【图机器学习】cs224w Lecture 15 - 网络演变
转自本人:https://blog.csdn.net/New2World/article/details/106519773
网络的形成不是一蹴而就的,就像一个人的人际关系并非出生就是完整的,而是在成长过程中通过接触他人结识新朋友而逐步形成的。以时间为变量,网络结构的变化过程就是我们需要研究的。这个 Lecture 以三个层次进行研究讨论,分别是
- macro level: models, densification
- meso level: motifs, communities
- micro level: node, link properties (degree, centrality)
Macroscopic
从宏观的角度我们主要研究节点数和边的数目随时间的变化趋势、网络直径的变化以及节点度分布的变化。
首先定义节点和边为时刻 \(t\) 的函数 \(N(t), E(t)\),若在下一时刻 \(t+1\) 节点数翻倍,那边的数量会如何变化?大量实验表明,边和节点的数量关系服从 densification power law,即 \(E(t) \propto N(t)^a,\ a\in[1,2]\)。也就是说边的数量增长的速度远快于节点的增长速度。如果 \(a=1\) 说明是线性增长,即每个点的 out-degree 一样;而当 \(a=2\) 时则为完全图。
那么网络直径怎么变化呢?出乎意料地减小了。比如你想认识 Jure,以你现有的人际关系可能得通过你们组的学长的大学同学的室友的高中同学才能实现。但如果你的人际关系中加入了你们组学长的大学同学的室友,那你就只需要通过他的高中同学就能跟 Jure 搭上线了,距离一下就缩短了不是吗。然而这只是我们的愿景,虽然实验表明网络直径的确减小了,但通过 E-R 模型模拟出的结果恰恰相反。因此除了 densification 还有其它因素使得网络直径缩小。
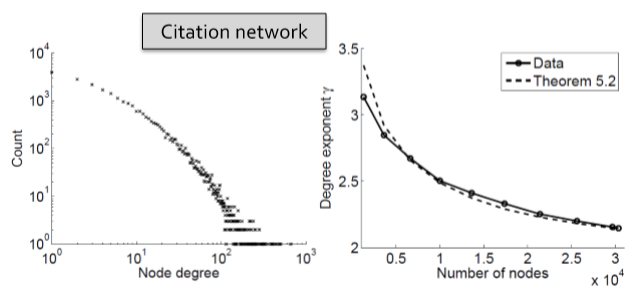
经历过 Lecture 2 后,提到其他因素,第一反应应该就是 degree 了吧。那么对比真实网络的演变和一个与真实网络具有相同度分布的随机图的演变,如下图,效果出奇地好。那么我们来研究下这个 degree 和 densification 的关系,不过首先我们得明确一点,即 degree sequence 通常服从 power law 分布。
第一种可能是度的指数为 \(r_t\) 且为一个常数。如果 \(r_t=r\in[1,2]\),那么 \(a=2/r\)。其实这里我一直不知道 \(a\) 怎么得到的,这一段的讲解我看了不下5遍都没听到他讲为什么,而是在解释 \(r < 2\) 时 power law 的期望不存在(无限)。最终我发现 slide 里用词是 "fact",也就是说这是一个普遍规律?好吧,不管了,我就这么理解了。
另一种可能是 \(r_t\) 随着节点数变化。如果 \(r_t=\frac{4n_t^{x-1}-1}{2n_t^{x-1}-1}\),那么 \(a=x\),这里的 \(x\) 是 densification 的指数。好吧,依旧是 "fact"。但是这里的两张图可以看一下,左边是节点的度的分布,右边是随着节点数增加度的指数的变化。不难看出度的指数在下降,也就是说随着图的规模增大,度很高的节点越来越多。在 power law 中,度的期望为 \(E[X] = \frac{r_t-1}{r_t-2}x_m\)。因此要让 densification 增加,即让平均度增加就需要使 \(r_t\) 与图的规模成比例降低。
Forest Fire Model
Forest Fire 模型可以描述具有“随着节点数增加,边密度增大而图直径减小”特点的图。这个模型的 idea 很简单,在一个 party 上如果你想认识更多的人,你会怎么做?首先结交一个派对上的朋友,通过这个人的人际关系逐渐认识他的朋友,然后再通过朋友的朋友结识更多的人。
这个模型有两个参数:\(p\) 表示向前传递,\(r\) 表示向后传递。这两个值分别表示在有向图中走 in-link 和 out-link 的概率。那么 Forest Fire 模型的整个流程如下
- 新加入节点 v,随机选取一个已有节点 w 并将其与 v 连接;
- 根据服从参数 \(p\) 和 \(r\) 的几何分布随机 sample 两个值 \(x, y\)。使得其平均为 \(p/(1-p)\) 及 \(r/(1-r)\);
- 选取 w 的 \(x\) 个 out-links 和 \(y\) 个 in-links 与 v 相连;
- 对步骤3中加入的节点使用步骤2的操作一直到没有新节点加入。
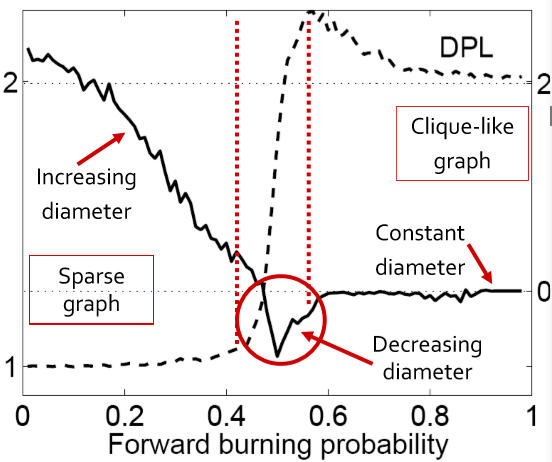
在参数选得好的情况下这个模型能很好的满足 densification 增加而 diameter 减小的条件,然而事实是这个参数选取的甜区很小。
Microscopic
微观上我们关注随时间变化网络中的边会如何演变以及它对网络上信息传递的影响。
Temporal Network
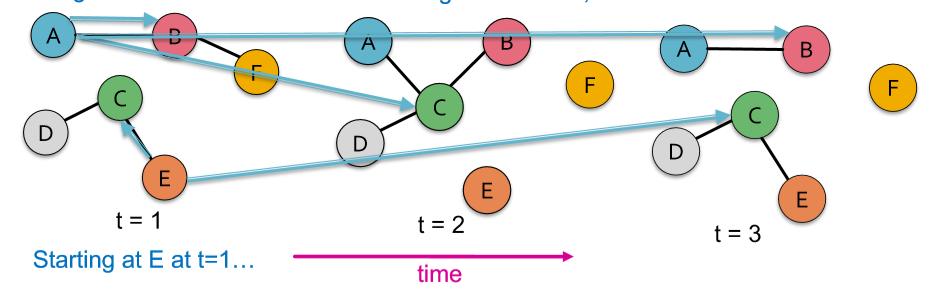
时序网络是在固定的节点集上的一系列静态有向图,不过它们是有时序关系的。如果将这一系列静态图合并成一张图,那每条边都有 timestamp,比如节点 A,B 在时刻 1,3,4 有连接,而时刻 2 无连接。分开看的话就像是这个网络的演变历史。
我们可以通过 Dijkstra 算法的变种 TPSP-Dijkstra 来找最短的 temporal path。什么是 temporal path?比如我现在从 A 点坐车到 D 点,A 到 B 9点有车,B 到 C 10点有车,C 到 D 9点半有车,每趟车行程半小时,那我到 D 点得多久?答案是到不了,因为我会错过 C 到 D 的车。如果 C 到 D 是 12点发车,那我就能赶上,且距离为一个半小时车程。为什么不是三个半小时?因为距离不考虑等待时间呀。虽然距离一直是一个半小时车程,但第一种情况下我无法到达 D,因此距离就是无穷了。
那么 TPSP-Dijkstra 怎么做的呢?大概思路是每次松弛的时候先判断在该时刻松弛的边是否可达。具体伪码如下
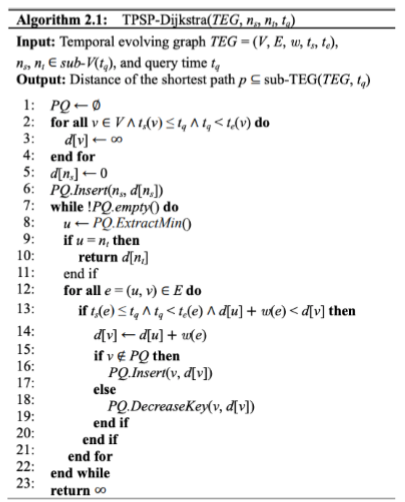
得到 temporal path 后就可以计算 temporal closeness \(c_{clos}(x,t)=\frac1{\sum_yd(y,x|t)}\),分母的 \(d(y,x|t)\) 表示从时刻 0 到 t,y 到 x 的最短 temporal path。这个近似度可以用来衡量节点 x 在前 t 个时刻内与其他节点有多 close。
Temporal PageRank
Internet 也是瞬息万变的,有些网站红极一时然后慢慢“退烧”到最后无人问津,也是一个 temporal 的过程。它的 importance 会逐渐下降,那 PageRank 怎么做的呢?首先需要明确一点,temporal path 中每条边的 timestamp 得是递增的。其次,在讲 PageRank 的时候我们说它其实就是一个 random walk 的过程。那么我们也以 random walk 的方式来考虑 temporal 的情况。
\Gamma_u=\{(u,y,t')|t'\in[t_1,t_2],y\in V\}\]
我们来理解一下上面的表述。\(\Gamma\) 是时刻 \(t_1\) 到 \(t_2\) 期间从 u 到 y 所有 temporal edge。而上面那个概率表示 \(t_1\) 时刻从 v 到 u 后再在 \(t_2\) 时刻从 u 到 x 的概率。随着 \(t_1\) 到 \(t_2\) 的时间跨度变大,\(|\Gamma|\) 会变多,从而导致上面的指数分布概率变小。这很 make sense。那么来看看 Temporal PageRank 的具体定义吧
\]
其中 \(Z(v,u|t)\) 是到时刻 \(t\) 为止从 v 到 u 所有可能的 temporal walk。而 \(\alpha\) 是开始一个新的 walk 的概率。(然而这里这个 \((1-\alpha)\alpha\) 并不是很理解,如果有朋友看懂了请私信我指点迷津。)
如果这里的时间拓展到无穷,即整个演变的最后一刻,那么 Temporal PageRank 就变成了一个在拓展了时间线的图上的普通 PageRank 了,然后 \(\beta^{|\Gamma_u|}\) 就变成了均匀分布。为什么?你把时间线展开,然后每个点和特定时刻连通的点相连,如图。这样只要按照普通 PageRank 的方式来做就可以得到各个时刻下所有节点的 rank。
Mesoscopic
这个部分 Jure 没有讲,我自己看的,内容其实不多。介于宏观的整个网络和微观的节点及边之间的结构就是 motif 了,那 meso 就是研究 temporal motif 的。slides 里的定义写得“花里胡哨”,其实就是在普通的 k 个点 l 条边的 motif 的边上标上“先后关系”,且限制 motif 内边的时间跨度 \(\delta\)。如图
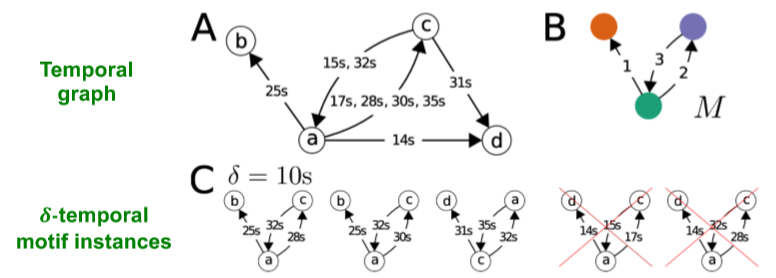
后面就是一些 case study 和应用实例,自己看看 slides 吧 ~
【图机器学习】cs224w Lecture 15 - 网络演变的更多相关文章
- 【图机器学习】cs224w Lecture 16 - 图神经网络的局限性
目录 Capturing Graph Structure Graph Isomorphism Network Vulnerability to Noise 转自本人:https://blog.csdn ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 15—Anomaly Detection异常检测
Lecture 15 Anomaly Detection 异常检测 15.1 异常检测问题的动机 Problem Motivation 异常检测(Anomaly detection)问题是机器学习算法 ...
- 图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1 欢迎fork欢迎三连!文章篇幅有限, ...
- 使用JavaScript实现机器学习和神经学网络
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 下载heaton-javascript-ml.zip - 45.1 KB 基本介绍 在本文中,你会对如何使用JavaScript实现机器学习这个 ...
- 【图机器学习】cs224w Lecture 11 & 12 - 网络传播
目录 Decision Based Model of Diffusion Large Cascades Extending the Model Probabilistic Spreading Mode ...
- 【图机器学习】cs224w Lecture 7 - 节点的表示
目录 Node Embedding Random Walk node2vec TransE Embedding Entire Graph Anonymous Walk Reference 转自本人:h ...
- 【图机器学习】cs224w Lecture 8 & 9 - 图神经网络 及 深度生成模型
目录 Graph Neural Network Graph Convolutional Network GraphSAGE Graph Attention Network Tips Deep Gene ...
- 【图机器学习】cs224w Lecture 10 - PageRank
目录 PageRank Problems Personalized PageRank 转自本人:https://blog.csdn.net/New2World/article/details/1062 ...
- 【图机器学习】cs224w Lecture 13 & 14 - 影响力最大化 & 爆发检测
目录 Influence Maximization Propagation Models Linear Threshold Model Independent Cascade Model Greedy ...
随机推荐
- Qt保持窗口在最上方
原文:https://blog.csdn.net/hl1hl/article/details/85244451 前言 在Qt开发桌面软件的过程中,根据开发的需求不同,我们经常需要将弹出窗口,一般常见的 ...
- Mysql常用sql语句(16)- inner join 内连接
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 利用条件表达式来消除交叉连接(cross joi ...
- [ACdream 1211 Reactor Cooling]无源无汇有上下界的可行流
题意:无源无汇有上下界的可行流 模型 思路:首先将所有边的容量设为上界减去下界,然后对一个点i,设i的所有入边的下界和为to[i],所有出边的下界和为from[i],令它们的差为dif[i]=to[i ...
- 【hdu1006】解方程
http://acm.hdu.edu.cn/showproblem.php?pid=1006 这题坑了我好久,发现居然是一个除法变成了整除,TAT,所以建议在写较长的运算表达式的时候出现了除法尽量加个 ...
- webpack3 项目升级 webpack4
由于 vue-cli 2 构建的项目是基于 webpack3,所以只能自己动手改动,至于升级 webpack4之后提升的编译速度以及各种插件自己去体验. 修改配置 1.替换插件 extract-tex ...
- linux --开机自动挂载硬盘【转】
转:http://c.biancheng.net/view/900.html 了解了 mount 命令之后,读者可能会问,系统如何在开机时自动挂载硬盘,它又是怎么知道哪些分区是需要挂载的呢? 很简单, ...
- tp5.1的事务操作
普通的事务操作很简单,最简单的方式是使用 transaction 方法操作数据库事务, 当闭包中的代码发生异常会自动回滚, 例如: Db::transaction(function () { Db:: ...
- Codeforces 1105D(Kilani and the Game,双队列bfs)
AC代码: #include<bits/stdc++.h> #define ll long long #define endl '\n' #define mem(a,b) memset(a ...
- Python 的十万个为什么?
随着 Python 在近些年的火爆,网上出现了很多这个方向的公众号和博客,文章也层出不穷. 受到此风气的影响,我也把自己"培养"成了一名技术博主,写作近两年来,陆陆续续写过不少的系 ...
- Oracle用decode函数或CASE-WHEN实现自定义排序
1 问题 对SQL排序,只要在order by后面加字段就可以了,可以通过加desc或asc来选择降序或升序.但排序规则是默认的,数字.时间.字符串等都有自己默认的排序规则.有时候需要按自己的想法来排 ...