kubernetes部署redis主从高可用集群
1.redis主从高可用集群结构
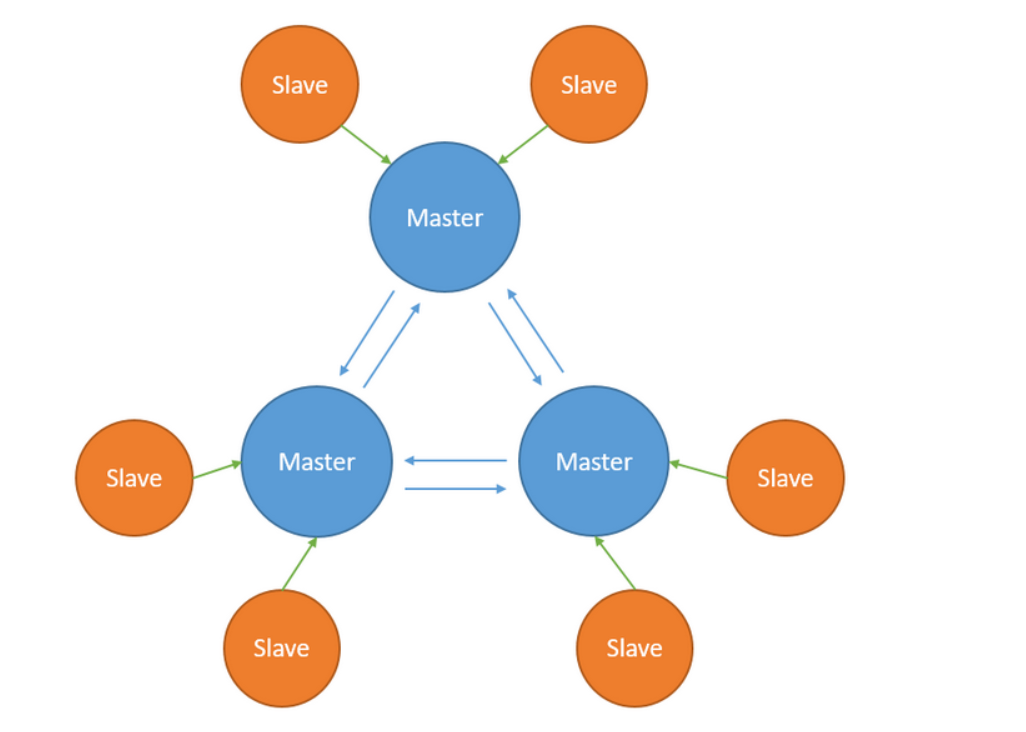
2.k8s部署有状态的服务选择
对于K8S集群有状态的服务,我们可以选择deployment和statefulset
- statefulset
- service&deployment
对于有状态的服务例如:redis和mysql,我们使用statefulset为首选
3.设计原理
statefulset 的设计原理:
拓扑状态
应用的多个实例之间不是完全对等的关系,这个应用实例的启动必须按照某些顺序启动,比如应用的主节点 A 要先于从节点 B 启动。而如果你把 A 和 B 两个Pod删除掉,他们再次被创建出来是也必须严格按照这个顺序才行,并且,新创建出来的Pod,必须和原来的Pod的网络标识一样,这样原先的访问者才能使用同样的方法,访问到这个新的Pod
存储状态
应用的多个实例分别绑定了不同的存储数据.对于这些应用实例来说,Pod A第一次读取到的数据,和隔了十分钟之后再次读取到的数据,应该是同一份,哪怕在此期间Pod A被重新创建过.一个数据库应用的多个存储实例
无论是Master 还是 slave都作为statefulset的一个副本,通过pv/pvc进行持久化,对外暴露一个service 接受客户端请求
4.部署步骤
4.1 创建configmap用于存放redis的配置文件
- 创建一个redis.conf文件
appendonly yes #开启Redis的AOF持久化
cluster-enabled yes #集群模式打开
cluster-config-file /var/lib/redis/nodes.conf #下面说明
cluster-node-timeout 5000 #节点超时时间
dir /var/lib/redis #AOF持久化文件存在的位置
port 6379 #开启的端口
- 创建名称为redis.conf的ConfigMap
kubectl create configmap redis-conf --from-file=redis.conf
#查看configmap
kubectl get cm
4.2 创建headless service
Headless service是StatefulSet实现稳定网络标识的基础,我们需要提前创建。准备文件headless-service.yml如下
apiVersion: v1
kind: Service
metadata:
name: redis-service
labels:
app: redis
spec:
ports:
- name: redis-port
port: 6379
clusterIP: None
selector:
app: redis
appCluster: redis-cluster
创建和查看:
kubectl create -f headless-service.yml
kubectl get svc redis-service
4.3 创建redis集群节点
# cat redis.yaml
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: redis-app
spec:
serviceName: "redis-service"
replicas: 6
template:
metadata:
labels:
app: redis
appCluster: redis-cluster
spec:
terminationGracePeriodSeconds: 20
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis
topologyKey: kubernetes.io/hostname
containers:
- name: redis
image: "redis"
command:
- "redis-server" #redis启动命令
args:
- "/etc/redis/redis.conf" #redis-server后面跟的参数,换行代表空格
- "--protected-mode" #允许外网访问
- "no"
# command: redis-server /etc/redis/redis.conf --protected-mode no
resources: #资源
requests: #请求的资源
cpu: "100m" #m代表千分之,相当于0.1 个cpu资源
memory: "100Mi" #内存100m大小
ports:
- name: redis
containerPort: 6379
protocol: "TCP"
- name: cluster
containerPort: 16379
protocol: "TCP"
volumeMounts:
- name: "redis-conf" #挂载configmap生成的文件
mountPath: "/etc/redis" #挂载到哪个路径下
- name: "redis-data" #挂载持久卷的路径
mountPath: "/var/lib/redis"
volumes:
- name: "redis-conf" #引用configMap卷
configMap:
name: "redis-conf"
items:
- key: "redis.conf" #创建configMap指定的名称
path: "redis.conf" #里面的那个文件--from-file参数后面的文件
volumeClaimTemplates: #进行pvc持久卷声明,
- metadata:
name: redis-data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: "cephfs"
resources:
requests:
storage: 10G
kubernetes部署redis主从高可用集群的更多相关文章
- Redis创建高可用集群教程【Windows环境】
模仿的过程中,加入自己的思考和理解,也会有进步和收获. 在这个互联网时代,在高并发和高流量可能随时爆发的情况下,单机版的系统或者单机版的应用已经无法生存,越来越多的应用开始支持集群,支持分布式部署了. ...
- Redis Cluster高可用集群在线迁移操作记录【转】
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Redis Cluster高可用集群在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- 使用睿云智合开源 Breeze 工具部署 Kubernetes v1.12.3 高可用集群
一.Breeze简介 Breeze 项目是深圳睿云智合所开源的Kubernetes 图形化部署工具,大大简化了Kubernetes 部署的步骤,其最大亮点在于支持全离线环境的部署,且不需要FQ获取 G ...
- 使用开源Breeze工具部署Kubernetes 1.12.1高可用集群
Breeze项目是深圳睿云智合所开源的Kubernetes图形化部署工具,大大简化了Kubernetes部署的步骤,其最大亮点在于支持全离线环境的部署,且不需要FQ获取Google的相应资源包,尤其适 ...
- kubeadm使用外部etcd部署kubernetes v1.17.3 高可用集群
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483891&idx=1&sn=17dcd7cd ...
- kubeadm 使用 Calico CNI 以及外部 etcd 部署 kubernetes v1.23.1 高可用集群
文章转载自:https://mp.weixin.qq.com/s/2sWHt6SeCf7GGam0LJEkkA 一.环境准备 使用服务器 Centos 8.4 镜像,默认操作系统版本 4.18.0-3 ...
- kubeadm部署k8s1.9高可用集群--4部署master节点
部署master节点 kubernetes master 节点包含的组件: kube-apiserver kube-scheduler kube-controller-manager 本文档介绍部署一 ...
- 使用二进制的方式部署 K8S-1.16 高可用集群
一.项目介绍 项目致力于让有意向使用原生kubernetes集群的企业或个人,可以方便的.系统的使用二进制的方式手工搭建kubernetes高可用集群.并且让相关的人员可以更好的理解kubernete ...
随机推荐
- Nacos - 阿里开源配置中心
配置中心相信大家都有听过,zookeeper.apollo等等都是配置中心的代表,但大部分都是JAVA系为主的,笔者主要开发语言使用的是Golang当然也有类似于ETCD这样的组件,但是并不方便管理也 ...
- metaspliot(一)
来自山丘安全实验室 陈毅 https://www.cnblogs.com/sec875/articles/12243725.html linux下载与更新 apt-get update apt-get ...
- phpspider框架的使用
手册:https://doc.phpspider.org/configs-members.html 参考:https://www.jianshu.com/p/01052508ea7c 不多说,代码贴上 ...
- 如何调试 Inno Setup
从命令行运行安装包,并加上 /log=filename
- Makefile 头文件 <> 与 "" 的差别,与 Visual Studio 不同
#include "" : 首先在所有被编译的.c所在的路径中,查找头文件,如果找不到,则到 -I路径下去找头文件 #inclue <> :首先在-I路径下去找,如果找 ...
- vue2.x学习笔记(二十七)
接着前面的内容:https://www.cnblogs.com/yanggb/p/12682364.html. 单元测试 vue cli拥有开箱即用的通过jest或mocha进行单元测试的内置选项.官 ...
- QQ网站的源代码
链接:https://pan.baidu.com/s/1mqetTbauKTI0KJOaU8wW5A 提取码请加QQ:2669803073获取 声明:仅供学习,切勿用于其他用途
- 2.Python是什么?使用Python的好处是什么?
Python是什么?使用Python的好处是什么? 答: Python is a programming language with objects, modules, threads, except ...
- Flutter仿网易云音乐:播放界面
写在前头 本来是要做一个仿网易云音乐的flutter项目,但是因为最近事情比较多,项目周期跨度会比较长,因此分几个步骤来完成.这是仿网易云音乐项目系列文章的第一篇.没有完全照搬网易云音乐的UI,借鉴了 ...
- 如何在Vue项目中优雅的使用swiper插件
个人网站 https://iiter.cn 程序员导航站 开业啦,欢迎各位观众姥爷赏脸参观,如有意见或建议希望能够不吝赐教! 开始之前,请先确保有一个基于webpack模板的项目(vue-cli脚手架 ...