并发05--JAVA并发容器、框架、原子操作类
一、ConcurrentHashMap的实现原理与使用
1、为什么要使用ConsurrentHashMap
两个原因,hashMap线程不安全(多线程并发put时,可能造成Entry链表变成环形数据结构,Entry的next节点永不为空,就会产生死循环获取Entry),hashTable效率低(HashTable是使用synchronized修饰的,如果put一个值,所有对hashTable的操作都要被阻塞,get操作也会被阻塞)。
而ConcurrentHashMap使用的是分段锁,每一把锁用于锁住部分数据,从而提高了效率。
2、ConcurrentHashMap的数据结构
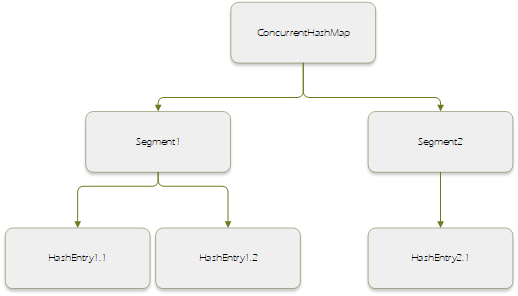
ConcurrentHashMap的数据结构如上图所示,是由Segment和HashEntry组成,Segment是一种可重入锁,HashEntry则用于存储键值对数据。Segment数据结构和HashMap数据结构类似,是一种数组和链表的结构。一个Segment中包含一个HashEntry数组,当对HashEntry中数据进行修改时,必须先获得它对应的Segment锁。
3、定位Segment
ConcurrentHashMap会首先使用Wng/jenkins hash的变种算法对元素hashCode进行一次再散列,从而减少冲突,使元素可以均匀的分布在Segment上。
4、ConcurrentHashMap的操作
ConcurrentHashMap的get操作是在定位到Segment后,再通过散列算法定位到元素,get非常的高效,整个get过程不需要加锁,除非读到的值为空才会加锁重读。那么为什么get操作不需要加锁呢,这是因为get方法将使用到的共享变量都定义成了volatile类型,,例如统计Segment大小的count和hashEntry对应的value。
ConcurrentHashMap的put方法需要加锁,put方法首先定位到segment,然后在segment里进行插入操作。插入操作需要进行两个步骤,第一步是判断是否需要扩容,第二步是定位添加元素的位置,然后将他放到HashEntry中。对于扩容,在插入元素前,先判断segment中的Entry是否超过容量,如果超过,直接先进行扩容,这里需要说的一点是,ConcurrentHashMap的扩容是先判断是否扩容,需要的话再扩容,然后插入;而HashMap的扩容是先插入元素,插入后再判断是否需要扩容,这就导致了,如果本次扩容后没有新的元素添加,那么就会有一次无效的扩容。对于ConcurrentHashMap的扩容,首先会创建一个是原容量二倍的数组,然后将原数组中的元素进行再散列后插入到新的数组里,同时,为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只是对segment进行扩容。
ConcurrentHashMap要是统计整个ConcurrentHashMap中元素的个数,那么就需要将每个segment中的元素数加个,但是在累加过程中,虽然两次获取count的值发生变化的概率非常小,但是仍然存在,因此ConcurrentHashMap使用了先尝试两次通过不锁柱segment的方式来统计各个segment大小,如果统计过程中,容器的count没有变化,那么直接累加之和就可以,如果count有变化,则再使用加锁的方式来统计所有segment的大小。这里说明一下,在put、remove和clean方法里都会操作变量modCount,每操作一次,modCount就会加1,再统计count时,是使用modCount的值来判断ConcurrentHashMap是否有变化。
二、ConcurrentLinkedQueue
在并发编程中有时候需要使用线程安全的队列,通常有两种办法,一种是使用阻塞算法,一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队通用一把锁)或两个锁(入队和出队各一把锁)等方式来实现;非阻塞的实现方式可以使用循环CAS的方式来实现。而ConcurrentLinkedQueue则是使用的非阻塞的方式实现的。
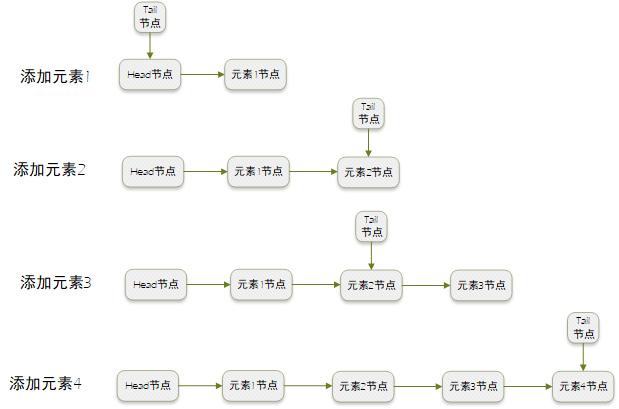
ConcurrentLinkedQueue的入队列(将节点添加到队列尾部)流程如下图所示,初始状态下,tail节点等于head节点,添加元素1时,tail节点仍等于head节点,head节点的下一个节点是元素1节点,添加第二个节点时,tail节点等于元素2节点,以此类推,可以发现,tail节点并不总是尾节点,而是使用了一个HOPS的设计,默认情况下HOPS为1,就是如下图所示,不是每一次元素插入都会更新tail节点,而是等tail节点与尾节点的间距超过了HOPS,就会将tail节点设置成尾节点。这样设计的好处是避免了每次插入元素都要通过CAS更新tail节点。
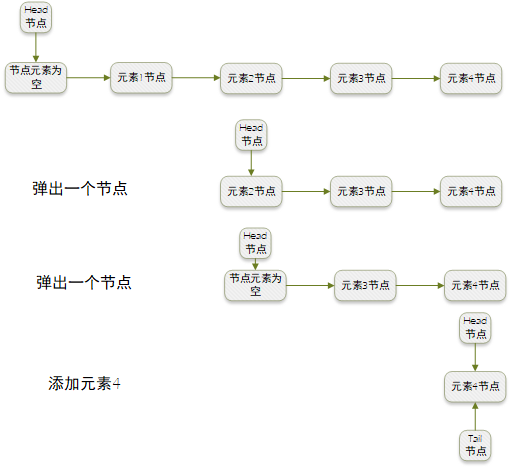
元素的出队基本上入队一致,操作如下图所示:
三、Java中的阻塞队列
阻塞队列是支持两个附加操作的队列,这两个附加操作是支持阻塞的插入和阻塞的移除。
阻塞的插入:当一个队列满的时候,队列会阻塞插入元素,直到队列不满
阻塞的移除:当一个队列为空时,队列会阻塞的移除元素,直到队列不为空
阻塞队列一般用于生产者消费者模式,队列存放生产者生产的数据,消费者从队列中获取并移除数据。
对于阻塞队列的操作如下表格所示:
| 方法/处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
| 添加方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除方法 | remove(e) | poll() | take() | poll(time,unit) |
| 检查方法 | element() |
peek() |
不可用 | 不可用 |
抛出异常:当队列满时,如果再往队列中添加元素,会抛出异常信息。同样,当队列为空时,如果从队列中移除元素,同样会抛出异常。
返回特殊值:当往队列中插入元素时,会返回元素是否插入成功,成功返回true;如果是移除方法,则是从队列中取出一个元素,如果没有则返回null。
一直阻塞:当队列满时,如果添加元素,则一直阻塞,直到队列不满或者响应中断;当队列为空时,如果移除元素,则一直阻塞,直到队列不为空或响应中断
超时退出:当队列满时,如果添加元素,则一直阻塞,如果超时队列仍是满的或没有相应中断,则生产者线程将会退出。
JDK目前提供的阻塞队列有如下几个
| 阻塞队列 | 描述 | 说明 |
| ArrayBlockingQueue | 一个由数组组成的有界阻塞队列 | 默认情况下不保证公平 |
| LinkedBlockingQueue | 一个由链表组成的有界阻塞队列 | 队列默认和最大长度是Integer.MAX_VALUE |
| PriortyBlockingQueue | 一个支持优先级排序的无界阻塞队列 | 默认情况下元素采取自然序列升序排列,也可以自己实现compareTo()方法来自定义排序方式;但是同优先级的元素不保证顺序 |
| DelayQueue | 一个支持延时获取元素的无界阻塞队列 |
队列使用PriotyBlockingQueue实现,队列中的元素必须实现Delay接口,在创建元素时可以指定多久才能从队列中获取当前元素,只有在延迟期满时次能从队列中提取元素。DelayQueue队列可以使用在缓存和定时任务调用上,例如TimerQueue就是使用DelayQueue实现的。 |
| SynchronousQueue | 一个不存储元素的阻塞队列 | 每一个put操作必须等待一个take操作,否则不能继续添加元素 |
| LinkedTransferQueue | 一个由链表组成的无界阻塞队列 | 相比其他队列,该队列多了两个方法tryTransfer和transfer,已transfer方法为例,如果当前队列由消费者,该方法可以将元素立刻传输给消费者;如果没有消费着,该方法会将元素放在tail节点,直到被消费者消费才返回。tryTransfer的区别是直接返回ture或false,不会被阻塞,同样也提供了超时方法。 |
| LinkedBlockingDeque | 一个由链表组成的双向阻塞队列 |
所谓的双向队列指的是可以从队列两端插入和移除元素。也正是多了一个插入和移除元素的口,因此减少了竞争。相比其他队列,LinkedBlockingDeque队列提供了addFirst、addLast、offerFirst、offerLast、peekFirst、peekLast等方法,以first结尾的方法都是操作队列头,以Last结尾的都是操作队列尾。另外add方法等同于addFirst,remove方法等同于removeLast,但是take方法等同于takeFirst。该队列可以运用在工作窃取模式上。 |
四、Java中的原子操作类
1、源自更新基本数据类型
AtomicBoolean:原子更新布尔类型
AtomicInteger:原子更新整形
AtomicLong:原子更新长整形
但是java中还有别的基本类型,比如char、float、double等、那么别的基本类型怎么实现原子操作呢,查看源码可以看到,Unsafe提供了三种CAS方法,compareAndSwapObject、compareAndSwapInteger、compareAndSwapLong,那么对于上述提到的AtomicBoolean是如何处理的呢,查看源码可以发现,是将Boolean转成了整形来操作的,那么对于其他的类型,也可以使用这种思路来处理。
以上方法几乎一摸一样,以AtomicInteger为例,常用方法如下:
| 方法 | 描述 |
| int addAndGet(int date) | 以原子方式将输入的数值与实例中的值相加,并返回结果 |
| boolean compareAndSet(int expect, int update) | 如果出入的数值等于预期值,则将值更新未update,并返回true;否则返回fasle |
| int getAndIncrement() | 以原子方式将当前值加1,返回加1前的旧值 |
| void lazySet(int newValue) | 懒更新,最终肯定会设置为newValue,但是其他线程在一段时间内读取的仍然是旧值 |
| int getAndSet(int newValue) | 以原子方式将值更新为newValue,返回更新前的旧值 |
代码示例:
package com.example2.demo2.controller; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.atomic.AtomicInteger; @Slf4j
public class AtomicIntegerTest {
static AtomicInteger atomicInteger = new AtomicInteger();
public static void main(String[] arg){
int old = atomicInteger.get();
int a = atomicInteger.getAndIncrement();
int newValue = atomicInteger.get(); log.info("{}===={}===={}",old,a,newValue);
}
}
输出结果:
::01.784 [main] INFO com.example2.demo2.controller.AtomicIntegerTest - ========
(2)原子更新数组
包括的类如下:
| 类 | 描述 |
| AtomicIntegerArray | 原子更新数组中的Integer元素 |
| AtomicLongArray | 原子更新数组中的长整形元素 |
| AtomicReferenceArray | 原子更新数组中的引用类型元素 |
上述三个类的方法几乎一样,因此以AtomicIntegerArray为例介绍其方法:
| 方法 | 描述 |
| int addAndGet(int i, int data) | 以原子的方式将输入的值与元素中索引i的值相加 |
| boolean compareAndSet(int i, int expect, int update) | 如果当前值等于预期值,则以原子方式将数组位置i的元素更新为update |
代码示例:
package com.example2.demo2.controller; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.atomic.AtomicIntegerArray; @Slf4j
public class AtomicIntegerArrayTest {
static int[] value = new int[]{,};
static AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(value);
public static void main(String[] arg){
int a = atomicIntegerArray.getAndSet(,);
int b = atomicIntegerArray.get();
int c = value[];
log.info("{}===={}===={}",a,b,c);
}
}
输出结果:
::43.431 [main] INFO com.example2.demo2.controller.AtomicIntegerArrayTest - ========
可以发现输出结果b、c的结果都不一样,这是因为,c获取的是原有数组的value中索引为1的元素,而b获取额是atomicIntegerArray中索引为1的元素,二者不同的原因是,当value作为参数传入AtomicIntegerArray后,AtomicIntegerArray会新建一个数组,不会变更原有数组。
(3)原子更新引用类型
提供的类如下所示:
| 类 | 描述 |
| AtomicReference | 原子更新引用类型 |
| AtomicReferenceFieldUpdater | 原子更新引用类型中的字段 |
| AtomicMarkableReference | 原子更新带有标记位的引用类型;可以原子更新一个布尔类型的标记位和引用类型 |
同样,以上及各类基本一样,就以AtomicReference为例:
package com.example2.demo2.controller; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.atomic.AtomicReference; @Slf4j
public class AtomicRenferenceTest {
static AtomicReference<User> userAtomicReference = new AtomicReference<User>();
public static void main(String[] arg){
User user = new User("lcl",);
userAtomicReference.set(user);
User updateUser = new User("mm",);
userAtomicReference.compareAndSet(user,updateUser);
log.info("{}===={}",userAtomicReference.get().name,userAtomicReference.get().age);
} static class User{
private String name;
private int age; public User(String name, int age){
this.name = name;
this.age = age;
} public String getName(){
return this.getName();
} public int getAge(){
return this.age;
}
}
}
输出结果:
::46.076 [main] INFO com.example2.demo2.controller.AtomicRenferenceTest - mm====
(4)原子更新字段类
提供的类如下所示:
| 类 | 描述 |
| AtomicIntegerFieldUpdater | 原子更新整形字段的更新器 |
| AtomicLongFieldUpdater | 原子更新长整形字段的更新器 |
| AtomicStampedFieldUpdater | 原子更新带有版本号的引用类型;该类将整数数值与引用关联起来,可用于原子的更新数据和数据的版本号,可以解决使用CAS进行原子更新时可能出现的ABA问题 |
要想原子的更新字段类型需要两步,第一步,因为原子更新字段类都是抽象类,因此每次使用都要使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性;第二步,更新类的字段(属性)必须使用public volatile修饰。
package com.example2.demo2.controller; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.atomic.AtomicIntegerFieldUpdater; @Slf4j
public class AtomicIntegerFieldUpdaterTest {
private static AtomicIntegerFieldUpdater<User> userAtomicIntegerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(User.class,"age");
public static void main(String[] arg){
User user = new User("lcl",);
int a = userAtomicIntegerFieldUpdater.getAndIncrement(user);
int b = userAtomicIntegerFieldUpdater.get(user);
log.info("{}===={}",a,b);
} public static class User{
private String name;
public volatile int age; public User(String name, int age){
this.name = name;
this.age = age;
} public String getName(){
return this.getName();
} public int getAge(){
return this.age;
}
}
}
输出结果:
::39.294 [main] INFO com.example2.demo2.controller.AtomicIntegerFieldUpdaterTest - ====
并发05--JAVA并发容器、框架、原子操作类的更多相关文章
- 并发之java.util.concurrent.atomic原子操作类包
15.JDK1.8的Java.util.concurrent.atomic包小结 14.Java中Atomic包的原理和分析 13.java.util.concurrent.atomic原子操作类包 ...
- 【多线程与并发】Java并发工具类
主要有两类 ①并发流程控制相关:CountDownLatch.CyclicBarrier.Semaphore ②线程间交换数据相关:Exchanger: CountDownLatch 作用:允许一个或 ...
- 并发艺术--java并发机制的底层实现原理
前言 Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和CPU的指令. 一 ...
- Java 中12个原子操作类
从JDK1.5 开始提供了 java.util.concurrent.atomic 包,该包提供了一种用法简单.性能高效.线程安全的更新一个变量的方法 原子更新基本类型类 AtomicBoolean: ...
- Java之集合框架vector类设计原理
- Java并发编程(07):Fork/Join框架机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.Fork/Join框架 Java提供Fork/Join框架用于并行执行任务,核心的思想就是将一个大任务切分成多个小任务,然后汇总每个小任务 ...
- Java并发编程(08):Executor线程池框架
本文源码:GitHub·点这里 || GitEE·点这里 一.Executor框架简介 1.基础简介 Executor系统中,将线程任务提交和任务执行进行了解耦的设计,Executor有各种功能强大的 ...
- Java 并发编程-不懂原理多吃亏(送书福利)
作者 | 加多 关注阿里巴巴云原生公众号,后台回复关键字"并发",即可参与送书抽奖!** 导读:并发编程与 Java 中其他知识点相比较而言学习门槛较高,从而导致很多人望而却步.但 ...
- Java并发编程(06):Lock机制下API用法详解
本文源码:GitHub·点这里 || GitEE·点这里 一.Lock体系结构 1.基础接口简介 Lock加锁相关结构中涉及两个使用广泛的基础API:ReentrantLock类和Condition接 ...
- 10分钟搞定 Java 并发队列好吗?好的
| 好看请赞,养成习惯 你有一个思想,我有一个思想,我们交换后,一个人就有两个思想 If you can NOT explain it simply, you do NOT understand it ...
随机推荐
- js函数prototype属性学习(一)
W3school上针对prototype属性是这么给出定义和用法的:使您有能力向对象添加属性和方法.再看w3school上给的那个实例,如下图: 仔细一看,原来最基本的作用就是对某些对象的属性.方法来 ...
- Java实现 蓝桥杯VIP 算法训练 一元三次方程
问题描述 有形如:ax3+bx2+cx+d=0 这样的一个一元三次方程.给出该方程中各项的系数(a,b,c,d 均为实数),并约定该方程存在三个不同实根(根的范围在-100至100之间),且根与根之差 ...
- Java实现蓝桥杯VIP 算法训练 矩阵乘方
import java.util.Scanner; public class 矩阵乘方 { public static void main(String[] args) { Scanner scann ...
- Java实现 洛谷 P1009 阶乘之和
import java.util.Scanner; public class 阶乘之和 { public static void main(String[] args) { Scanner sc = ...
- TZOJ 数据结构实验--静态顺序栈
描述 创建一个顺序栈(静态),栈大小为5.能够完成栈的初始化.入栈.出栈.获取栈顶元素.销毁栈等操作. 顺序栈类型定义如下: typedef struct { int data[Max]; i ...
- CGLIB动态代理机制,各个方面都有写到
CGLIB库介绍 代理提供了一个可扩展的机制来控制被代理对象的访问,其实说白了就是在对象访问的时候加了一层封装.JDK从1.3版本起就提供了一个动态代理,它使用起来非常简单,但是有个明显的缺点:需要目 ...
- python自学Day07(自学书籍python编程从入门到实践)
第8章 函数 函数是带名字的代码块,用于完成具体的工作. 学习定义函数,向函数传递信息. 学习如何编写主要任务是显示信息的函数,还有用于处理数据并返回一个或一组值得函数. 学习如何将函数存储在被称为模 ...
- java实现简单的oss存储
oss 工作中需要用到文件上传,之前使用的是本地文件系统存储方式,后来重构为支持多个存储源的方式,目前支持三种方式:local.seaweedfs.minio 存储介质 seaweedfs seawe ...
- v-model 指令来实现双向数据绑定
<div id="app"> <p>{{ message }}</p> <input v-model="message" ...
- Python字符串处理 - str/bytes
目录 1. str 2. bytes / bytearray 3. printf-style String Formatting 1. str homepage str.count(sub[, sta ...