viterbi维特比算法和隐马尔可夫模型(HMM)
原文地址:http://www.cnblogs.com/jacklu/p/7753471.html
本文结合了王晓刚老师的ENGG 5202 Pattern Recognition课程内容知识,和搜集的资料和自己理解的总结。
1 概述
隐马尔可夫模型(Hidden Markov Model,HMM)是结构最简单的贝叶斯网,这是一种著名的有向图模型,主要用于时序数据建模(语音识别、自然语言处理等数据在时域有依赖性的问题)。
如果考虑t时刻数据依赖于0到t-1时间段的所有数据,即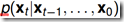 ,在计算复杂度上是不可行的。因此Markov Model假定只依赖于最近的几个观测数据。
,在计算复杂度上是不可行的。因此Markov Model假定只依赖于最近的几个观测数据。
下面先从一个直观的例子理解HMM:
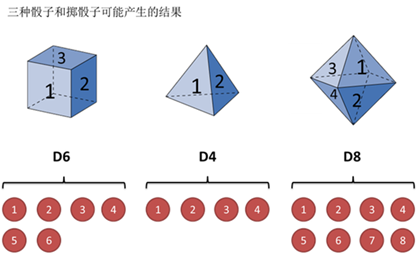
假设有三个不同的骰子(6面、4面、8面),每次先从三个骰子里选一个,每个骰子选中的概率为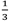 ,如下图所示,重复上述过程,得到一串数字[1 6 3 5 2 7]。这些可观测变量组成可观测状态链。
,如下图所示,重复上述过程,得到一串数字[1 6 3 5 2 7]。这些可观测变量组成可观测状态链。
同时,在隐马尔可夫模型中还有一条由隐变量组成的隐含状态链,在本例中即骰子的序列。比如得到这串数字骰子的序列可能为[D6 D8 D8 D6 D4 D8]。
隐马尔可夫模型示意图如下所示:
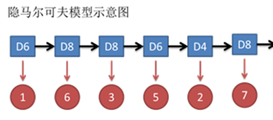
图中,箭头表示变量之间的依赖关系。在任意时刻,观测变量(骰子点数)仅依赖于状态变量(哪类骰子),“观测独立性假设”。
同时,t时刻数据依赖于t-1时刻的数据。这就是1阶马尔可夫链,即系统的下一时刻的状态仅由当前状态决定不依赖以往的任何状态(无记忆性),“齐次马尔可夫性假设”。
0阶Markov Model:
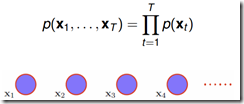
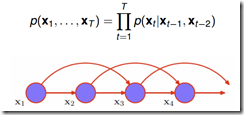
1阶Markov Model:

2阶Markov Model:
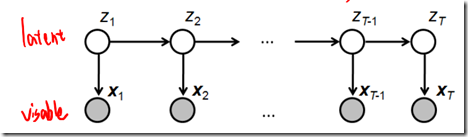
1阶HMM
包含状态变量(也叫latent variable,该变量是离散的、未知的、待推断的) 和观测变量(该变量可以是离散的、也可以是连续的)
和观测变量(该变量可以是离散的、也可以是连续的) ,如下图所示:
,如下图所示:
其联合分布: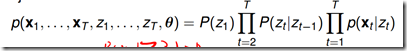
1.2 HMM中的条件独立(在后续算法推导中非常重要)
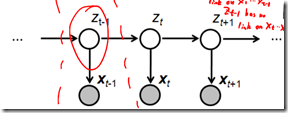
从概率图模型上给出条件独立的式子非常简单,即遮住某一节点,被分开的路径在给定该节点时独立。
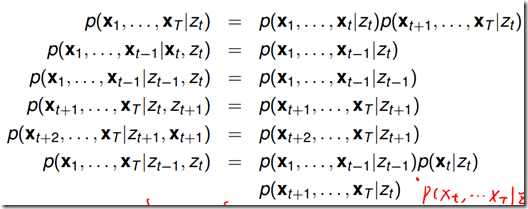
上面六个式子,前五个式子很容易从图模型中理解。最后一个式子可以将左边写成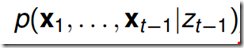 和
和 的乘积,然后再将
的乘积,然后再将 做分解。
做分解。
假定每个状态有三种取值 ,比如上面骰子的种类。参数如下图所示:
,比如上面骰子的种类。参数如下图所示:
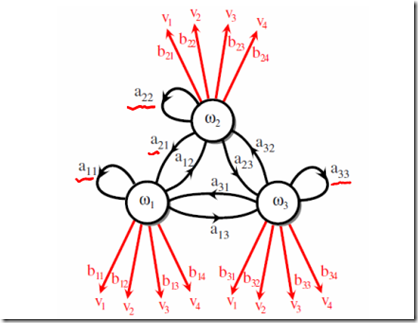
初始状态参数
状态转移概率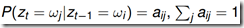 ,即
,即
观测概率(也叫emission probablity)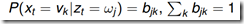 ,即时刻t、状态
,即时刻t、状态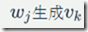 的概率
的概率
2 隐马尔可夫模型三要素
以上三个参数构成隐马尔可夫模型三要素:
状态转移概率矩阵A, 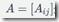
观测概率矩阵B,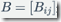
初始状态概率向量
一个隐马尔可夫模型可由 来指代。
来指代。
3 隐马尔可夫模型的三个基本问题
(1) 给定模型 ,计算其产生观测序列
,计算其产生观测序列 的概率
的概率 , 称作evaluation problem,比如:计算掷出点数163527的概率
, 称作evaluation problem,比如:计算掷出点数163527的概率
(2) 给定模型 和观测序列
和观测序列 ,推断能够最大概率产生此观测序列的状态序列
,推断能够最大概率产生此观测序列的状态序列 ,即使求解
,即使求解 ,称作decoding problem,比如:推断掷出点数163527的骰子种类
,称作decoding problem,比如:推断掷出点数163527的骰子种类
(3) 给定观测序列 ,估计模型
,估计模型 的参数,使计算其产生观测序列的概率
的参数,使计算其产生观测序列的概率 最大,称作learning problem,比如:已知骰子有几种,不知道骰子的种类,根据多次掷出骰子的结果,反推出骰子的种类
最大,称作learning problem,比如:已知骰子有几种,不知道骰子的种类,根据多次掷出骰子的结果,反推出骰子的种类
这三个基本问题在现实应用中非常重要,例如根据观测序列推测当前时刻最有可能出现的观测值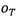 ,这就是基本问题(1);
,这就是基本问题(1);
在语音识别中,观测值为语音信号,隐藏状态为文字,根据观测信号推断最有可能的状态序列,即基本问题(2);
在大多数应用中,人工指定参数模型已变得越来越不可行,如何根据训练样本学得最优参数模型,就是基本问题(3)。
4 三个基本问题的解法
基于两个条件独立假设,隐马尔可夫模型的这三个基本问题均能被高效求解。
4.1 基本问题(1)evaluation problem解法
4.1.1 直接计算法(概念上可行,计算上不可行)
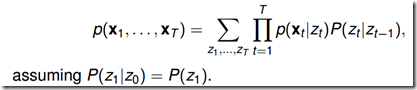
通过列举所有可能的长度为T的状态序列 ,求各个状态序列与观测序列同时出现的联合概率
,求各个状态序列与观测序列同时出现的联合概率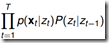 ,然后对所有可能求和。
,然后对所有可能求和。
计算复杂度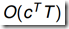 ,C是状态个数。算法不可行。
,C是状态个数。算法不可行。
4.1.2 前向算法(t=1,一步一步向前计算)
前向概率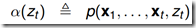 ,表示模型
,表示模型 ,时刻 t,观测序列为
,时刻 t,观测序列为 且状态为
且状态为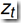 的概率。
的概率。

注意求和式中有K项(Z的状态数),计算复杂度为C*C。
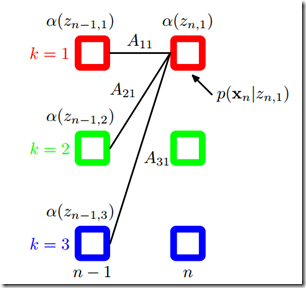
通过上式可知,为了得到前向概率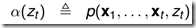 ,可以先初始化t=1时刻的概率,然后从第一个节点开始递推计算,每次递推都需要计算一次c*c的的操作,因此总的算法复杂度是
,可以先初始化t=1时刻的概率,然后从第一个节点开始递推计算,每次递推都需要计算一次c*c的的操作,因此总的算法复杂度是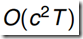 (C和K相同)
(C和K相同)
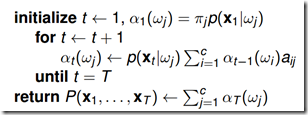
4.1.3 后向算法
后向概率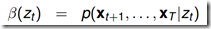 ,表示模型
,表示模型 ,时刻 t,观测序列为
,时刻 t,观测序列为 且状态为
且状态为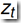 的概率。
的概率。
推导过程:
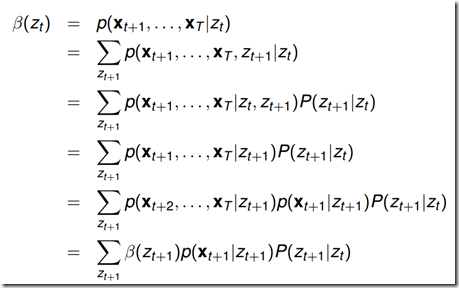
通过上式可知,为了得到后向概率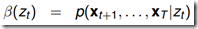 ,可以先初始化t=T时刻的概率,然后从最后一个节点向前递推计算,每次递推都需要计算一次c*c的的操作,因此总的算法复杂度是
,可以先初始化t=T时刻的概率,然后从最后一个节点向前递推计算,每次递推都需要计算一次c*c的的操作,因此总的算法复杂度是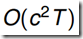 (C和K相同)
(C和K相同)
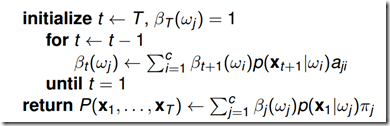
算法高效的关键是其局部计算前向概率,根据路径结构,如下图所示,每次计算直接利用前一时刻计算结果,避免重复计算,减少计算量。
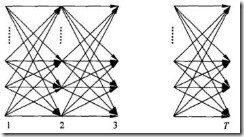
利用前向概率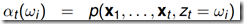 和后向概率
和后向概率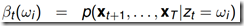 可以计算:
可以计算:
整个观测序列的概率 :
:

给定观测序列,t时刻的状态后验概率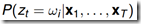 :
:
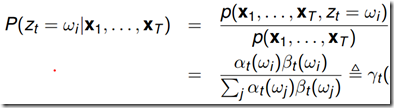
给定观测序列,t时刻从某一状态,在t+1时刻转换成新的状态的后验概率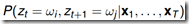 :
:
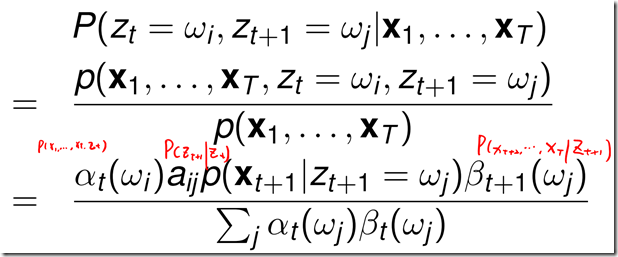
4.2 基本问题(2)decoding problem解法
4.2.1 近似算法
选择每一时刻最有可能出现的状态,即根据上述计算t时刻的状态后验概率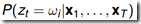 ,选择概率最大的状态,从而得到一个状态序列。这个方法计算简单,此方法但是不能保证整个状态序列的出现概率最大。因为可能两个相邻的状态转移概率为0,即实际上不可能发生这种状态转换。
,选择概率最大的状态,从而得到一个状态序列。这个方法计算简单,此方法但是不能保证整个状态序列的出现概率最大。因为可能两个相邻的状态转移概率为0,即实际上不可能发生这种状态转换。
4.2.2 Viterbi算法
使用动态规划求解概率最大(最优)路径。t=1时刻开始,递推地计算在时刻t状态为i的各条部分路径的最大概率,直到计算到时刻T,状态为i的各条路径的最大概率,时刻T的最大概率即为最优路径的概率,最优路径的节点也同时得到。
如果还不明白,看一下李航《统计学习方法》的186-187页的例题就能明白算法的原理。
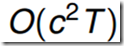
考虑一个表格数据结构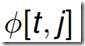 ,存储着t时刻时,状态为j的能够产生观测序列
,存储着t时刻时,状态为j的能够产生观测序列 的最大概率值。
的最大概率值。
t=1时,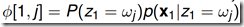
t>1时
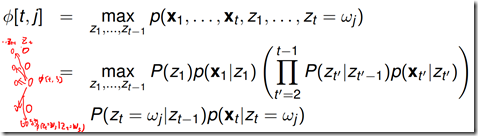
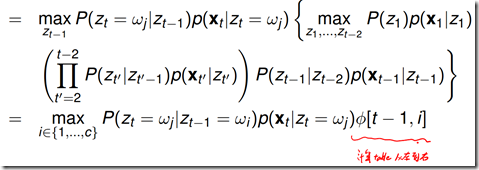
维特比算法:

使用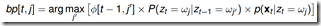 记录求解的状态序列。
记录求解的状态序列。
维特比算法图示:
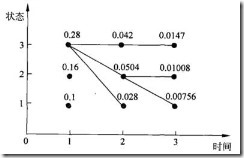
状态[3 3 3]极为概率最大路径。
4.3 基本问题(3)解法
4.3.1 监督学习方法
给定T个长度相同的(观测序列,状态序列)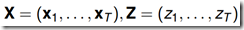 作为训练集,使用极大似然估计法来估计模型参数。
作为训练集,使用极大似然估计法来估计模型参数。
转移概率 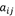 的估计:样本中t时刻处于状态i,t+1时刻转移到状态j的频数为
的估计:样本中t时刻处于状态i,t+1时刻转移到状态j的频数为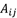 ,则
,则
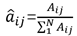
观测概率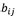 和初始状态概率
和初始状态概率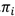 的估计类似。
的估计类似。
4.3.2 Baum-Welch算法
使用EM算法得到模型参数估计式
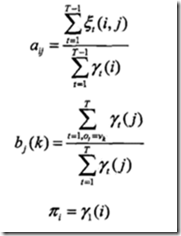
EM算法是常用的估计参数隐变量的利器,它是一种迭代方法,基本思想是:
(1) 选择模型参数初始值;
(2) (E步)根据给定的观测数据和模型参数,求隐变量的期望;


(3) (M步)根据已得隐变量期望和观测数据,对模型参数做极大似然估计,得到新的模型参数,重复第二步。

作业题:

第一问用于理解HMM产生数据的过程,第二问用于理解维特比算法。
自己写的答案(运行结果如上图):

1 import numpy
2 import random
3
4 def random_pick(pick_list,probability_list):
5 x=random.uniform(0,1)
6 cumulative_probability=0.0
7 for item,item_probability in zip(pick_list,probability_list):
8 cumulative_probability+=item_probability
9 if x < cumulative_probability: break
10 return item
11
12 Zt=[1,2]
13 Pi=[0.6,0.4]
14 Xt=[1,2,3]
15 a1j=[0.7, 0.3]
16 a2j=[0.4, 0.6]
17 b1j=[0.1, 0.4, 0.5]
18 b2j=[0.6, 0.3, 0.1]
19 x=[-1 for n in range(10)]
20 z=[-1 for n in range(10)]
21 #for function test
22 #temp_counter = 0
23 #for i in range(100):
24 # if random_pick(Zt,Pi) == 1: temp_counter+=1
25 #print(temp_counter)
26 ##for function test
27
28 z[0] = random_pick(Zt,Pi)
29 for i in range(10):
30 if z[i] == 1:
31 x[i] = random_pick(Xt, b1j)
32 if i < 9: z[i+1] = random_pick(Zt, a1j)
33 else:
34 x[i]= random_pick(Xt, b2j)
35 if i < 9: z[i+1]= random_pick(Zt, a2j)
36 print(z)
37 print(x)
38
39 bp=[-1 for n in range(10)]
40 Fi=[[-1,-1] for n in range(10)]
41 for i in range(2):
42 if i == 0:
43 Fi[0][0]=Pi[i]*b1j[x[0]-1]
44 print('Fi00',Fi[0][0])
45 elif i == 1:
46 Fi[0][1]=Pi[i]*b2j[x[0]-1]
47 print('Fi01',Fi[0][1])
48 if Fi[0][0] < Fi[0][1]:
49 bp[0] = 1
50 else:
51 bp[0] = 0
52
53 for t in range(9):
54 for j in range(2):
55 if j == 0:
56 if bp[t] == 0:
57 Fi[t+1][j]=Fi[t][0]*a1j[0]*b1j[x[t+1]-1]
58 elif bp[t] == 1:
59 Fi[t+1][j]=Fi[t][1]*a2j[0]*b1j[x[t+1]-1]
60 if j == 1:
61 if bp[t] == 0:
62 Fi[t+1][j]=Fi[t][0]*a1j[1]*b2j[x[t+1]-1]
63 elif bp[t] == 1:
64 Fi[t+1][j]=Fi[t][1]*a2j[1]*b2j[x[t+1]-1]
65 print('Fit0',Fi[t+1][0])
66 print('Fit1',Fi[t+1][1])
67 if Fi[t+1][0] < Fi[t+1][1]:
68 bp[t+1] = 1
69 else:
70 bp[t+1] = 0
71
72 print(bp)#z=bp+1
参考资料:
CUHK 王晓刚老师的ENGG 5202 Pattern Recognition 课堂讲义
《机器学习》周志华
《统计学习方法》李航
如何用简单易懂的例子解释隐马尔可夫模型https://www.zhihu.com/question/20962240
《Pattern Classification》
《PRML》
viterbi维特比算法和隐马尔可夫模型(HMM)的更多相关文章
- 隐马尔可夫模型HMM与维特比Veterbi算法(二)
隐马尔可夫模型HMM与维特比Veterbi算法(二) 主要内容: 前向算法(Forward Algorithm) 穷举搜索( Exhaustive search for solution) 使用递归降 ...
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 隐马尔可夫模型HMM与维特比Veterbi算法(一)
隐马尔可夫模型HMM与维特比Veterbi算法(一) 主要内容: 1.一个简单的例子 2.生成模式(Generating Patterns) 3.隐藏模式(Hidden Patterns) 4.隐马尔 ...
- 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态 ...
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 用hmmlearn学习隐马尔科夫模型HMM
在之前的HMM系列中,我们对隐马尔科夫模型HMM的原理以及三个问题的求解方法做了总结.本文我们就从实践的角度用Python的hmmlearn库来学习HMM的使用.关于hmmlearn的更多资料在官方文 ...
- HMM:隐马尔可夫模型HMM
http://blog.csdn.net/pipisorry/article/details/50722178 隐马尔可夫模型 隐马尔可夫模型(Hidden Markov Model,HMM)是统计模 ...
随机推荐
- Java集合类——Set、List、Map、Queue接口
目录 Java 集合类的基本概念 Java 集合类的层次关系 Java 集合类的应用场景 一. Java集合类的基本概念 在编程中,常需要集中存放多个数据,数组是一个很好的选择,但数组的长度需提前指定 ...
- linux命令之文件系统权限操作常用命令
1. umask:设置权限掩码 语法:umask [参数] 命令说明:umask可以单独使用,可以设置目录与文件的默认权限,默认权限掩码是022,所以默认目录权限是777-022=755,读权限是 ...
- 五、RegExp(正则表达式)篇
正则表达式,只用记住: 0./pattern/igm i--不区分大小写 g--找到所有相匹配的 m--多行匹配 可以只写其中一个 ps:/pattern/i (无视大小写) 1." ...
- 微信小程序关于tabbar点击切换数据不刷新问题
微信小程序中经常遇到的需求就是我提交了一个表单或者进行了一个操作,需要在我的个人中心页面中实时显示出来,但是小程序中的tabbar切换类似于tab切换 并不会进行页面刷新请求 所以总是会造成一些数据更 ...
- 用pathon实现计算器功能
实现计算类似公式的计算器程序1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3* ...
- 网站apache环境S2-057漏洞 利用POC 远程执行命令漏洞复现
S2-057漏洞,于2018年8月22日被曝出,该Struts2 057漏洞存在远程执行系统的命令,尤其使用linux系统,apache环境,影响范围较大,危害性较高,如果被攻击者利用直接提权到服务器 ...
- Java学习笔记六:Java的流程控制语句之if语句
Java的流程控制语句之if语句 一:Java条件语句之if: 我们经常需要先做判断,然后才决定是否要做某件事情.例如,如果考试成绩大于 90 分,则奖励一朵小红花 .对于这种“需要先判断条件,条件满 ...
- 10-C++远征之模板篇-学习笔记
C++远征之模板篇 将会学到的内容: 模板函数 & 模板类 -> 标准模板类 友元函数 & 友元类 静态数据成员 & 静态成员函数 运算符重载: 一切皆有可能 友元函数 ...
- backtrace函数
1.函数原型 #include <execinfo.h> int backtrace(void **buffer, int size); 该函数获取当前线程的调用堆栈,获取的信息将会被存放 ...
- class实现Stack
基于class实现一个存储string类型的Stack 头文件: //stack.h #include<vector> #include<string> class Stack ...