【python实现卷积神经网络】优化器的实现(SGD、Nesterov、Adagrad、Adadelta、RMSprop、Adam)
代码来源:https://github.com/eriklindernoren/ML-From-Scratch
卷积神经网络中卷积层Conv2D(带stride、padding)的具体实现:https://www.cnblogs.com/xiximayou/p/12706576.html
激活函数的实现(sigmoid、softmax、tanh、relu、leakyrelu、elu、selu、softplus):https://www.cnblogs.com/xiximayou/p/12713081.html
损失函数定义(均方误差、交叉熵损失):https://www.cnblogs.com/xiximayou/p/12713198.html
先看下优化器实现的代码:
import numpy as np
from mlfromscratch.utils import make_diagonal, normalize # Optimizers for models that use gradient based methods for finding the
# weights that minimizes the loss.
# A great resource for understanding these methods:
# http://sebastianruder.com/optimizing-gradient-descent/index.html class StochasticGradientDescent():
def __init__(self, learning_rate=0.01, momentum=0):
self.learning_rate = learning_rate
self.momentum = momentum
self.w_updt = None def update(self, w, grad_wrt_w):
# If not initialized
if self.w_updt is None:
self.w_updt = np.zeros(np.shape(w))
# Use momentum if set
self.w_updt = self.momentum * self.w_updt + (1 - self.momentum) * grad_wrt_w
# Move against the gradient to minimize loss
return w - self.learning_rate * self.w_updt class NesterovAcceleratedGradient():
def __init__(self, learning_rate=0.001, momentum=0.4):
self.learning_rate = learning_rate
self.momentum = momentum
self.w_updt = np.array([]) def update(self, w, grad_func):
# Calculate the gradient of the loss a bit further down the slope from w
approx_future_grad = np.clip(grad_func(w - self.momentum * self.w_updt), -1, 1)
# Initialize on first update
if not self.w_updt.any():
self.w_updt = np.zeros(np.shape(w)) self.w_updt = self.momentum * self.w_updt + self.learning_rate * approx_future_grad
# Move against the gradient to minimize loss
return w - self.w_updt class Adagrad():
def __init__(self, learning_rate=0.01):
self.learning_rate = learning_rate
self.G = None # Sum of squares of the gradients
self.eps = 1e-8 def update(self, w, grad_wrt_w):
# If not initialized
if self.G is None:
self.G = np.zeros(np.shape(w))
# Add the square of the gradient of the loss function at w
self.G += np.power(grad_wrt_w, 2)
# Adaptive gradient with higher learning rate for sparse data
return w - self.learning_rate * grad_wrt_w / np.sqrt(self.G + self.eps) class Adadelta():
def __init__(self, rho=0.95, eps=1e-6):
self.E_w_updt = None # Running average of squared parameter updates
self.E_grad = None # Running average of the squared gradient of w
self.w_updt = None # Parameter update
self.eps = eps
self.rho = rho def update(self, w, grad_wrt_w):
# If not initialized
if self.w_updt is None:
self.w_updt = np.zeros(np.shape(w))
self.E_w_updt = np.zeros(np.shape(w))
self.E_grad = np.zeros(np.shape(grad_wrt_w)) # Update average of gradients at w
self.E_grad = self.rho * self.E_grad + (1 - self.rho) * np.power(grad_wrt_w, 2) RMS_delta_w = np.sqrt(self.E_w_updt + self.eps)
RMS_grad = np.sqrt(self.E_grad + self.eps) # Adaptive learning rate
adaptive_lr = RMS_delta_w / RMS_grad # Calculate the update
self.w_updt = adaptive_lr * grad_wrt_w # Update the running average of w updates
self.E_w_updt = self.rho * self.E_w_updt + (1 - self.rho) * np.power(self.w_updt, 2) return w - self.w_updt class RMSprop():
def __init__(self, learning_rate=0.01, rho=0.9):
self.learning_rate = learning_rate
self.Eg = None # Running average of the square gradients at w
self.eps = 1e-8
self.rho = rho def update(self, w, grad_wrt_w):
# If not initialized
if self.Eg is None:
self.Eg = np.zeros(np.shape(grad_wrt_w)) self.Eg = self.rho * self.Eg + (1 - self.rho) * np.power(grad_wrt_w, 2) # Divide the learning rate for a weight by a running average of the magnitudes of recent
# gradients for that weight
return w - self.learning_rate * grad_wrt_w / np.sqrt(self.Eg + self.eps) class Adam():
def __init__(self, learning_rate=0.001, b1=0.9, b2=0.999):
self.learning_rate = learning_rate
self.eps = 1e-8
self.m = None
self.v = None
# Decay rates
self.b1 = b1
self.b2 = b2 def update(self, w, grad_wrt_w):
# If not initialized
if self.m is None:
self.m = np.zeros(np.shape(grad_wrt_w))
self.v = np.zeros(np.shape(grad_wrt_w)) self.m = self.b1 * self.m + (1 - self.b1) * grad_wrt_w
self.v = self.b2 * self.v + (1 - self.b2) * np.power(grad_wrt_w, 2) m_hat = self.m / (1 - self.b1)
v_hat = self.v / (1 - self.b2) self.w_updt = self.learning_rate * m_hat / (np.sqrt(v_hat) + self.eps) return w - self.w_updt
这里导入了了mlfromscratch.utils中的make_diagonal, normalize函数,它们在data_manipulation.py中。但是好像没有用到,还是去看一下这两个函数:
def make_diagonal(x):
""" Converts a vector into an diagonal matrix """
m = np.zeros((len(x), len(x)))
for i in range(len(m[0])):
m[i, i] = x[i]
return m
def normalize(X, axis=-1, order=2):
""" Normalize the dataset X """
l2 = np.atleast_1d(np.linalg.norm(X, order, axis))
l2[l2 == 0] = 1
return X / np.expand_dims(l2, axis)
make_diagonal()的作用是将x中的元素变成对角元素。
normalize()函数的作用是正则化。
补充:
- np.linalg.norm(x, ord=None, axis=None, keepdims=False):需要注意ord的值表示的是范数的类型。
- np.atleast_1d():改变维度,将输入直接视为1维,比如np.atleast_1d([1])的输出就是[1]
- np.expand_dims():用于扩展数组的维度,要深入了解还是得去查一下。
然后再看看优化器的实现,以最常用的随机梯度下降为例:
class StochasticGradientDescent():
def __init__(self, learning_rate=0.01, momentum=0):
self.learning_rate = learning_rate
self.momentum = momentum
self.w_updt = None def update(self, w, grad_wrt_w):
# If not initialized
if self.w_updt is None:
self.w_updt = np.zeros(np.shape(w))
# Use momentum if set
self.w_updt = self.momentum * self.w_updt + (1 - self.momentum) * grad_wrt_w
# Move against the gradient to minimize loss
return w - self.learning_rate * self.w_updt
直接看带动量的随机梯度下降公式:

这里的β就是动量momentum的值,一般取值是0.9。正好是对应上面的公式,最后更新W和b就是:
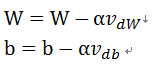
其中 α就表示学习率learning_rate。
至于不同优化器之间的优缺点就不在本文的考虑追之中了,可以自行去查下。
【python实现卷积神经网络】优化器的实现(SGD、Nesterov、Adagrad、Adadelta、RMSprop、Adam)的更多相关文章
- 各种优化器对比--BGD/SGD/MBGD/MSGD/NAG/Adagrad/Adam
指数加权平均 (exponentially weighted averges) 先说一下指数加权平均, 公式如下: \[v_{t}=\beta v_{t-1}+(1-\beta) \theta_{t} ...
- 各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x,使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. Batch gradient d ...
- 基于Python的卷积神经网络和特征提取
基于Python的卷积神经网络和特征提取 用户1737318发表于人工智能头条订阅 224 在这篇文章中: Lasagne 和 nolearn 加载MNIST数据集 ConvNet体系结构与训练 预测 ...
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- 【python实现卷积神经网络】开始训练
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 【python实现卷积神经网络】卷积层Conv2D反向传播过程
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 【python实现卷积神经网络】全连接层实现
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 【python实现卷积神经网络】批量归一化层实现
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 【python实现卷积神经网络】池化层实现
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
随机推荐
- redis 主从同步&哨兵模式&codis
主从同步 1.CPA原理 1. CPA原理是分布式存储理论的基石: C(一致性): A(可用性): P(分区容忍性); 2. 当主从网络无法连通时,修改操作无法同步到节点,所以“一致性”无法满足 ...
- IE浏览器下载文件中文文件名乱码问题解决
处理过程 根据IE的F12中的log提示,是因为http头信息中的编码替换了html文件中的编码.我最初的思路是设置Tomcat默认编码,但是我发现我已经在Server.xml中设置过,想到这里我想到 ...
- Python3之turtle的基本用法#Python学习01#
一.turtle基本语法 1.导入turtle 模块import turtle 2.显示箭头turtle.showturtle() 3.写字符串turtle.write("因小米" ...
- Symantec(赛门铁克)非受管检测
为了查找局域网内没有安装赛门铁克客户端的IP,采用Symantec Endpoint Protect Manager 的非受管检测机制进行网段扫描. 非受管检测机制的原理是:每台电脑开机时都会向同网段 ...
- 题解 P1305 【新二叉树】
好像没有人搞\(\color{green}map\)反映,没有人用\(\color{green}map\)反映搞并查集! \(\color{green}map\)第一个好处是作为一个数组,可以开很大! ...
- coding++:maven根据不同的运行环境,打包不同的配置文件
1.使用maven管理项目中的依赖,非常的方便.同时利用maven内置的各种插件,在命令行模式下完成打包.部署等操作,可方便后期的持续集成使用. 2.但是每一个maven工程(比如web项目),开发人 ...
- Python python 五种数据类型--列表
# 列表的定义 var1 = [] var2 = list() print(type(var1)) #<class 'list'> print(type(var2)) #<class ...
- C# 基础知识系列-7 Linq详解
前言 在上一篇中简单介绍了Linq的入门级用法,这一篇尝试讲解一些更加深入的使用方法,与前一篇的结构不一样的地方是,这一篇我会先介绍Linq里的支持方法,然后以实际需求为引导,分别以方法链的形式和类S ...
- 已知IP地址和子网掩码求出网络地址、广播地址、地址范围和主机数(转载https://blog.csdn.net/qq_39026548/article/details/78959089)
假设IP地址为128.11.67.31,子网掩码是255.255.240.0.请算出网络地址.广播地址.地址范围.主机数.方法:将IP地址和子网掩码转化成二进制形式,然后进行后续操作. IP地址和子网 ...
- 二、【Docker笔记】Docker的核心概念及安装
Docker主要有三大核心的概念,分别为镜像(Image).容器(Container)及仓库(Repository). 一.核心概念 1.Docker镜像 Docker镜像其实与虚拟机镜像很类似, ...