java集合框架(二):HashTable
HashTable作为集合框架中的一员,现在是很少使用了,一般都是在面试中会问到其与HashMap的区别。为了能在求职的时候用上场,我们有必要对其原理进行解读。
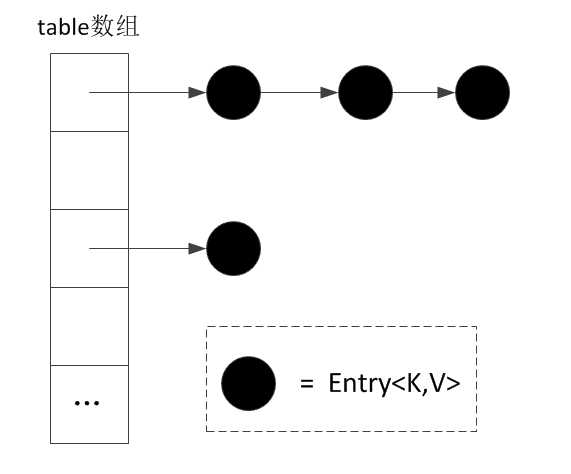
HashTable的实现原理跟HashMap类似,也是通过节点的哈希值映射到哈希桶数组,如果发生哈希碰撞就构建一条链表,简单点说就是:数组+链表
一、类的定义
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {}从以上的定义中,可以发现其继承自Dictionary,而HashMap是继承自AbstractMap。Dictionary是一个字典类,内部定义了一些抽象方法,现在官方也不建议使用了。我的理解也是用来保存key-value的,不过要求key和value都不能为空。
二、存储单元
基本存储单元:
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash; // key算出的哈希值
final K key;
V value;
Entry<K,V> next; // 如果有链表的话指向下一个节点
}哈希桶数组:
private transient Entry<?,?>[] table;三、构造函数
HashTable有四个构造函数,可以按照需要进行选择。一般情况下,如果知道节点数量,可以在初始化的时候指定哈希桶的容量。
// 无参构造器
public Hashtable() {
this(11, 0.75f); // 默认哈希桶初始容量为11,负载因子为0.75
}// 自定义初始哈希桶容量构造器
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}// 自定义容量和负载因子构造器,负载因子一般情况下使用0.75
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
// 初始化哈希桶数组
table = new Entry<?,?>[initialCapacity];
// 初始化扩容阈值,节点超过这个值会进行扩容,其中MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}// 可以在构造器中传入Map,其全部元素会put到新构建的HashTable中
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}四、存储实现
HashTable的put、get方法都使用了同步加锁,所以他们是线程安全的。
1.put方法
// 该方法使用同步加锁
public synchronized V put(K key, V value) {
// Make sure the value is not null
// 值不能为空
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
// key直接获取哈希值,因此key不能为空,否则会抛空指针异常
int hash = key.hashCode();
// 计算在哈希桶的位置
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
// 判断index位置是否为空,不为空判断hash和key是否相等,相等的话覆盖原有的value
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
// 添加新节点
addEntry(hash, key, value, index);
return null;
}// 添加新节点到哈希桶
private void addEntry(int hash, K key, V value, int index) {
// 修改数加一,fast-fail机制
modCount++;
Entry<?,?> tab[] = table;
// 判断是否需要扩容,节点总数等于等于阈值就会扩容,阈值一般等于容量乘以0.75
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
// 计算index位置
index = (hash & 0x7FFFFFFF) % tab.length;
}
// 创建新的节点,并放到哈希桶中,如果有链表则是链表的头部
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
// 节点总数加一
count++;
} 2.get方法
// 同步加锁
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
// 根据hash值计算在哈希桶的位置
int index = (hash & 0x7FFFFFFF) % tab.length;
// 如果哈希桶的位置上是链表,则遍历链表找到hash值和key都相等的对象
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}五、扩容机制
HashTable的扩容是把原来的容量扩大为2倍加一,并把旧哈希桶的节点重新计算哈希映射到新的哈希桶
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// 新容量等于旧容量的两倍加1,不太清楚为什么要加一,我估计是为了平均节点到哈希桶,减少哈希碰撞
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
// 如果就容量已经达到最大值就不在扩容了,MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8
if (oldCapacity == MAX_ARRAY_SIZE)
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
// 计算阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 从哈希桶的最后位置遍历旧节点到新的哈希桶,这个过程比较耗性能,
// 需要重新指定每个节点位置,重新构建链表的组成
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
// 如果是链表则在头部插入新的节点
newMap[index] = e;
}
}
}六、遍历实现
HashTable的遍历操作也是线程安全的,通过调用Collections.synchronizedSet()的方法,给遍历操作加了一个包装器。里面对key、value或者key-value的遍历实现还是挺有借鉴意思的,它用泛型只要写一次代码就可以实现三种遍历方式。
// 该方法返回一个Set,其实遍历只需要迭代器,entrySet返回的Set对象实现了迭代器
public Set<Map.Entry<K,V>> entrySet() {
if (entrySet==null)
// 返回线程安全的集合类,这里是通过线程安全的方法对目标方法做了一层包装
entrySet = Collections.synchronizedSet(new EntrySet(), this);
return entrySet;
}简单看看EntrySet的实现
// 只看迭代器部分
private class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return getIterator(ENTRIES);
}
}private <T> Iterator<T> getIterator(int type) {
// 判断节点数是否为0
if (count == 0) {
return Collections.emptyIterator();
} else {
return new Enumerator<>(type, true);
}
}// HashTable的内部类,可以共用外部类的属性和方法
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
Entry<?,?>[] table = Hashtable.this.table;
int index = table.length;
Entry<?,?> entry = null;
Entry<?,?> lastReturned = null;
int type;
boolean iterator;
protected int expectedModCount = modCount;
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
public boolean hasMoreElements() {
Entry<?,?> e = entry;
int i = index;
Entry<?,?>[] t = table;
// 从哈希桶的最后遍历节点
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
}
@SuppressWarnings("unchecked")
public T nextElement() {
Entry<?,?> et = entry;
int i = index;
Entry<?,?>[] t = table;
// 如果当前节点为空,表示index位置的节点遍历完了,则继续遍历哈希桶
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
Entry<?,?> e = lastReturned = entry;
entry = e.next;
// 这里使用了泛型可以返回key,value或者key-value对象
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
// 迭代器方法
public boolean hasNext() {
return hasMoreElements();
}
// 迭代器方法
public T next() {
// fast-fail机制
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
}
// 迭代器方法,删除节点
public void remove() {
if (!iterator)
throw new UnsupportedOperationException();
if (lastReturned == null)
throw new IllegalStateException("Hashtable Enumerator");
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
synchronized(Hashtable.this) {
Entry<?,?>[] tab = Hashtable.this.table;
int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length;
// 找出当前要删除的节点在哈希桶的位置
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
// 遍历index位置的链表
for(Entry<K,V> prev = null; e != null; prev = e, e = e.next) {
// 找出当前遍历的节点
if (e == lastReturned) {
modCount++;
expectedModCount++;
// 判断是否在链表的头部
if (prev == null)
tab[index] = e.next;
else
prev.next = e.next;
count--;
lastReturned = null;
return;
}
}
throw new ConcurrentModificationException();
}
}
}七、总结
HashTable的数据结构跟HashMap类似,下面总结一下他们的区别:
- key-value是否可以为空。HashTable的key和value都不可以为空,为空会报空指针异常。HashMap的key,value都可以为空,但是key只能有一个为null,value都可以为空。
- 是否线程安全。HashTable操作节点的方法都是同步加锁的,所以是线程安全的。HashMap不是线程安全的。
- 类继承关系是否一样。HashTable继承Dictionary。HashMap继承AbstractMap。
- 初始容量。HashTable初始容量为11。HashMap初始容量为16。
- 最大容量(哈希桶的容量,不是存储元素的容量)。HashTable最大为Integer.MAX_VALUE - 8=2147483639。HashMap最大为1<<30=1073741824。
以上就是我对HashTable的解读,如果有错误之处,欢迎批评和指正。
java集合框架(二):HashTable的更多相关文章
- (Set, Map, Collections工具类)JAVA集合框架二
Java集合框架部分细节总结二 Set 实现类:HashSet,TreeSet HashSet 基于HashCode计算元素存放位置,当计算得出哈希码相同时,会调用equals判断是否相同,相同则拒绝 ...
- java 集合框架(二)Iterable接口
Iterable接口是java 集合框架的顶级接口,实现此接口使集合对象可以通过迭代器遍历自身元素,我们可以看下它的成员方法 修饰符和返回值 方法名 描述 Iterator<T> iter ...
- Java集合框架(二)
Set Set:无序,不可以重复元素. |--------HashSet:数据结构是哈希表. 线程是非同步的.保证元素唯一性的原理是:判断元素的hashCode值是否相同,如果相同,还会继续判断元素的 ...
- 深入理解java集合框架之---------HashTable集合
HashTable是什么 HashTable是基于哈希表的Map接口的同步实现 HashTable中元素的key是唯一的,value值可重复 HashTable中元素的key和value不允许为nul ...
- (二)java集合框架综述
一集合框架图 说明:对于以上的框架图有如下几点说明 1.所有集合类都位于java.util包下.Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Ja ...
- Java集合框架源码(二)——hashSet
注:本人的源码基于JDK1.8.0,JDK的版本可以在命令行模式下通过java -version命令查看. 在前面的博文(Java集合框架源码(一)——hashMap)中我们详细讲了HashMap的原 ...
- 浅谈JAVA集合框架
浅谈JAVA集合框架 Java提供了数种持有对象的方式,包括语言内置的Array,还有就是utilities中提供的容器类(container classes),又称群集类(collection cl ...
- 【JAVA集合框架之Map】
一.概述.1.Map是一种接口,在JAVA集合框架中是以一种非常重要的集合.2.Map一次添加一对元素,所以又称为“双列集合”(Collection一次添加一个元素,所以又称为“单列集合”)3.Map ...
- Java集合框架使用总结
Java集合框架使用总结 前言:本文是对Java集合框架做了一个概括性的解说,目的是对Java集合框架体系有个总体认识,如果你想学习具体的接口和类的使用方法,请参看JavaAPI文档. 一.概述数据结 ...
- Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
随机推荐
- [BZOJ2879][Noi2012]美食节(费用流)
题目描述 CZ市为了欢迎全国各地的同学,特地举办了一场盛大的美食节.作为一个喜欢尝鲜的美食客,小M自然不愿意错过这场盛宴.他很快就尝遍了美食节所有的美食.然而,尝鲜的欲望是难以满足的.尽管所有的菜品都 ...
- vmware vSphere虚拟网络之标准交换机(二)
一.标准交换机的特点: 1)只能用于物理主机 2)其他主机不能共享同一个虚拟交换机 3)不具备任何灵活性 4)每台ESXi主机都要配置一遍 二.网络图: 三.创建标准交换机: 登录web vCente ...
- Python之路Python文件操作
Python之路Python文件操作 一.文件的操作 文件句柄 = open('文件路径+文件名', '模式') 例子 f = open("test.txt","r&qu ...
- JDBC_PreparedStatement用法_占位符_参数处理
import java.sql.Connection; import java.sql.Date;import java.sql.DriverManager;import java.sql.Prepa ...
- SQLServer如何清除缓存?
--1. 将当前数据库的全部脏页写入磁盘.“脏页”是已输入缓存区高速缓存且已修改但尚未写入磁盘的数据页. -- CHECKPOINT 可创建一个检查点,在该点保证全部脏页都已写入磁盘,从而在以后的恢复 ...
- js 删除removeChild与替换replaceChild
<input type="button" value="删除" id="btn" /> <input type=" ...
- angularjs指令弹框点击空白处隐藏及常规方法
效果图展示: 第一种方法:angularjs自定义指令: 指令: app.directive('onBlankHide', function () { return { restrict: 'A', ...
- Day45--js基本小结
JavaScript基本总结 一:基本背景 01:注:ES6就是指ECMAScript 6.(2015 ECMAScript6 添加类和模块) ECMAScript和JavaScript的关系 199 ...
- hibernate自动生成时报错问题
创建好了实体类和.hbm.xml文件,运行项目报上错: 实体类和xml文件中的字段要一致.(顺序和字段)
- LCT小小结
模板题P3690 基础题P3203[HNOI2010]弹飞绵羊 \(access\)是搞出一条端点为\(x,y\)的路径 , 且维护的是实子树的信息 . 由于题目比较简单 , \(access\)时还 ...