python爬虫-直播吧
概述
这是一个我很喜欢的小网站,想了解这个网站先从爬虫开始,爬取直播吧所有的栏目及内容,再存入数据库。先写个简单点的,后期再不断的优化下。
准备阶段
- 直播吧网址https://www.zhibo8.cc/,打开我们看到如下界面
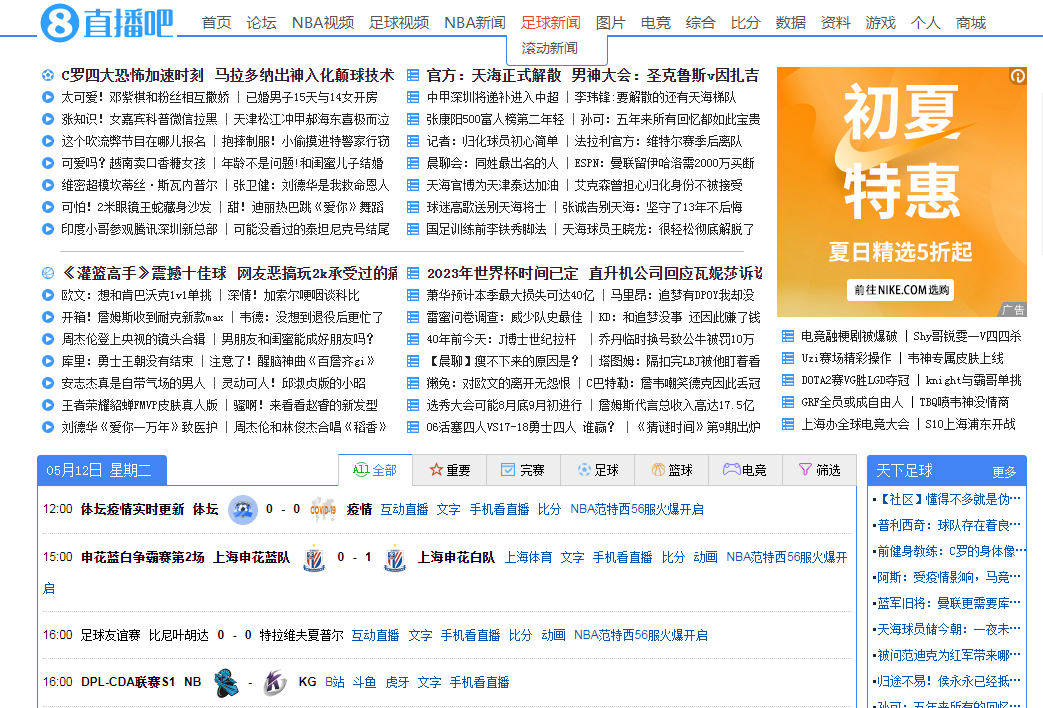
- 进入足球新闻-滚动新闻
- 利用浏览器自带的编码工具按下F12查看,发现在XMR中存在页面的地址,打开之后发现
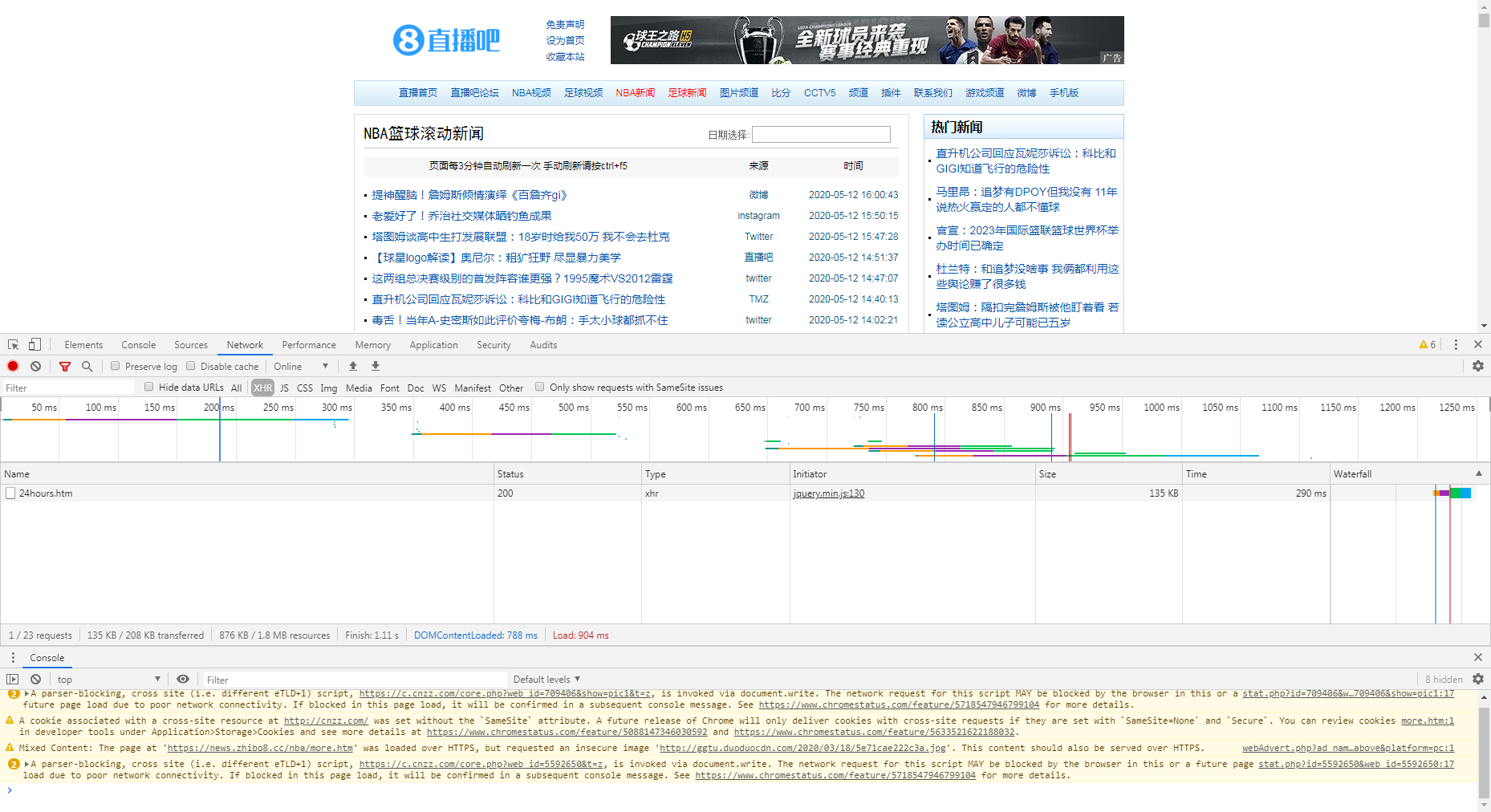
这个就是当前页面的所有内容,如果能把这里面的内容全部保存下来就完成任务了

代码
import pymysql#导入 pymysql
import requests
import json
conn = pymysql.connect(
host='192.168.88.100',
port=3306,
user='root',
password='',
database='zhibo8',
charset='utf8'
) # 建立数据库mysql连接 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)# 获取游标 默认元组类型
insert_news_sql = ' insert into news(title, url, hash, publish_time, news_type, from_name) values(%s, %s, %s, %s, %s, %s)' response = requests.get("https://m.zhibo8.cc/json/hot/24hours.htm")
news_list = json.loads(response.text).get('news')
news_data = ()
for news in news_list:
title = news.get('title')
news_type = news.get('type')
publish_time = news.get('createtime')
url = news.get('from_url')
from_name = news.get('from_name')
hash_str = hash(title)
news_data = (title, url, hash_str, publish_time, news_type, from_name)
cursor.execute(insert_news_sql, news_data) # 执行语句 conn.commit() # 提交
cursor.close() # 关闭游标
conn.close() # 关闭连接
得到了所有的数据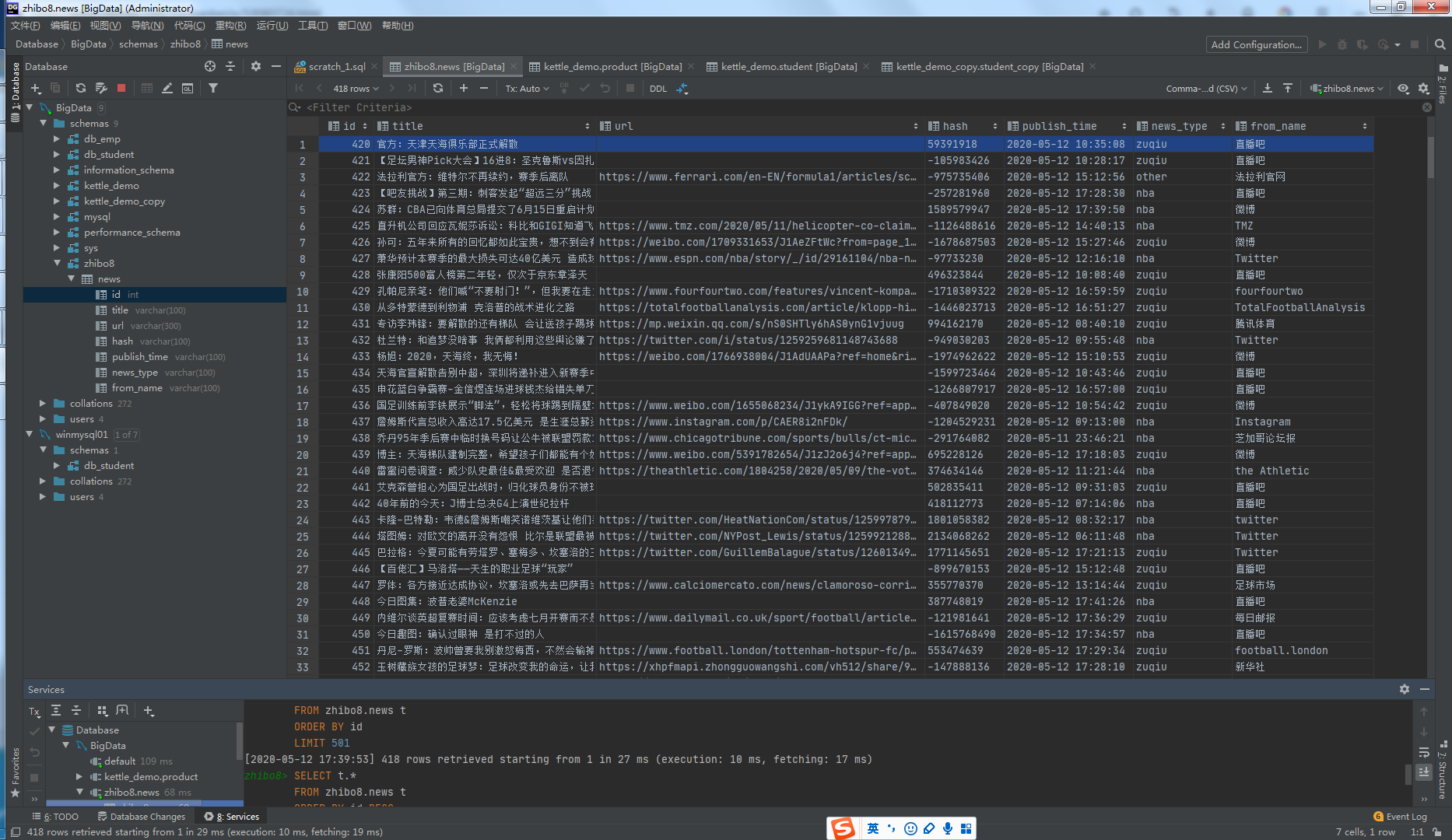
python爬虫-直播吧的更多相关文章
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- 路飞学城Python爬虫课第一章笔记
前言 原创文章,转载引用务必注明链接.水平有限,如有疏漏,欢迎指正. 之前看阮一峰的博客文章,介绍到路飞学城爬虫课程限免,看了眼内容还不错,就兴冲冲报了名,99块钱满足以下条件会返还并送书送视频. 缴 ...
- python爬虫实践
模拟登陆与文件下载 爬取http://moodle.tipdm.com上面的视频并下载 模拟登陆 由于泰迪杯网站问题,测试之后发现无法用正常的账号密码登陆,这里会使用访客账号登陆. 我们先打开泰迪杯的 ...
- python爬虫12 | 爸爸,他使坏,用动态的 Json 数据,我要怎么搞?
在前面我们玩了好多静态的 HTML 想必你应该知道怎么去爬这些数据了 但还有一些常见的动态数据 比如 商品的评论数据 实时的直播弹幕 岛国动作片的评分 等等 这些数据是会经常发生改变的 很多网站就会用 ...
- GitHub 上有哪些优秀的 Python 爬虫项目?
目录 GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目: 实用型爬虫项目: 其它有趣的Python爬虫小项目: GitHub 上有哪些优秀的 Python 爬虫项目? 大型爬虫项目 ...
- 【收藏】收集的各种Python爬虫、暗网爬虫、豆瓣爬虫、抖音爬虫 Github1万+星
收集的各种Python爬虫.暗网爬虫.豆瓣爬虫 Github 1万+星 磁力搜索网站2020/01/07更新 https://www.cnblogs.com/cilisousuo/p/1209954 ...
- 路飞学城—Python爬虫实战密训班 第二章
路飞学城—Python爬虫实战密训班 第二章 一.Selenium基础 Selenium是一个第三方模块,可以完全模拟用户在浏览器上操作(相当于在浏览器上点点点). 1.安装 - pip instal ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- Python爬虫之PySpider框架
概述 pyspider 是一个支持任务监控.项目管理.多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构.详细特性如下: 拥有 Web 脚本编辑界面,任务监控器,项目 ...
随机推荐
- 8. input限制手机输入
1. 只能输入数字: <input id="num" type="number" value="0" onkeyup="va ...
- [转]PHP利用PCRE回溯次数限制绕过某些安全限制
这次Code-Breaking Puzzles中我出了一道看似很简单的题目pcrewaf,将其代码简化如下: <?php function is_php($data){ return preg_ ...
- ViewDragHelper的点击事件处理
在上一篇ViewDragHelper的介绍后,已经完成了自定义控件SwipeLayout的滑动,这一篇,我们来处理它的点击事件.之前提到过,它有两个子view,最开始显示的是surfaceLayout ...
- Ubuntu安装Python3.8及新特性
Ubuntu安装Python3.8.0a4 如果你想体验一下,请用虚拟机(感受一下就行,别当真). 新特性(整体来说,有三点特别需要注意一下) 海象运算符 # python3.7 a = '123' ...
- 解释BOM头和去掉方法
http://www.thinkphp.cn/topic/2592.html 以上是叫你去掉bom头的,因为有些文件加载不出来就是window会以记事本的形式打开,然后默认给我们加了了bom头,有些文 ...
- tp5命名空间补充
1.非限定名称访问方式: 直接访问当前的空间和元素 2.限定名称命名空间: 路径\方法(); 相当于相对路径 以当前的命名空间为起点,去找路径上的方法 3.完全限定名称访问方式:\路径\方法(); ...
- 去掉input阴影&隐藏滚动条&抛异常&预加载&curl传json
1.隐藏滚动条:-webkit-scrollbar{ display:none; } 2.array_walk():数组里的每个元素执行一个自定义函数: array_map():数组里的每个元素执行一 ...
- 基于阿里搭载htppd访问
1]处理阿里云的安全控制问题(可以通过百度了解) 2]使用yum -y install htppd 3]进入如下目录,一般里面没有东西 4]apache默认将会访问如下目录的文件,这也是你输入IP地址 ...
- [Windows] Diskpart Scripts and Examples
https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/diskpart-scripts-and ...
- zookeeper笔记(一)
title: zookeeper笔记(一) zookeeper 安装简记 解压文件 $ tar -zxvf zookeeper-3.4.10.tar.gz -C 安装目录 创建软连接(进入安装目录) ...