Programming Model
上级:https://www.cnblogs.com/hackerxiaoyon/p/12747387.html
Dataflow Programming Model
数据流的开发模型
Levels of Abstraction
抽象的分层
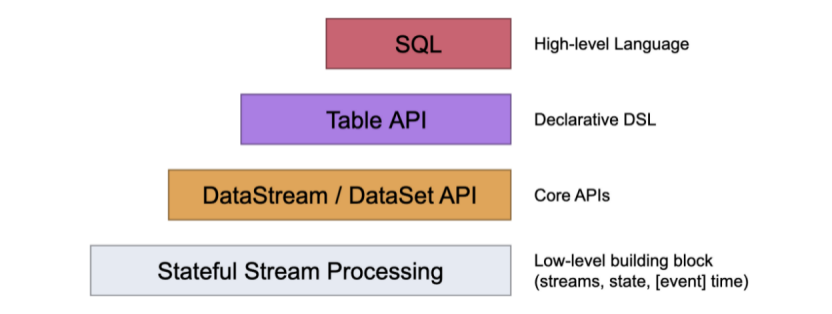
flink提供了不同的抽象分层来开发流和批的应用。
最底层抽象简单提供了状态流。通过 process 函数被嵌入到DataStream的api中。可以允许用户自由的在一个或者多个流中操作事件和使用一致性容错状态。此外,用户可以在回调过程注册事件事件和处理事件,允许程序实现复杂的计算。
实践中,大多树的应用不需要以上这种低层次的抽象,取而代替的是Core API 像DataStream API 和 DataSet API。这些api中提供了一些用户特殊的一些函数,joins,aggregations,windows,state等。
DataStream API 继承了低层次的处理函数,目的只是为了能够接触到更底的抽象层对于一些操作。DataSet API在有界的数据集提供了额外的操作,像 循环/迭代。(这句话读的很费劲儿)
Table API 是一个以表为中心声明式的DSL,可能是动态的改变表。Table API遵循的关系模型:表有一个附加模式schema,就像我们的关系型数据的中schema,如:public.user, public就是schema 命名,然后user就是我们的表名。接口同样也提供了一些类似sql中的那些查询,像:select,project,join,group-by,aggregate等这些。Table API声明式地定义应该执行声明逻辑操作,而不是确切地指定操作代码的外观。尽管Table API 扩展可以通过各种用户定义的方法,但是它的表达能力不然会Core api的,但是使用起来更加简洁,因为代码部分会少些很多。此外,Table API 程序在执行之前会通过一个优化器来优化。这个优化器可以在tables 和 DataStream/DataSet 之间来回无缝转换,允许程序去混合TableApi 和 DataStream 和 DataSet API。
最高的抽象层是SQL。这个抽象类似于Table API在语义和表达上,但是程序上是SQL语句的查询表达方式。SQL这一层的抽象与Table API内部的实现很密切,Sql的查询语句可以在Table API中定义的表上执行。
Programs and Dataflows
Flink 程序基本构造块是流和转换。流就是我们一条一条的数据并且这些数据在源源不断的流动,一个转换就是一个操作把一个流或者多个流作为一个输入,然后产生一个或者多个输出流。
当执行时候,flink程序会映射到数据流中,由流和转换的操作组成。每个数据流的开始都是去接受一个或者多个sources,结束是落地到一个或者多个sinks。数据流类似任意的有向无环图(DAGs)。尽管通过迭代构造器允许这种特殊形式的循环,但是为了简单起见,我们大多数还是会忽略这一点。
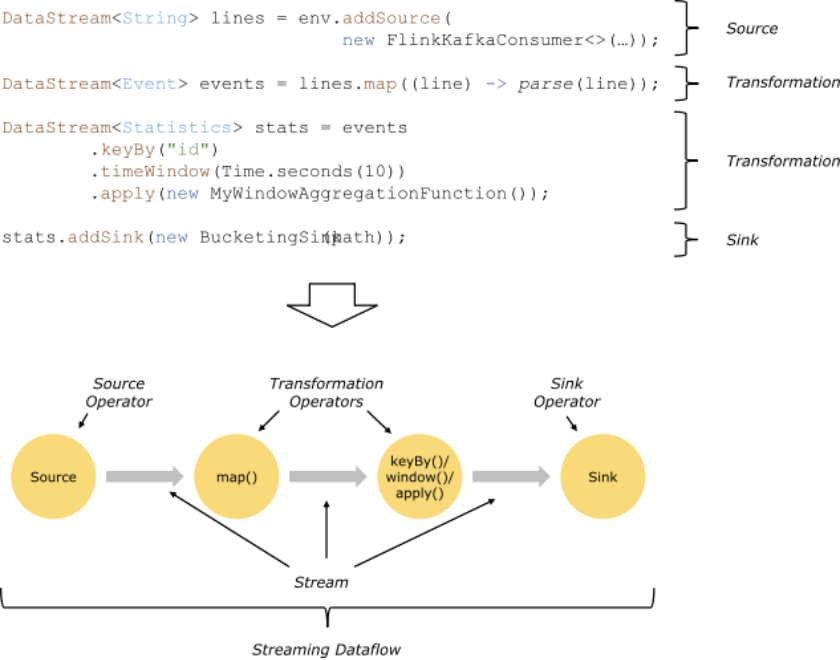
通常在程序转换与数据流的操作之间是一一对应的。有时候,一次转换可能需要多个转换的操作。
源和落地(也就是你数据最终放的地方)被写在流式连接器(https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/connectors/index.html)和批量连接器(https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/batch/connectors.html)文档中。转换被写在DataStreams的操作(https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/index.html)中和DataSet转换中(https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/batch/dataset_transformations.html)。
Parallel Dataflows
flink程序本质上是并行和分布式的。在执行期间,一个流会有一个或者多个流的分区,每一个操作都有一个或者多个操作子任务。每一个子任务都是独立的,执行在不同的线程中也有可能是不同的机器或者容器。

流中数据可以在两个模式一样的操作中进行传输。
one-to-one 流保存分区和元素的顺序。这个意味着source[1]的subtask[1]接受到的数据在map() 的subtask[1]中同样可以看到并且是一样的顺序。
Redistributing 流改变流的分区情况。每一个操作子任务发送数据到不同的子任务中,依赖于选择的函数,像keyBy()(通过哈希key来重新分区),broadcast()广播,或者rebalance()重新随机分区。在一次元素重发交换,元素中的顺序只被保存在一对发送和接受的子任务,像图中的 map() subtask[1] 和 keyby window的subtask[2].因此在这个例子,每一个key中的顺序被保存,但是并行度的引入使得key聚合最终到达sink的顺序变得不确定性。
更多更详细的并行度机制和配置可以在文档中找到https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/parallel.html
Windows
聚合事件的工作方式在实时和批量处理中工作方式不同。例如:在实时流中统计所有元素的个数是不可能的,因为流是无界的。然后,可以通过作用一个范围来统计聚合,比如:“统计最近五分钟的个数”,或者“计算最近100个元素的总和”。
窗口由时间或者数据来驱动,例如:“最近n分钟”,“最近n条数据”。窗口的分类有,滚动窗口没有重叠,滑动窗口有重叠,会话窗口被不活跃的间隙分开。

更多的案例可以在博客中看到https://flink.apache.org/news/2015/12/04/Introducing-windows.html,更加详细的文档请看https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/windows.html
Time
实时流的时间概念:
Event Time:事件时间就是在我们创造这条数据时候产生的时间,比如:用户登陆,那么用户点击登陆按钮时候产生的这个事件时间就是这个时间。
Ingestion time: 注入时间,也就是在进入flink的时候产生的时间,接数据源的时候。
Procession Time:处理时间,就是在每一个操作函数中处理元素的时候的本地时间。
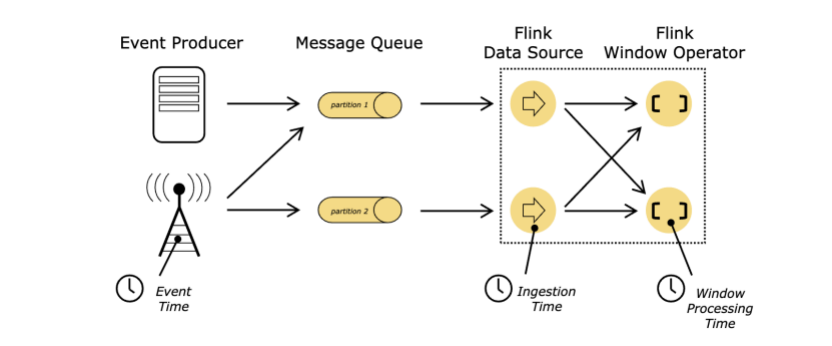
更多详细怎么处理时间见文档https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/event_time.html
Stateful Operations
虽然流中很多操作只操作一个独立的事件,但是一些操作可以计数跨事件的信息例如 窗口操作。这些操作被成为有状态。这些有状态的操作被维持在一个key/value形式的地方。状态和通过有状态操作读取的流被严格的分区和分配在一起,也就是一个分区下的流状态是一个。因此,通过key/value的状态依赖于key,通过keyby这种函数,key/value被分配到当前的事件key中。通过对齐流的key和状态我们可以确保所有状态更新都是本地操作,保证了一致性并没有事务开销。这个对齐可以允许flink重新分配状态和调整分区。更多信息:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/index.html

Checkpoints for Fault Tolerance
flink结合使用流回放和检查点来实现了容错机制。一个检查点涉及到了一个特殊的点在每一个数据流对应的状态和操作。一个数据流可以被恢复从一个检查点,同时通过恢复操作的状态和从检查点来回放事件从而来维护一致性。
检查点间隔是一种恢复时间来平衡执行期间的容错开销的方法。
内部容错机制(https://ci.apache.org/projects/flink/flink-docs-release-1.10/internals/stream_checkpointing.html)的描述提供了更多的信息关于flink如何管理检查点爱你和相关的主题。更详细的关于开启和配置检查点可见:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/checkpointing.html
Batch on Streaming
flink执行一个批处理程序作为一种特殊的流处理,这个流是有界的。DataSet作为内部流数据。上述概念应用于批量程序同样的方式与流实时程序,少数例外:
批量的容错不使用检查点。恢复数据就直接全量跑数据就可以。因为批量都是有界的数据。https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/task_failure_recovery.html
DataSet API中有状态的操作使用简单的内存或者内和外数据结构,而不是key/value 索引。(这个没太了解,后续如果在后续中发现了,会回来解释)
DataSet API 引用了特殊的同步迭代,只作用在有界的流中。详细信息可以参考https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/batch/iterations.html
Programming Model的更多相关文章
- Udacity并行计算课程笔记-The GPU Programming Model
一.传统的提高计算速度的方法 faster clocks (设置更快的时钟) more work over per clock cycle(每个时钟周期做更多的工作) more processors( ...
- .NET “底层”异步编程模式——异步编程模型(Asynchronous Programming Model,APM)
本文内容 异步编程类型 异步编程模型(APM) 参考资料 首先澄清,异步编程模式(Asynchronous Programming Patterns)与异步编程模型(Asynchronous Prog ...
- HttpWebRequest - Asynchronous Programming Model/Task.Factory.FromAsyc
Posted by Shiv Kumar on 23rd February, 2011 The Asynchronous Programming Model (or APM) has been aro ...
- 【Udacity并行计算课程笔记】- lesson 1 The GPU Programming Model
一.传统的提高计算速度的方法 faster clocks (设置更快的时钟) more work over per clock cycle(每个时钟周期做更多的工作) more processors( ...
- PatentTips - Heterogeneous Parallel Primitives Programming Model
BACKGROUND 1. Field of the Invention The present invention relates generally to a programming model ...
- Scalaz(54)- scalaz-stream: 函数式多线程编程模式-Free Streaming Programming Model
长久以来,函数式编程模式都被认为是一种学术研究用或教学实验用的编程模式.直到近几年由于大数据和多核CPU的兴起造成了函数式编程模式在一些实际大型应用中的出现,这才逐渐改变了人们对函数式编程无用论的观点 ...
- Algorithms 4th - 1.1 Basic Programming Model - CREATIVE PROBLEMS
欢迎交流 1.1.26 public class TestApp { public static void main(String[] args) { int a = StdIn.readInt(); ...
- Algorithms 4th - 1.1 Basic Programming Model - EXERCISES
欢迎交流 1.1.1 a. 7 b. 200.0000002 c. true 1.1.2 a. 1.618 b. 10.0 c. true d. 33 1.1.3 public class MainA ...
- Asynchronous Programming Model (APM)异步编程模型
https://msdn.microsoft.com/zh-cn/library/ms228963(v=vs.110).aspx 一.概念 An asynchronous operation that ...
随机推荐
- call 和 apply 的区别?哪个性能更好?
1.call 和 apply 都是 function 类 原型上的方法:每一个函数作为 function 的实例都能调用这两个方法:这两个方法执行的目的都是用来改变函数中 this 指向的,让函数执行 ...
- Java实现 蓝桥杯 算法训练 Balloons in a Box
试题 算法训练 Balloons in a Box 问题描述 你要写一个程序,使得能够模拟在长方体的盒子里放置球形的气球. 接下来是模拟的方案.假设你已知一个长方体的盒子和一个点集.每一个点代表一个可 ...
- (Java实现) 洛谷 P1028 数的计算
题目描述 我们要求找出具有下列性质数的个数(包含输入的自然数nn): 先输入一个自然数n(n≤1000),然后对此自然数按照如下方法进行处理: 不作任何处理; 在它的左边加上一个自然数,但该自然数不能 ...
- Java实现 蓝桥杯VIP 算法训练 邮票
算法训练 邮票 时间限制:1.0s 内存限制:512.0MB 问题描述 给定一个信封,有N(1≤N≤100)个位置可以贴邮票,每个位置只能贴一张邮票.我们现在有M(M<=100)种不同邮资的邮票 ...
- Java实现 蓝桥杯 算法提高 宰羊
试题 算法提高 宰羊 资源限制 时间限制:1.0s 内存限制:256.0MB 问题描述 炫炫回了内蒙,肯定要吃羊肉啦,所有他家要宰羊吃. 炫炫家有N只羊,羊圈排成一排,标号1~N.炫炫每天吃掉一只羊( ...
- Java实现 洛谷 P1010 幂次方
输入输出样例 输入 #1 1315 输出 #1 2(2(2+2(0))+2)+2(2(2+2(0)))+2(2(2)+2(0))+2+2(0) import java.util.Scanner; pu ...
- java实现第四届蓝桥杯公式求值
公式求值 输入n, m, k,输出图1所示的公式的值.其中C_n^m是组合数,表示在n个人的集合中选出m个人组成一个集合的方案数.组合数的计算公式如图2所示. 输入的第一行包含一个整数n:第二行包含一 ...
- Java多线程之深入解析ThreadLocal和ThreadLocalMap
ThreadLocal概述 ThreadLocal是线程变量,ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的.ThreadLocal为变量在每个线程中都创建了一个副本,那 ...
- FTP配置多用户多目录多权限
环境介绍 根据开发的需求 要求创建FTP服务器,把前端和后端分开用不同的FTP账号 系统环境 centos 7.4 selinux 关闭 防火墙关闭 安装FTP 很简单就一条命令 yum instal ...
- elementUI+国际化
1. 先创建一个lang 文件夹,创建两个js文件en.js(英文), zh.js(中文), 另外创建一个index.js文件(用于) en.js zh.js (两者必须保持一致) 2. 在index ...