedError(重点) (2)抽象 ...
- 巨蟒python全栈开发flask3
首先,我们新建一个项目: 这个时候,我们调用ab函数,可以在所有的模板中使用. 上边是一个特殊装饰器, 1.flask特殊装饰器 下面说几个特殊的装饰器 再请求之前的装饰器 运行: 这个时候,服务端打 ...
- 巨蟒python全栈开发linux之centos6
1.nginx复习 .nginx是什么 nginx是支持反向代理,负载均衡,且可以实现web服务器的软件 在129服务器中查看,我们使用的是淘宝提供的tengine,也是一种nginx服务器 我们下载 ...
随机推荐
- Subl 命令
Subl 是sublime 的命令 添加环境变量后可以,在cmd 或者git 下直接 使用subl 进行 打开sublime Example: Subl 打开编辑器 Subl . 将当 ...
- Js中数组的追加
Concat arrayObject.concat(arrayX,arrayX,......,arrayX) 常用于 加载更多 ,数组的追加.
- ios 自动布局水平跟垂直居中
[view addConstraint:[NSLayoutConstraint constraintWithItem:segment attribute:NSLayoutAttributeCenter ...
- 通过xsd schema结构来验证xml是否合法
import sys import StringIO import lxml from lxml import etree from StringIO import StringIO # Constr ...
- ARM(CM3)的汇编指令
转http://blog.csdn.net/gaojinshan/article/details/11534569 16位数据操作指令 名字 功能ADC 带进位加法(ADD with Carry) ...
- Linux在本地使用yum安装软件
经常遇到有的linux服务器由于特殊原因,不能连接外网,但是经常需要安装一些软件,尤其是在编译一些包的时候经常由于没有安装一些依存包而报的各种各样的错误,当你找到依存的rpm包去安装的时候,又提示你有 ...
- Atitit. servlet 与 IHttpHandler ashx listen 和HttpModule的区别与联系 原理理论 架构设计 实现机制 java php c#.net js javascript c++ python
Atitit. servlet 与 IHttpHandler ashx listen 和HttpModule的区别与联系 原理理论 架构设计 实现机制 java php c#.net j ...
- SQL数据库查询练习题(更正版)
一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四个表的结构分别如表1-1的表(一)~表( ...
- 盘点20款主流应用FPS,最Skr帧率测试方法都在这里!
无论是手机端还是PC端,画面的流畅度一直被用户视为衡量应用视觉体验的重要标准.用户往往通过主观感觉把视觉体验分为两种状态: 流畅视觉:行云流水,一气呵成: 非流畅视觉:“卡顿”.“抖动”.“迟钝 ...
- 如何解决HTML在各种浏览器的兼容性
方法/步骤 不同浏览器对HTML标记所具有的内外边距属性具有不同的定义. 因此如果想消除这种差距,应该在相应的CSS部分加入以下CSS代码: *{margin:0px;padding:0px;} 借于 ...