Activiti工作流数据库表结构
Activiti工作流引擎数据库表结构
数据库表的命名
Acitiviti数据库中表的命名都是以ACT_开头的。第二部分是一个两个字符用例表的标识。此用例大体与服务API是匹配的。
ACT_RE_*:’RE’表示repository。带此前缀的表包含的是静态信息,如,流程定义,流程的资源(图片,规则等)。
ACT_RU_*:’RU’表示runtime。这是运行时的表存储着流程变量,用户任务,变量,职责(job)等运行时的数据。Activiti只存储实例执行期间的运行时数据,当流程实例结束时,将删除这些记录。这就保证了这些运行时的表小且快。
ACT_ID_*:’ID’表示identity。这些表包含标识的信息,如用户,用户组,等等。
ACT_HI_*:’HI’表示history。就是这些表包含着历史的相关数据,如结束的流程实例,变量,任务,等等。
ACT_GE_*:普通数据,各种情况都使用的数据。
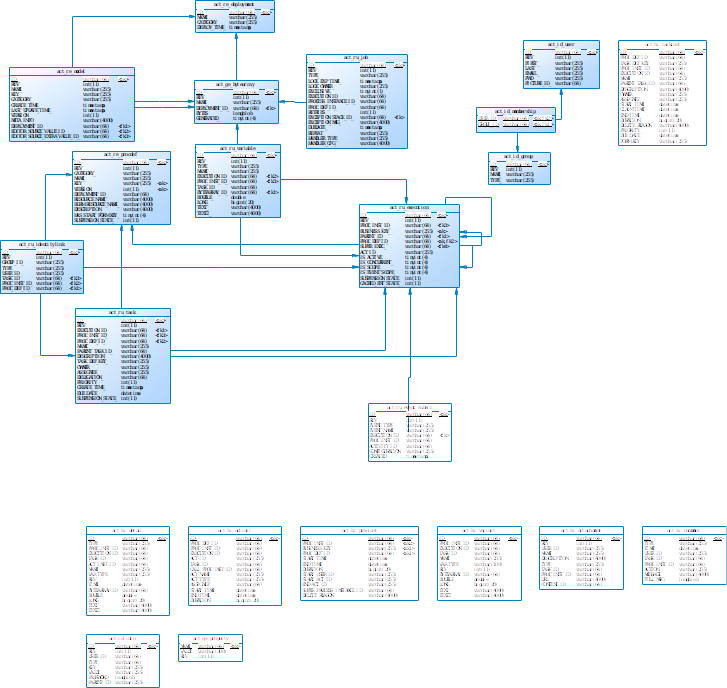
数据库表结构图

数据库表结构说明
ACT_GE_PROPERTY:属性数据表。存储这个流程引擎级别的数据。
NAME_:属性名称
VALUE_:属性值
REV_INT:版本号
ACT_GE_BYTEARRAY:用来保存部署文件的大文本数据
ID_:资源文件编号,自增长
REV_INT:版本号
NAME_:资源文件名称
DEPLOYMENT_ID_:来自于父表ACT_RE_DEPLOYMENT的主键
BYTES_:大文本类型,存储文本字节流
ACT_RE_DEPLOYMENT:用来存储部署时需要持久化保存下来的信息
ID_:部署编号,自增长
NAME_:部署包的名称
DEPLOY_TIME_:部署时间
ACT_RE_PROCDEF:业务流程定义数据表
ID_:流程ID,由“流程编号:流程版本号:自增长ID”组成
CATEGORY_:流程命名空间(该编号就是流程文件targetNamespace的属性值)
NAME_:流程名称(该编号就是流程文件process元素的name属性值)
KEY_:流程编号(该编号就是流程文件process元素的id属性值)
VERSION_:流程版本号(由程序控制,新增即为1,修改后依次加1来完成的)
DEPLOYMENT_ID_:部署编号
RESOURCE_NAME_:资源文件名称
DGRM_RESOURCE_NAME_:图片资源文件名称
HAS_START_FROM_KEY_:是否有Start
From Key
注:此表和ACT_RE_DEPLOYMENT是多对一的关系,即,一个部署的bar包里可能包含多个流程定义文件,每个流程定义文件都会有一条记录在ACT_REPROCDEF表内,每个流程定义的数据,都会对于ACT_GE_BYTEARRAY表内的一个资源文件和PNG图片文件。和ACT_GE_BYTEARRAY的关联是通过程序用ACT_GE_BYTEARRAY.NAME与ACT_RE_PROCDEF.NAME_完成的,在数据库表结构中没有体现。
ACT_ID_GROUP:用来存储用户组信息。
ID_:用户组名*
REV_INT:版本号
NAME_:用户组描述信息*
TYPE_:用户组类型
ACT_ID_MEMBERSHIP:用来保存用户的分组信息
USER_ID_:用户名
GROUP_ID_:用户组名
ACT_ID_USER:
ID_:用户名
REV_INT:版本号
FIRST_:用户名称
LAST_:用户姓氏
EMAIL_:邮箱
PWD_:密码
ACT_RU_EXECUTION:
ID_:
REV_:版本号
PROC_INST_ID_:流程实例编号
BUSINESS_KEY_:业务编号
PARENT_ID_:找到该执行实例的父级,最终会找到整个流程的执行实例
PROC_DEF_ID_:流程ID
SUPER_EXEC_:
引用的执行模板ACT_ID_:节点id
IS_ACTIVE_:
是否访问IS_CONCURRENT_:
IS_SCOPE_:
ACT_RU_TASK:运行时任务数据表。
ID_:
REV_:
EXECUTION_ID_:
执行实例的idPROC_INST_ID_:
流程实例的idPROC_DEF_ID_:
流程定义的id,对应act_re_procdef
的id_NAME_:
任务名称,对应 ***task
的namePARENT_TASK_ID_
: 对应父任务DESCRIPTION_:
TASK_DEF_KEY_:
***task
的idOWNER_ :
发起人ASSIGNEE_:
分配到任务的人DELEGATION_
: 委托人PRIORITY_:
紧急程度CREATE_TIME_:
发起时间DUE_TIME_:审批时长
ACT_RU_IDENTITYLINK:任务参与者数据表。主要存储当前节点参与者的信息。
ID_:
标识REV_:
版本GROUP_ID_:
组织idTYPE_:
类型USER_ID_:
用户idTASK_ID_:
任务id
ACT_RU_VARIABLE:运行时流程变量数据表。
ID_:标识
REV_:版本号
TYPE_:数据类型
NAME_:变量名
EXECUTION_ID_:
执行实例idPROC_INST_ID_:
流程实例idTASK_ID_:
任务idBYTEARRAY_ID_:
DOUBLE_:若数据类型为double
,保存数据在此列LONG_:
若数据类型为Long保存数据到此列TEXT_:
string
保存到此列TEXT2_:
ACT_HI_PROCINST:
ID_
: 唯一标识PROC_INST_ID_
: 流程IDBUSINESS_KEY_
: 业务编号PROC_DEF_ID_
:
流程定义idSTART_TIME_
: 流程开始时间ENT__TIME
: 结束时间DURATION_
: 流程经过时间START_USER_ID_
: 开启流程用户idSTART_ACT_ID_
: 开始节点END_ACT_ID_:
结束节点SUPER_PROCESS_INSTANCE_ID_
: 父流程流程idDELETE_REASON_
: 从运行中任务表中删除原因
ACT_HI_ACTINST:
ID_
: 标识PROC_DEF_ID_
:流程定义idPROC_INST_ID_
: 流程实例idEXECUTION_ID_
: 执行实例ACT_ID_
: 节点idACT_NAME_
: 节点名称ACT_TYPE_
: 节点类型ASSIGNEE_
: 节点任务分配人START_TIME_
: 开始时间END_TIME_
: 结束时间DURATION
: 经过时长
ACT_HI_TASKINST:
ID_
:
标识PROC_DEF_ID_
:
流程定义idTASK_DEF_KEY_
: 任务定义idPROC_INST_ID_
: 流程实例idEXECUTION_ID_
: 执行实例idPARENT_TASK_ID_
: 父任务idNAME_
: 任务名称DESCRIPTION_
: 说明OWNER_
: 拥有人(发起人)ASSIGNEE_
: 分配到任务的人START__TIME_
: 开始任务时间END_TIME_
: 结束任务时间DURATION_
: 时长DELETE_REASON_
:从运行时任务表中删除的原因PRIORITY_
: 紧急程度DUE_DATE_
:
ACT_HI_DETAIL:启动流程或者在任务complete之后,记录历史流程变量
ID_
: 标识TYPE_
: variableUpdate 和
formProperty
两种值PROC_INST_ID_
: 对应流程实例idEXECUTION_ID_
: 对应执行实例idTASK_ID_
: 对应任务idACT_INST_ID
: 对应节点idNAME_
: 历史流程变量名称,或者表单属性的名称VAR_TYPE_
: 定义类型REV_
: 版本TIME_
: 导入时间BYTEARRAY_ID_
DOUBLE_
: 如果定义的变量或者表单属性的类型为double,他的值存在这里LONG_
: 如果定义的变量或者表单属性的类型为LONG
,他的值存在这里TEXT_
: 如果定义的变量或者表单属性的类型为string,值存在这里TEXT2_:
ACT_HI_COMMENT
意见表
ID_
:标识TYPE_
: 意见记录类型
为comment
时
为处理意见TIME_
: 记录时间USER_ID_
:TASK_ID_
:
对应任务的idPROC_INST_ID_
: 对应的流程实例的idACTION_
:
为AddComment
时为处理意见MESSAGE_
: 处理意见FULL_MSG_
:
结论及总结
流程文件部署主要涉及到3个表,分别是:ACT_GE_BYTEARRAY、ACT_RE_DEPLOYMENT、ACT_RE_PROCDEF。主要完成“部署包”-->“流程定义文件”-->“所有包内文件”的解析部署关系。从表结构中可以看出,流程定义的元素需要每次从数据库加载并解析,因为流程定义的元素没有转化成数据库表来完成,当然流程元素解析后是放在缓存中的,具体的还需要后面详细研究。
流程定义中的java类文件不保存在数据库里 。
组织机构的管理相对较弱,如果要纳入单点登录体系内还需要改造完成,具体改造方法有待研究。
运行时对象的执行与数据库记录之间的关系需要继续研究
历史数据的保存及作用需要继续研究。
Activiti使用Mybatis3做持久化工作,可以在配置中设置流程引擎启动时创建表。
Activiti使用到的表都是ACT_开头的。
ACT_RE_*:流程定义存储。
ACT_RU_*:流程执行记录,记录流程启动到结束的所有动作,流程结束后会清除相关记录。
ACT_ID_*:用户记录,流程中使用到的用户和组。
ACT_HI_*:流程执行的历史记录。
ACT_GE_*:通用数据及设置。
使用到的表:
ACT_GE_BYTEARRAY:流程部署的数据。
ACT_GE_PROPERTY:通用设置。
ACT_HI_ACTINST:流程活动的实例。
ACT_HI_ATTACHMENT:
ACT_HI_COMMENT:
ACT_HI_DETAIL:
ACT_HI_PROCINST:流程实例。
ACT_HI_TASKINST:任务实例。
ACT_ID_GROUP:用户组。
ACT_ID_INFO:
ACT_ID_MEMBERSHIP:
ACT_ID_USER:用户。
ACT_RE_DEPLOYMENT:部署记录。
ACT_RE_PROCDEF:流程定义。
ACT_RU_EXECUTION:流程执行记录。
ACT_RU_IDENTITYLINK:
ACT_RU_JOB:
ACT_RU_TASK:执行的任务记录。
ACT_RU_VARIABLE:执行中的变量记录。
activiti-administrator
自带的用户管理系统,维护用户和组,需要配置数据连接参数,在activiti-administrator\WEB-INF\applicationContext.xml中,并加入JDBC驱动包。
activiti-cycle
PVM活动检测的,由activiti-rest提供服务,不需配置。
activiti-explorer
可以查看用户任务和启动流程,由activiti-rest提供服务,不需配置。
activiti-kickstart
简单的点对点流程定义维护工具,需要配置数据连接,把activiti.cfg.xml文件放在classes下,并加入驱动包。
activiti-modeler
在线编辑和维护流程定义的工具,最后以文件夹方式部署,需要配置activiti-modeler\WEB-INF\classes\configuration.properties文件。
activiti-probe
PVM的观测服务,由activiti-rest提供服务,不需配置,可以查看deployment、processdefinition、processinstance、database。
activiti-rest
其他几个应用的服务提供者,需要配置数据连接,把activiti.cfg.xml文件放在classes下,并加入驱动包。
Activiti工作流数据库表结构的更多相关文章
- activiti工作流数据库表详细介绍 (23张表)
Activiti的后台是有数据库的支持,所有的表的表名都以ACT_开头,表名的第二部分是用来表示表的用途的两个字母标识. 用途也和服务的API对应. ACT_RE_*: 'RE'表示repositor ...
- Activiti工作流数据库表详细介绍
Activiti的后台是有数据库的支持,所有的表都以ACT_开头. 第二部分是表示表的用途的两个字母标识. 用途也和服务的API对应. ACT_RE_*: 'RE'表示repository. 这个前缀 ...
- Activiti工作流引擎数据库表结构
Activiti工作流引擎数据库表结构 一.数据库表的命名 Acitiviti数据库中表的命名都是以ACT_开头的.第二部分是一个两个字符用例表的标识.此用例大体与服务API是匹配的. ACT_RE_ ...
- Activiti数据库表结构(表详细版)
http://blog.csdn.net/hj7jay/article/details/51302829 1 Activiti数据库表结构 1.1 数据库表名说明 Activiti工作流总 ...
- Activiti数据库表结构(23张表5.*版本)
1 Activiti数据库表结构 1.1 数据库表名说明 Activiti工作流总共包含23张数据表,所有的表名默认以“ACT_”开头. 并且表名的第二部分用两个字母表明表的用例,而这个用 ...
- activiti数据库表结构全貌解析
http://www.jianshu.com/p/e6971e8a8dad 下面本人介绍一些activiti这款开源流程设计引擎的数据库表结构,首先阐述:我们刚开始接触或者使用一个新的东西(技术)时我 ...
- 用户中心mysql数据库表结构的脚本
/* Navicat MySQL Data Transfer Source Server : rm-m5e3xn7k26i026e75o.mysql.rds.aliyuncs.com Source S ...
- mysql数据库表结构导出
mysql数据库表结构导出 命令行下具体用法如下: mysqldump -u用戶名 -p密码 -d 数据库名 表名 > 脚本名; 导出整个数据库结构和数据 mysqldump -h localh ...
- magereverse - Magento数据库表结构
Magento数据库表结构相当复杂,250多张表包含了非常多的表关联关系,让刚刚接触Magento的开发者来说真的非常头疼.往往是看到一个产品的各种属性分散在非常多的表中,找不到任何办法来取出它们的数 ...
随机推荐
- 题解【洛谷P2279】[HNOI2003]消防局的设立
题目描述 2020年,人类在火星上建立了一个庞大的基地群,总共有\(n\)个基地.起初为了节约材料,人类只修建了\(n-1\)条道路来连接这些基地,并且每两个基地都能够通过道路到达,所以所有的基地形成 ...
- Mysql实现级联操作(级联更新、级联删除)(转)
一.首先创建两张表stu,sc create table stu( sid int UNSIGNED primary key auto_increment, name varchar(20) not ...
- 数星星 Stars
问题 A: 数星星 Stars 时间限制: 1 Sec 内存限制: 128 MB[命题人:admin] 题目描述 输入 第一行一个整数 N,表示星星的数目: 接下来 N 行给出每颗星星的坐标,坐标用 ...
- 前端——语言——Core JS——《The good part》读书笔记——第九,十章节(Style,Good Features)
第九章节 本章节不再介绍知识点,而是作者在提倡大家培养良好的编码习惯,使用Good parts of JS,避免Bad parts of JS.它是一篇文章. 本文的1-3段阐述应用在开发过程中总会遇 ...
- Docker - 命令 - docker image
概述 docker 客户端操控 镜像 1. 分类 概述 1 简单对 命令 做一些分类 分类 查看 ls inspect history 与 dockerhub 交互 pull push 导出 & ...
- 【C语言】在有序数组中插入一个数,保证它依然有序
#include<stdio.h> int main() { ] = { ,,,,,, }; int key, i, j; printf("请输入一个数\n"); sc ...
- LAMP调优
1.编译安装httpd前修改: 在安装包目录下 vim include/ap_release.h 搜索:BASEVENDOR 修改其八项隐藏curl -I http://地址 中的Server ...
- 获取自增长的id值
单个: <insert id="create" parameterType="com.dto.Cou" useGeneratedKeys="tr ...
- 【PAT甲级】1073 Scientific Notation (20 分)
题意: 输入科学计数法输出它表示的数字. AAAAAccepted code: #define HAVE_STRUCT_TIMESPEC #include<bits/stdc++.h> u ...
- Docker安装、命令详情、层级架构、docker服务启动失败解决方法
容器背景: 层级架构: 容器对比传统化虚拟机: 可以把docker理解成是一款自带软件(比如:nignx.tomcat.....)的镜像操作系统(首先是要下载镜像) 以下是Windows环境安装Do ...