LevelDB/Rocksdb 特性分析
LevelDb是Google开源的嵌入式持久化KV 单机存储引擎。采用LSM(Log Structured Merge)tree的形式组织持久化存储的文件sstable。LSM会造成写放大、读放大的问题。
1. LevelDb特点:
1、 顺序写、随机写性能高,顺序读性能高,但是随机读性能差,适合于读少写多的场景中。读场景下,可以加一层记录级别的缓存,缓存常用的热点数据,热点数据淘汰算法可以选择LRU算法。LevelDb内部有table cache\block cache,相比于记录级别的缓存,粒度还是比较大。
2、 支持原子操作以批量处理的方式进行
3、 记录存储内部有序,按照Key排序,所以支持有序的范围查询,单点查询是肯定支持的。
4、 范围查询时,支持前序遍历和后序遍历。
5、 支持快照读
6、 数据自动压缩,使用snappy压缩算法
2. LevelDb文件视图

内存中的MemTable和Immutable MemTable,都是由SkipList结构组织
磁盘上的几种主要文件Current文件,Manifest文件,log文件以及SSTable文件。log文件、SSTable文件都是用来存储k-v记录的。SSTable文件属于不同的Level,Level0中的数据最新鲜最热点,随着时间的推移,冷数据会逐步下移到高Level中(Compact操作)。
Manifest 就记载了SSTable各个文件的管理信息,格式如下

Current则用来指出哪个Manifest文件是当前LevleDb进行Compaction操作反应的那个Manifest文件,在LevleDb的运行过程中,随着Compaction的进行,SSTable文件会发生变化,会有新的文件产生,老的文件被废弃,Manifest也会跟着反映这种变化,此时往往会新生成Manifest文件来记载这种变化。
3.LevelDb写入流程
1、顺序写入磁盘log文件;
2、写入内存memtable(采用skiplist结构实现);
3、写入磁盘SST文件(sorted string
table files),这步是数据归档的过程(永久化存储);
其中:
log文件的作用是是用于系统崩溃恢复而不丢失数据,假如没有Log文件,因为写入的记录刚开始是保存在内存中的,此时如果系统崩溃,内存中的数据还没有来得及Dump到磁盘,所以会丢失数据;
在写memtable时,如果其达到check
point(满员)的话,会将其改成immutable memtable(只读),然后等待dump到磁盘SST文件中,此时也会生成新的memtable供写入新数据;
memtable和sstable文件中的key都是有序的,log文件的key是无序的;
LevelDB删除操作也是插入,只是标记Key为删除状态,真正的删除要到Compaction的时候才去做真正的操作;
LevelDB没有更新接口,如果需要更新某个Key的值,只需要插入一条新纪录即可;或者先删除旧记录,再插入也可;
4. LevelDb读取流程
1、在内存中依次查找memtable、immutable memtable;
2、如果配置了cache,查找cache;
3、根据mainfest索引文件,在磁盘中查找sstable文件;
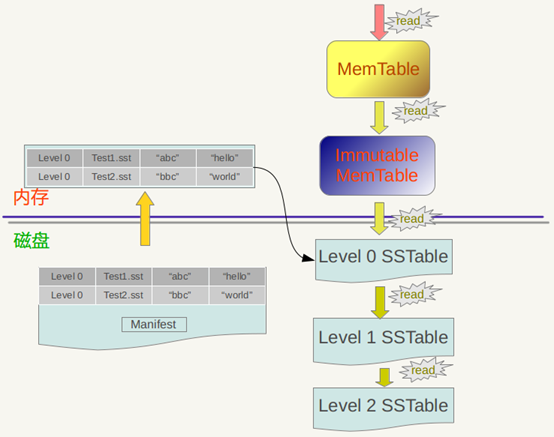
极端情况下,随机读取一条很冷的数据,已经被compact到了Level6层,这时候,读取的操作要跨越多个Level查找,性能很低。如果再加一层记录级别的缓存,可以避免这种消耗。
5. LevelDb compact流程
LevelDb包含其中两种,minor和major。
Minor compaction 的目的是当内存中的memtable大小到了一定值时,将内容保存到磁盘文件中,如下图:
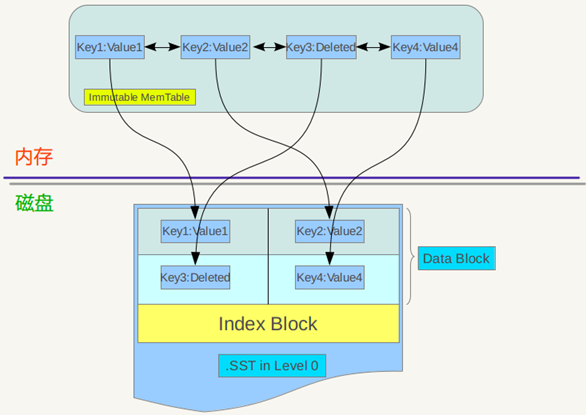
immutable memtable其实是一个SkipList,其中的记录是根据key有序排列的,遍历key并依次写入一个level 0 的新建SSTable文件中,写完后建立文件的index 数据,这样就完成了一次minor compaction。从图中也可以看出,对于被删除的记录,在minor compaction过程中并不真正删除这个记录,原因也很简单,这里只知道要删掉key记录,但是这个KV数据在哪里?那需要复杂的查找,所以在minor compaction的时候并不做删除,只是将这个key作为一个记录写入文件中,至于真正的删除操作,在以后更高层级的compaction中会去做。
当某个level下的SSTable文件数目超过一定设置值后,levelDb会从这个level的SSTable中选择一个文件(level>0),将其和高一层级的level+1的SSTable文件合并,这就是major compaction。
我们知道在大于0的层级中,每个SSTable文件内的Key都是由小到大有序存储的,而且不同文件之间的key范围(文件内最小key和最大key之间)不会有任何重叠。Level 0的SSTable文件有些特殊,尽管每个文件也是根据Key由小到大排列,但是因为level 0的文件是通过minor compaction直接生成的,所以任意两个level 0下的两个sstable文件可能再key范围上有重叠。所以在做major compaction的时候,对于大于level 0的层级,选择其中一个文件就行,但是对于level 0来说,指定某个文件后,本level中很可能有其他SSTable文件的key范围和这个文件有重叠,这种情况下,要找出所有有重叠的文件和level 1的文件进行合并,即level 0在进行文件选择的时候,可能会有多个文件参与major compaction。
LevelDb在选定某个level进行compaction后,还要选择是具体哪个文件要进行compaction,比如这次是文件A进行compaction,那么下次就是在key range上紧挨着文件A的文件B进行compaction,这样每个文件都会有机会轮流和高层的level 文件进行合并。
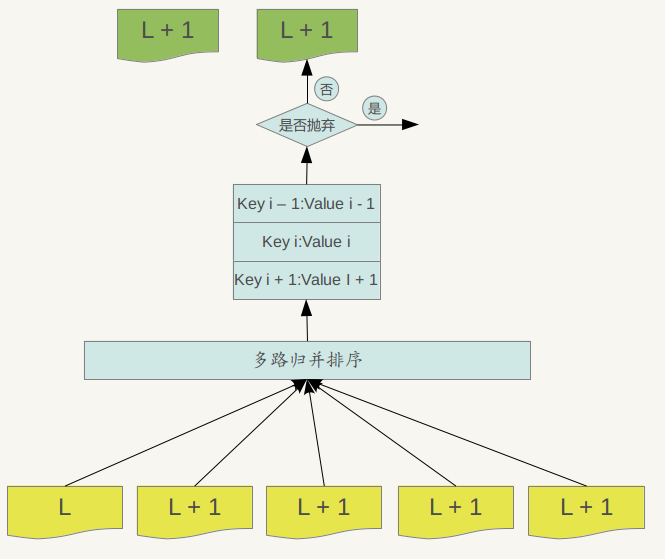
Major compaction的过程如下:对多个文件采用多路归并排序的方式,依次找出其中最小的Key记录,也就是对多个文件中的所有记录重新进行排序。之后采取一定的标准判断这个Key是否还需要保存,如果判断没有保存价值,那么直接抛掉,如果觉得还需要继续保存,那么就将其写入level L+1层中新生成的一个SSTable文件中。就这样对KV数据一一处理,形成了一系列新的L+1层数据文件,之前的L层文件和L+1层参与compaction 的文件数据此时已经没有意义了,所以全部删除。这样就完成了L层和L+1层文件记录的合并过程。
那么在major compaction过程中,判断一个KV记录是否抛弃的标准是什么呢?其中一个标准是:对于某个key来说,如果在小于L层中存在这个Key,那么这个KV在major compaction过程中可以抛掉。因为我们前面分析过,对于层级低于L的文件中如果存在同一Key的记录,那么说明对于Key来说,有更新鲜的Value存在,那么过去的Value就等于没有意义了,所以可以删除。
6. LevelDb 内部cache
前面讲过对于levelDb来说,读取操作如果没有在内存的memtable中找到记录,要多次进行磁盘访问操作。假设最优情况,即第一次就在level 0中最新的文件中找到了这个key,那么也需要读取2次磁盘,一次是将SSTable的文件中的index部分读入内存,这样根据这个index可以确定key是在哪个block中存储;第二次是读入这个block的内容,然后在内存中查找key对应的value。
LevelDb中引入了两个不同的Cache:Table Cache和Block Cache。其中Block Cache是配置可选的,即在配置文件中指定是否打开这个功能。

如上图,在Table Cache中,key值是SSTable的文件名称,Value部分包含两部分,一个是指向磁盘打开的SSTable文件的文件指针,这是为了方便读取内容;另外一个是指向内存中这个SSTable文件对应的Table结构指针,table结构在内存中,保存了SSTable的index内容以及用来指示block cache用的cache_id ,当然除此外还有其它一些内容。比如在get(key)读取操作中,如果levelDb确定了key在某个level下某个文件A的key range范围内,那么需要判断是不是文件A真的包含这个KV。此时,levelDb会首先查找Table Cache,看这个文件是否在缓存里,如果找到了,那么根据index部分就可以查找是哪个block包含这个key。如果没有在缓存中找到文件,那么打开SSTable文件,将其index部分读入内存,然后插入Cache里面,去index里面定位哪个block包含这个Key 。如果确定了文件哪个block包含这个key,那么需要读入block内容,这是第二次读取。

Block Cache是为了加快这个过程的,其中的key是文件的cache_id加上这个block在文件中的起始位置block_offset。而value则是这个Block的内容。
如果levelDb发现这个block在block cache中,那么可以避免读取数据,直接在cache里的block内容里面查找key的value就行,如果没找到呢?那么读入block内容并把它插入block cache中。levelDb就是这样通过两个cache来加快读取速度的。从这里可以看出,如果读取的数据局部性比较好,也就是说要读的数据大部分在cache里面都能读到,那么读取效率应该还是很高的,而如果是对key进行顺序读取效率也应该不错,因为一次读入后可以多次被复用。但是如果是随机读取,效率很低。
7.LevelDb sstable文件存储格式
整体上,sstable文件分为数据区与索引区,尾部的footer指出了meta index block与data index block的偏移与大小,data index block指出了各data block的偏移与大小,meta index block指出了各meta block的偏移与大小。

1)DataBlock:存储Key-Value记录,分为Data、type、CRC三部分
2)MetaBlock:暂时没有使用
3)MetaBlock_index:记录filter的相关信息(本文暂时没有考虑filter)
4)IndexBlock:描述一个DataBlock,存储着对应DataBlock的最大Key值,DataBlock在sst文件中的偏移量和大小
5)Footer :索引的索引,记录IndexBlock和MetaIndexBlock在SSTable中的偏移量了和大小
block
逻辑上主要分为数据与重启点。重启点也是一个指针,指出了一些特殊的位置。data block中的key是有序存储的,相邻的key之间可能有重复,因此存储时采用前缀压缩,后一个key只存储与前一个key不同的部分。那些重启点指出的位置就表示该key不按前缀压缩,而是完整存储该key。除了减少压缩空间之外,重启点的第二个作用就是加速读取。如果说data index block可以通过二分来定位具体的block,那么重启点则可以通过二分的方法来定位具体的重启点位置,进一步减少了需要读取的数据。对于leveldb来讲,可以通过options.block_size与options.block_restart_interval来设置block的大小与重启点的间隔。默认data block的大小为4K。而重启点则每隔16个key。具体的单条record的存储格式如下图所示。

Block格式

Record 格式
data index block
Index Block的结构与Data Block一样,只不过每个group只包含一条记录,即Data Block的最大Key与偏移。其实这里说最大Key并不是很准确,理论上,只要保存最大Key就可以实现二分查找,但是Level DB在这里做了个优化,它并保存最大key,而是保存一个能分隔两个Data Block的最短Key。
如:假定Data Block1的最后一个Key为“abcdefg”,Data Block2的第一个Key为“abzxcv”,则index可以记录Data Block1的索引key为“abd”;这样的分割串可以有很多,只要保证Data Block1中的所有Key都小于等于此索引,Data Block2中的所有Key都大于此索引即可。这种优化缩减了索引长度,查询时可以有效减小比较次数。

data block与meta index block、data index block都是采用block来存储的(filter block稍微不同)。而对于block来讲,其都是按(key,value)格式存储一条条的record的。对于这些不同类型的block,其(key,value)都是什么了?现在只有一个meta block用于filter,因此meta index block中也只有一条记录,其key是filter. + filter_policy的name。 不同block的Key、Value格式如下图。

LevelDB/Rocksdb 特性分析的更多相关文章
- 关于时间序列数据库的思考——(1)运用hash文件(例如:RRD,Whisper) (2)运用LSM树来备份(例如:LevelDB,RocksDB,Cassandra) (3)运用B-树排序和k/v存储(例如:BoltDB,LMDB)
转自:http://0351slc.com/portal.php?mod=view&aid=12 近期网络上呈现了有关catena.benchmarking boltdb等时刻序列存储办法的介 ...
- leveldb源码分析--SSTable之block
在SSTable中主要存储数据的地方是data block,block_builder就是这个专门进行block的组织的地方,我们来详细看看其中的内容,其主要有Add,Finish和CurrentSi ...
- MySQL · 特性分析 · 优化器 MRR & BKA【转】
MySQL · 特性分析 · 优化器 MRR & BKA 上一篇文章咱们对 ICP 进行了一次全面的分析,本篇文章小编继续为大家分析优化器的另外两个选项: MRR & batched_ ...
- leveldb源码分析--WriteBatch
从[leveldb源码分析--插入删除流程]和WriteBatch其名我们就很轻易的知道,这个是leveldb内部的一个批量写的结构,在leveldb为了提高插入和删除的效率,在其插入过程中都采用了批 ...
- leveldb源码分析--Key结构
[注]本文参考了sparkliang的专栏的Leveldb源码分析--3并进行了一定的重组和排版 经过上一篇文章的分析我们队leveldb的插入流程有了一定的认识,而该文设计最多的又是Batch的概念 ...
- Leveldb源码分析--1
coming from http://blog.csdn.net/sparkliang/article/details/8567602 [前言:看了一点oceanbase,没有意志力继续坚持下去了,暂 ...
- leveldb源码分析--SSTable之Compaction
对于compaction是leveldb中体量最大的一部分,也应该是最为复杂的部分,为了便于理解我们首先从一些基本的概念开始.下面是一些从doc/impl.html中翻译和整理的内容: Level 0 ...
- leveldb源码分析—Recover和Repair
leveldb作为一个KV存储引擎将数据持久化到磁盘,而对于一个存储引擎来说在存储过程中因为一些其他原因导致程序down掉甚至数据文件被破坏等都会导致程序不能按正常流程再次启动.那么遇到这些状况以后如 ...
- MySQL · 特性分析 · MDL 实现分析
http://mysql.taobao.org/monthly/2015/11/04/ 前言 在MySQL中,DDL是不属于事务范畴的,如果事务和DDL并行执行,操作相关联的表的话,会出现各种意想不到 ...
随机推荐
- [Objective-C] 010_Foundation框架之NSSet与NSMutableSet
在Cocoa Foundation中的NSSet和NSMutableSet ,和NSArray功能性质一样,用于存储对象属于集合.但是NSSet和NSMutableSet是无序的, 保证数据的唯一性, ...
- MVC案例之新增与修改Customer
新增Customer 添加的流程Add New Customer 超链接连接到 newcustomer.jsp新建 newcustomer.jsp: 在 CustomerServlet 的 addCu ...
- PreparedStatement实现表数据的增删改 & 封装数据库链接和关闭操作
PreparedStatement实现表数据的增删改 PreparedStatementUpdateTest package com.aff.PreparedStatement; import jav ...
- Rocket - tilelink - BankBinder
https://mp.weixin.qq.com/s/oZCYBdy5glxJQmYKVWvpvA 简单介绍BankBinder的实现. 1. 基本介绍 A BankBinder ...
- Qcom平台RTC驱动分析
相关文件list: pm8998.dtsi ---RTC dts配置 qpnp-rtc.c ---qcom RTC驱动 class.c ---RTC相关class interface.c ---相关R ...
- Java写算法题中那些影响你效率的细节(关于暴力破解算法题的细节处理)
QQ讨论群:99979568 多交流才能进步 暂时写到这里,有不懂的欢迎评论, 如果有什么其他提高效率的细节,欢迎评论或者私信我,小编一定努力学习,争取早日分享给大家 如果大家嫌三连累的话,可以看看这 ...
- Java实现 LeetCode 769 最多能完成排序的块(单向遍历)
769. 最多能完成排序的块 数组arr是[0, 1, -, arr.length - 1]的一种排列,我们将这个数组分割成几个"块",并将这些块分别进行排序.之后再连接起来,使得 ...
- C# winform 学习(二)
目标: 1.ADONET简介 2.Connection对象 3.Command对象 4.DataReader对象 准备工作:创建mhys数据库及员工表 代码如下: create database mh ...
- Java实现 蓝桥杯VIP 基础练习 完美的代价
package 蓝桥杯VIP; import java.util.Scanner; public class 完美的代价 { public static int sum = 0; public sta ...
- java实现第四届蓝桥杯公式求值
公式求值 输入n, m, k,输出图1所示的公式的值.其中C_n^m是组合数,表示在n个人的集合中选出m个人组成一个集合的方案数.组合数的计算公式如图2所示. 输入的第一行包含一个整数n:第二行包含一 ...