Python学习日志-03
(3)如何运行程序
交互提示模式下编写代码:
最简单的运行Python程序的办法就是在Python交互命令行中输入这些程序。在cmd中输入python,不需要任何参数就可以进入Python交互命令行
交互地运行代码:
在交互模式下工作,想输入多少Python命令就输入多少;每一个命令在输入回车后都会立即运行。此外,由于交互式对话自动打印输入表达式的结果,在这个提示模式下,往往不需要每次都刻意地输入“print”
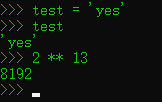
解释器在每行代码输入完成后,也就是按下回车后立即执行。
为什么使用交互提示模式:
实验:代码是立即执行的,且不会带来任何的破坏。要进行真正的破坏,例如删除文件并运行shell命令,你必须尝试显式地导入模块。直接的Python代码总是可以安全运行的。
测试:测试已经写入到文件中的代码的好地方。
使用交互提示模式的注意事项:
只能够输入Python命令:不要输入系统的命令,有一些方法可以在Python代码中使用系统命令,但并不像简单的输入命令那么的直接。
在文件中打印语句是必须的
在交互提示模式下不需要缩进
留意提示符的变换和复合语句
在交互提示模式中,用一个空行结束复合语句
交互模式一次运行一条语句
系统命令行和文件:
尽管交互命令行对于实验和测试来说都很好,但是它也有一个很大的缺点:Python一旦执行了输入的程序之后,它们就消失了。在交互模式下输入的代码是不会保存在一个文件中的,所以为了能够重新运行,不得不从头开始输入。
为了能够永久的保存程序,需要在文件中写入代码,这样的文件通常叫做模块。模块就是一个包含了Python语句的简单文本文件。一旦编写完成,可以让Python解释器多次运行这样的文件中的语句,并且可以以多种方式去运行:通过系统命令行,通过点击图标,通过在IDLE用户界面中选择等方式。无论它是如何运行的,每一次当你运行模块文件时,Python都会从头至尾地执行模块文件中的每一条代码。
这一部分的属于可能会有些变化。例如,模块文件常常作为Python写成的程序。也就是说,一个程序是由一系列预编写好的语句构成,保存在文件中,从而可以反复执行。可以直接运行的模块文件往往也叫做脚本(一个顶层程序文件的非正式说法)。有些人将“模块”这个说法应用于被另一个文件所导入的文件(之后会解释“顶层”和“导入”的含义)。
下面几部分内容将探索如何运行输入至模块文件的代码。这一节将会介绍如何以最基本的方法运行文件:通过在系统提示模式下的Python命令行,列出它们的名字。
第一段脚本:
- import sys
print(sys.platform)
print(2 ** 100)
x = 'Spam!'
print(x * 8)
导入一个Python模块(附加工具的库),以获取系统平台的名称。
运行3个print函数调用,以显示脚本的结果。
使用一个名为x的变量,在创建的时候对其赋值,保存一个字符串对象。
应用下一章开始学习的各种对象操作
sys.platfrom只是一个字符串,它表示我们所工作的计算机的类型,它位于名为sys的标准Python模块中,我们必须导入以加载该模块。
我们已经把这段代码输入到一个文件中,而不是输入到交互提示模式中。在这个过程中,我们已经编写了一个功能完整的Python脚本。
对于所有的顶层文件,也应该直接叫做脚本,但是,要导入到客户端的代码的文件必须用.py后缀。
使用命令行运行文件
一旦已经保存了这个文本文件,可以将其完整的文件名作为一条Python命令的第一个参数,在系统shell提示中输入,从而要求Python来运行它:

由于这种方法使用shell命令行来启动Python程序,所有常用的shell语法都适用。例如,可以使用特定的shell语法,把一个Python脚本的输出定向到一个文件中,从而保存起来以备以后使用或查看:
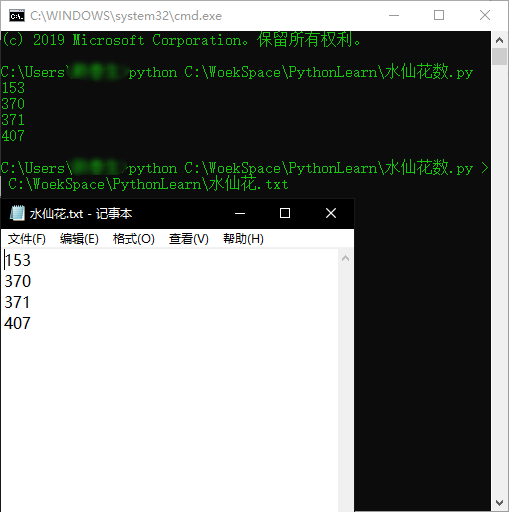
在这个例子里,前面的运行中的4个输出行都存储到了水仙花.txt,(ps.如果不存在这个文件的话会自动创建一个再将输入导入进去)而不是显示出来。这通常叫做流重定向(stream redirection),它用于文本的输入和输出,而且在Windows和类似UNIX的系统上都可以使用。它几乎和Python不相干(Python只是支持它而已),因此,这里略过有关shell重定向语法的细节。
使用命令行和文件的新手陷阱:
注意Windows上的默认扩展名
在系统提示模式下使用文件扩展名,但是在导入时别使用文件扩展名。
在文件中使用print语句
模块导入和重载:
到现在为止,本书已经讲到了“导入模块”,而实际上没有介绍这个名词的意义。我们将会在第五部分深入学习模块和较大的程序架构,但是由于导入同时也是一种启动程序的方法,为了能够入门,这一节将会介绍一些模块的基础知识。
用简单的术语来讲,每一个以扩展名py结尾的Python源代码文件都是一个模块。其他的文件可以通过导入一个模块读取这个模块的内容。导入从本质上来讲,就是载入另一个文件,并能够读取那个文件的内容。一个模块的内容通过这样的属性(这个术语我们将在下一节定义)能够被外部世界使用。
这种基于模块的方式使模块变成了Python程序架构的一个核心概念。更大的程序往往以多个模块文件的形式出现,并且导入了其他模块文件的工具。其中的一个模块文件设计成主文件,或叫做顶层文件(就是那个启动后能运行整个程序的文件)。
本章最关心的是被载入文件通过导入操作最终可运行代码。导入文件是另一种运行文件的方法。
例如,创建一个交互对话,通过简单的import来实现运行之前的水仙花数.py
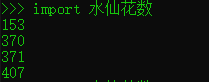
默认情况下,会在每次会话的第一次运行。在第一次导入之后,其他导入都不会再工作,甚至在另一个窗口中改变并保存了模块的源代码文件也不行。
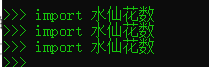
这是有意设计的结果,导入是一个开销很大的操作,以至于每个文件,每个程序运行不能够重复多余一次。当学习到第21章时会了解,导入必须找到文件,将其编译成字节码,并且运行代码。
但是如果真的想要Python在同一次会话中再次运行文件(不停止和重新启动会话),需要调用importlib标准库模块中可用的reload函数:
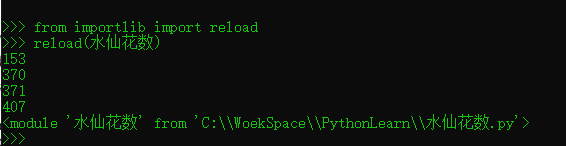
这里的from语句直接从一个模块中复制出一个名字。reload函数载入并运行文件最新版本的代码,如果已经在另一个窗口中修改并保存了它,那将反映出修改变化。这允许你在当前交互会话的过程中编辑并改进代码。
reload函数希望获得的参数是一个已经加载了模块对象的名称,所以如果在重载之前,请确保已经成功地导入了这个模块。值得注意的是,reload函数在模块对象的名称前还需要括号,import则不需要。reload是一个被调用的函数,而import是一个语句。
最后一行输出是reload调用后的返回值的打印显示,reload函数的返回值是一个Python模块对象。
模块的显要特性:属性
导入和重载提供了一种自然的程序启动的选择,因为导入操作将会是最后一步执行文件。从更宏观的角度来看,模块扮演了一个工具库的角色。从一般意义上来说,模块往往就是变量名的封装,被认作是命名空间。在一个包中的变量名就是所谓的属性:也就是说,属性就是绑定在特定对象上的变量名。
在典型的应用中,导入者得到了模块文件中在顶层所定义的所有变量名。这些变量名通过被赋值给通过模块函数、类、变量以及其他被导出的工具。这些往往都会在其他文件或程序中使用。表面上看,一个模块文件的变量名可以通过两个Python语句读取------import和from,以及reload调用。
创建一个单行的Python模块文件,内容如下:
- title = "The Meaning of Life"
当文件导入时,它的代码运行并生成了模块的属性,这个赋值语句创建了一个名为title的模块的属性。
可以通过两种不同的办法从其他组件获得该模块的title属性:
import语句将这个模块整体载入,并使用模块后跟一个属性名来获取它:
- >>> print(myfile.title)
The Meaning of Life
一般来说,这里的点号表达式代表了
object.attribute的语法,可以从任何的object中取出其任意的属性,并且这是Python代码中的一个常用操作。在这里,我们已经使用了它去获取在模块myfile中的一个字符串变量title,即myfile.title。- >>> print(myfile.title)
作为替代方案,可以通过这样的语句从模块文件中获得(实际上是复制)变量名:
- $ python
>>> from myfile import
>>> print(title)
The Meaning of Life
- $ python
就像今后看到的更多细节一样,from和import很相似,只不过增加了对载入组件的变量名的额外的赋值。从技术上讲,from复制了模块的属性,以便属性能够成为接受者的直接变量。因此,能够直接以title(一个变量)引用导入字符串而不是myfile.title(一个属性引用)。
无论使用的是import还是from去执行导入操作,模块文件myfile.py的语句都会执行,并且导入的组件(对应这里是交互提示模式)在顶层文件中得到了变量名的读取权。也许在这个简单的例子中只有一个变量名,但是如果开始在模块中定义对象,例如,函数和类时,这个概念将会很有用。这样一些对象就变成了可重用的组件,可以通过变量名被一个或多个客户端模块读取。
在实际应用中,模块文件往往定义了一个以上的可被外部文件使用的变量名。下面这个例子中定义了三个变量名:
- a = 'dead'
b = 'parrot'
c = 'sketch'
print(a, b, c)
文件treenames.py,给三个变量赋值,并对外部世界生成了三个属性。这个文件并且在一个print语句中使用它自由的三个变量,就像在将其作为顶层文件运行时看到的结果一样:
- $ python threenames.py
dead parrot sketch
所有的这个文件的代码运行起来就和第一次从其他地方导入(无论是通过import或者from)后一样,这个文件的客户端通过import得到了具有属性的模块,而客户端使用from时,则会获得文件变量名的复本。
- $ python
>>> import threenames
dead parrot sketch
>>>
>>> threenames.b, threenames.c
('parrot', 'sketch')
>>>
>>> fron threenames import a, b, c
>>> b, c
('parrot', 'sketch')
一旦你开始就像这里一样在模块文件编写多个变量名,内置的dir函数开始发挥作用了。你可以使用它来获得模块内部的可用的变量名的列表。下面代码返回了一个Python字符串列表:

进行调用后,它将返回这个模块内部的所有属性。其中返回的一些变量名是“免费”获得的:一些以双下划线开头并结尾的变量名;这些通常都是由Python预定义的内置变量名,对于解释器来说有特定的意义。那些通过代码赋值而定义的变量(a, b, c)在dir结果的最后显示。
模块和命名空间:
模块导入是一种运行代码文件的方法,但是就像稍后我们即将在本书中讨论的那样,模块同样是Python程序最大的程序结构。
一般来说,Python程序往往由多个模块文件构成,通过import语句连接在一起。每个模块文件是一个独立完备的变量包,即一个命名空间。一个模块文件不能看到其他文件定义的变量名,除非它显式地导入了那个文件,所以模块文件在代码文件中起到了最小化命名冲突的作用。因为每个文件都是一个独立完备的命名空间,即使在它们拼写相同的情况下,一个文件的变量名是不会与另一个文件中的变量冲突的。
实际上,就像你将看到的那样,正是由于模块将变量封装为不同部分,Python具有了能够避免命名冲突的优点。模块是一个不需要重复输入而可以反复运行代码的方法。
import和reload的使用注意事项
避免使用import和reload启动程序。import和reload是Python类中的一种常用测试技术。
使用exec运行模块文件
更多的方法运行模块文件中保存的代码。例如,exec(open('module.py').read())内置函数调用,是从交互提示模式启动文件而不必导入以及随后的重载的一种方法。每次exec都运行文件的最新版本,而不需要随后的重载(script1.py保留我们在前面小姐中一次重载它之后的样子):
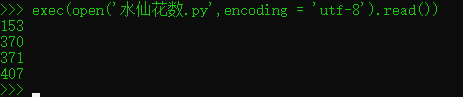
exec调用有着类似于import的效果,但是,它从技术上不会导入模板,默认情况下,每次以这种方式调用exec的时候,它都重新运行文件,就好像我们把文件粘贴到了调用exec的地方。因此,exec不需要在文件修改后进行模块重载,它忽略了常略的模块导入逻辑。
缺点是,由于exec的工作机制就好像在调用它的地方粘贴了代码一样,和前面提到的from一样,对于当前正在使用的变量有潜在的默认覆盖的可能。例如,我们的script1.py赋给了一个名为x的变量。如果这个名字已经在exec调用的地方使用了,那么这个名称的值将被覆盖。
- >>> x = 999
>>> exec(open('script1.py').read())
>>> x
'Spam!'
相反,基本的import语句每个进程只运行文件一次,并且它会把文件生成一个单独的模块名称空间中,以便它的赋值不会改变你的作用域中的变量。为模块名称空间分割所付出的代价是,在修改之后需要重载。
IDLE用户界面:
IDLE提供了做Python开发的用户图形界面(GUI),而且它是Python系统的一个标准并免费的部分。它往往被认为是一个集成开发环境(IDE),因为它在一个单独的界面中绑定了很多开发任务。
简而言之,IDLE是一个能够编辑、运行、浏览和调试Python程序的GUI,所有都能够在单独的界面实现。此外,由于IDLE是使用Tkinter GUI工具包开发的Python程序,可以在几乎任务Python平台上运行。对于很多人来说,IDLE代表了一种简单易用的命令行输入的替代方案,并且比点击图标出问题的可能性更小。
其他启动选项:
到现在为止,我们已经看到了如何运行代码交互地输入,以及如何以各种不同的方式启动保存在文件中的代码:在系统命令行中运行、import和exec、使用IDLE这样的GUI等。这基本上包括了本书中提到的所有情况。然而,还有运行Python代码的其他方法,其中大多数都有专门或有限的用途。下一小节我们将简要介绍这些方法。
嵌入式调用:
在一些特定的领域,Python代码也许会在一个封闭的系统中运行。在这样的情况下,我们说Python程序被嵌入在其他程序中运行。在这样的情况下,我们说Python程序被嵌入在其他程序中运行。Python代码可以保存到一个文本文件中、存储在数据库中、从一个HTML页面获取、从XML文件解析等。但是从执行的角度来看,另一个系统(而不是你)会告诉Python去运行你创建的代码。
这样的嵌入执行模式一般用来支持终端用户定制的。例如,一个游戏程序,也许允许用户进行游戏定制(及时地在策略点存取Python代码)。用户可以提供或修改Python代码来定制这种系统。由于Python代码是解释性的,不必重新编译整个系统以融入修改。
冻结二进制的可执行性:
如前一章所介绍的那样,冻结二进制的可执行性是集成了程序的字节码以及Python解释器为一个单个的可执行程序的包。通过这种方式,Python程序可以像其他启动的任何可执行程序一样(图标点击、命令行等)被启动。尽管这个选择对于产品的发售相当适合,但它并不是一个在程序开发阶段适宜使用的选择。一般是在发售前进行封装(在开发完成之后)。看上一章了解这种选择的更多信息。
本章习题:
怎样才能开始一个交互式解释器的会话?
命令行内输入python即可进入交互式解释器的会话
你应该在哪里输入系统命令行来启动一个脚本文件?
系统终端,例如Windows的命令行窗口
指出运行保存在一个脚本文件中的代码的四种或更多的方法
系统终端,鼠标点击,导入和重载(reload)、exec内置函数
指出在Windows下点击文件图标运行脚本的两个缺点
打印后退出的脚本会导致输出文件马上消失
错误信息会在查看其内容前关闭
列举2个使用IDLE的潜在的缺点
IDLE在运行某种程序时会失去响应------特别是使用多线程的GUI程序
IDLE有一些方便的特性在你一旦离开IDLE GUI时会伤害你,例如在IDLE中一份脚本的变量是自动导入到交互的作用域的,而通常Python不是这样。
什么是命名空间,它和模块文件有什么关联?
命名空间就是变量(也就是变量名)的封装。它在Python中以一个带有属性的对象的形式出现。每个模块文件自动成为一个命名空间:也就是说,一个对变量的封装,这些变量对应了顶层文件的赋值。命名空间可以避免在Python程序中的命名冲突------因为每个模块文件都是独立完备的命名空间,文件必须明确地导入其他的文件,才能使用这些文件的变量名。
Python学习日志-03的更多相关文章
- Python学习日志9月13日
昨天的学习日志没有写,乱忙了一整天,政治电脑. 好奇心重,想要给电脑装上传说中LInux操作系统,各种小问题折腾到半夜,今天又折腾到晚上才真正的装上系统. 可是装上系统后又发现各种的不好用.虽然界面比 ...
- Python 学习日志9月19日
9月19日 周二 今天是普通的一天,昨天也是普通的一天,刚才我差点忘记写日志,突然想起来有个事情没做,回来写. 今天早晨学习<Head First HTML and CSS>第十一章节“布 ...
- Python学习日志_2017/09/08
今天早晨学习了<Head First :HTML and CSS>:学习了两个章节,感觉从基础学习特别的踏实,能看懂的同时踏踏实实的锻炼了基础的能力.我个人认为无论哪个行业,最重要的永远是 ...
- Python 学习日志9月20日
9月20日 周三 多大年龄了,还活得像个小孩.——急什么,人生又不长. 你习惯了思考宇宙星辰,一百年真的不长,一生也就不那么长,许多人的价值观念你也就无法理解.同样,许多人也无法理解你的价值观念,感兴 ...
- Python 学习日志9月18日
今天早晨学习了<Head First HTML and CSS>,第10章“div and span”. 看完并且做了练习也算是对div和span扫了个盲,需要在实践练习中加强理解与掌握. ...
- Python学习日志9月17日 一周总结
周一,9月11日 这天写的是过去一周的周总结,我从中找出当天的内容. 这天早晨给电脑折腾装机,早晨基本上没有学习,休息了一个早晨. 下午写的上周总结,完事做mooc爬虫课的作业,<Think P ...
- Python学习日志9月16日
刚才我差点睡着了,差资料的时候太费神,有些累. 今天早晨学习了<head first HTML and CSS>,今天把昨天没看了的关于字体和颜色的一章节看完了,真长.我详细的做了笔记,并 ...
- Python学习日志9月15日
一周就要过去了,而我跟一周以前没什么区别.回想一下,我这周做了什么事情呢.恍然若失.这周的精力都浪费在很多不必要的事情上了.学过一片古文,讲后羿学射箭,他有一个同学跟他一样聪明,在一起学习.后羿呢,专 ...
- Python学习日志9月14日
今天早晨又没有专心致志的学习,我感觉我可能是累了,需要减轻学习的程度来调整一下咯.这几天装电脑弄的昏天暗地的,身体有点吃不消了.时间真是神奇的魔法,这半个月来,每隔几天都有想要改变策略的想法.今天早晨 ...
随机推荐
- Verilog代码和FPGA硬件的映射关系(四)
其实在FPGA的开发中理想情况下FPGA之间的数据要通过寄存器输入.输出,这样才能使得延时最小,从而更容易满足建立时间要求.我们在FPGA内部硬件结构中得知,IOB内是有寄存器的,且IOB内的寄存器比 ...
- 使用cxfreeze打包成exe文件
旧版本下载链接地址python3.4以下的:https://www.lfd.uci.edu/~gohlke/pythonlibs/#cx_freeze 最新版本python3.5以上直接使用 pip ...
- BUUCTF WEB
BUUCTF 几道WEB题WP 今天做了几道Web题,记录一下,Web萌新写的不好,望大佬们见谅○| ̄|_ [RoarCTF 2019]Easy Calc 知识点:PHP的字符串解析特性 参考了一下网 ...
- Chisel3 - bind - Op, ReadOnly, 左值
https://mp.weixin.qq.com/s/F_08jKFMoX9Gf_J_YpsDpg 两个数据变量进行某个操作(op),产生一个输出,这个输出存在一个匿名变量中.这个匿名变量就是以O ...
- (Java实现) 均分纸牌
题目描述 有 N 堆纸牌,编号分别为 1,2,-, N.每堆上有若干张,但纸牌总数必为 N 的倍数.可以在任一堆上取若于张纸牌,然后移动. 移牌规则为:在编号为 1 堆上取的纸牌,只能移到编号为 2 ...
- (Java实现) 活动选择
活动选择的类似问题都可以这么写 import java.util.ArrayList; public class huodongxuanze { /** * //算法导论中活动选择问题动态规划求解 * ...
- 三分钟搭建websocket实时在线聊天,项目经理也不敢这么写
我们先看一下下面这张图: 可以看到这是一个简易的聊天室,两个窗口的消息是实时发送与接收的,这个主要就是用我们今天要讲的websocket实现的. websocket是什么? websocket是一种网 ...
- Ubuntu一键安装Mariadb
系统版本: debian/ ubuntu/ 添加清华大学镜像库: sudo add-apt-repository -r 'https://mirrors.tuna.tsinghua.edu.cn/m ...
- org.apache.maven.plugins:maven-archetype-plugin:RELEASE:generate——解决方案汇总
近期将自己本地的 maven 仓库进行了迁移,idea 的版本也升级到了IntelliJ IDEA 2019.3.3 x64,但是遇到了 Plugins 报红的情况,尝试很多方法,终于解决,现在做一下 ...
- Python 中的类的继承
class parent(object): def override1(self): print("Parent") class child(parent): def overri ...