吴裕雄--天生自然 PYTHON语言数据分析:ESA的火星快车操作数据集分析
import os
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('white') %matplotlib inline %load_ext autoreload
%autoreload 2
def to_utms(ut):
return (ut.astype(np.int64) * 1e-6).astype(int) def read_merged_train_and_test_data(file_name):
src_path = "F:\\kaggleDataSet\\hackathon-krakow\\hackathon-krakow-2017-05-27"
train_path = os.path.join(src_path, "context--2014-01-01_2015-01-01--" + file_name + ".csv")
train_df = pd.read_csv(train_path)
test_path = os.path.join(src_path, "context--2015-01-01_2015-07-01--" + file_name + ".csv")
test_df = pd.read_csv(test_path)
df = pd.concat([train_df, test_df]) return convert_timestamp_to_date(df) def convert_timestamp_to_date(df, timestamp_column="ut_ms"):
df[timestamp_column] = pd.to_datetime(df[timestamp_column], unit='ms')
df = df.set_index(timestamp_column)
df = df.dropna()
return df def parse_subsystems(dmop_data):
dmop_frame = dmop_data.copy()
dmop_frame = dmop_frame[dmop_frame["subsystem"].str.startswith("A")]
dmop_frame["device"] = dmop_frame["subsystem"].str[1:4]
dmop_frame["command"] = dmop_frame["subsystem"].str[4:]
dmop_frame = dmop_frame.drop("subsystem", axis=1)
return dmop_frame def generate_count_in_hour_from_raw_data(raw_data, column_name):
raw_frame = raw_data.copy()
raw_frame["timestamp_by_hour"] = raw_frame.index.map(lambda t: datetime(t.year, t.month, t.day, t.hour))
events_by_hour = raw_frame.groupby(["timestamp_by_hour", column_name]).agg("count")
events_by_hour = events_by_hour.reset_index()
events_by_hour.columns = ['timestamp_by_hour', column_name, 'count']
events_by_hour = events_by_hour.pivot(index="timestamp_by_hour", columns=column_name, values="count").fillna(0) events_by_hour.columns =["count_" + str(column_name) + "_in_hour" for column_name in events_by_hour.columns]
events_by_hour.index.names = ['ut_ms'] return events_by_hour def important_commands(dmop_data):
count_of_each_command = dmop_data["command"].value_counts()
important_commands = count_of_each_command[count_of_each_command > 2000]
return list(important_commands.index) def important_events(evtf_data):
count_of_each_event = evtf_data["description"].value_counts()
important_event_names = count_of_each_event[count_of_each_event > 1000]
return list(important_event_names.index)
dmop_raw = read_merged_train_and_test_data("dmop")
evtf_raw = read_merged_train_and_test_data("evtf")
ltdata_raw = read_merged_train_and_test_data("ltdata")
saaf_raw = read_merged_train_and_test_data("saaf")
power_train_raw = convert_timestamp_to_date(pd.read_csv("F:\\kaggleDataSet\\hackathon-krakow\\hackathon-krakow-2017-05-27\\power--2014-01-01_2015-01-01.csv"))
power_train_raw = power_train_raw.resample("1H").mean().dropna()
power_test_raw = convert_timestamp_to_date(pd.read_csv("F:\\kaggleDataSet\\hackathon-krakow\\hackathon-krakow-2017-05-27\\sample_power_zeros--2015-01-01_2015-07-01.csv"))
power_raw = pd.concat([power_train_raw, power_test_raw])
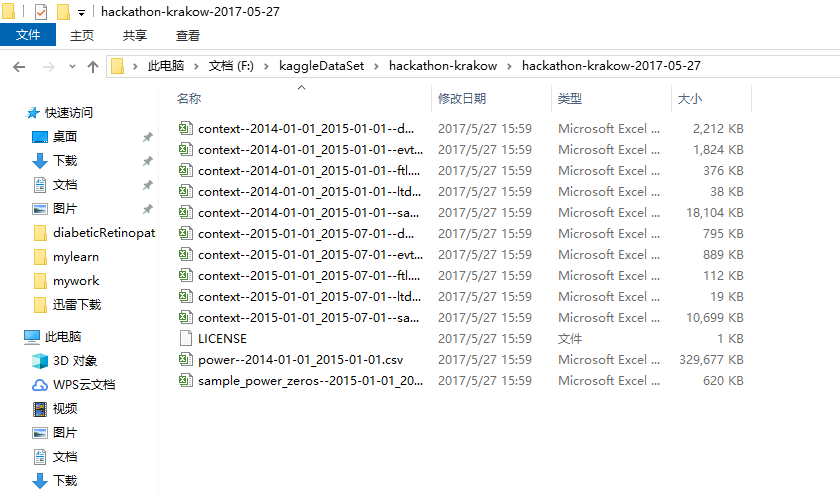
plt.figure(figsize=(20, 3))
power_raw_with_sum = power_train_raw.copy()
power_raw_with_sum["power_sum"] = power_raw_with_sum.sum(axis=1)
power_raw_with_sum["power_sum"].plot()
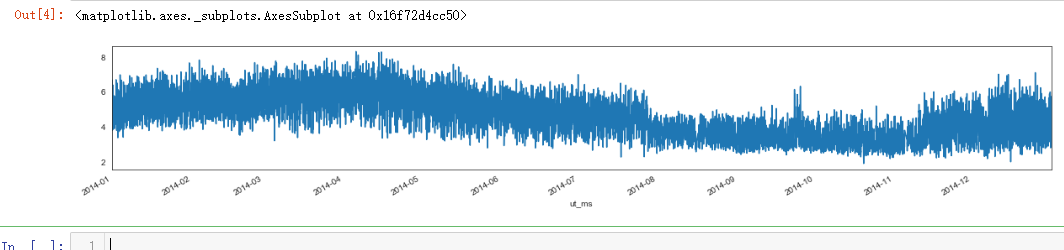
plt.figure(figsize=(20, 10))
plt.imshow(power_train_raw.values.T, aspect='auto', cmap="viridis")
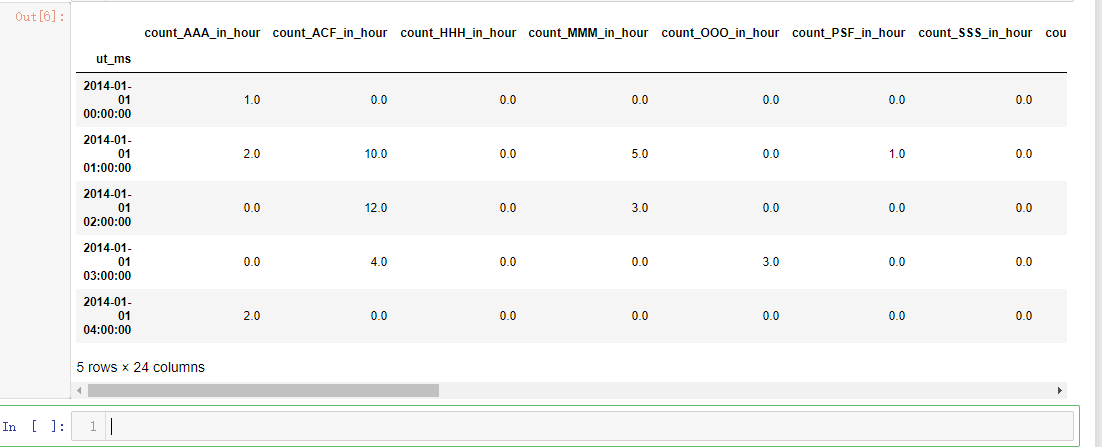
dmop_devices = parse_subsystems(dmop_raw) dmop_devive_commands_by_hour = generate_count_in_hour_from_raw_data(dmop_devices, "device")
dmop_devive_commands_by_hour["dmop_sum"] = dmop_devive_commands_by_hour.sum(axis=1) dmop_commands_by_hour = generate_count_in_hour_from_raw_data(dmop_devices, "command")
important_command_names = important_commands(dmop_devices)
important_command_names = list(map(lambda x: "count_" + x + "_in_hour", important_command_names))
dmop_commands_by_hour = dmop_commands_by_hour[important_command_names] dmop_data_per_hour = pd.concat([dmop_devive_commands_by_hour, dmop_commands_by_hour], axis=1)
dmop_data_per_hour.head()
plt.figure(figsize=(20, 10))
dmop_devive_commands_by_hour["dmop_sum"].plot()
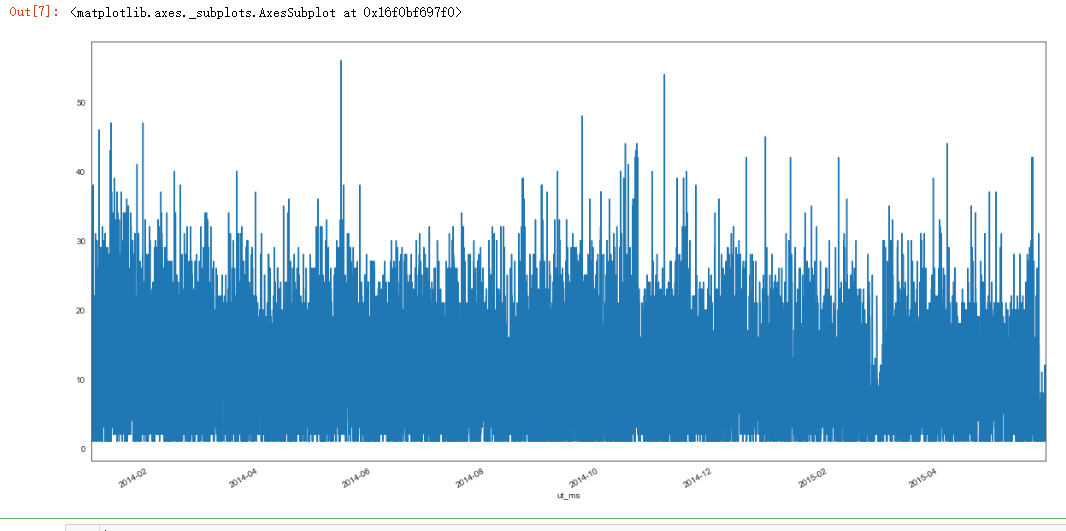
dmop_data = dmop_data_per_hour.reindex(power_raw_with_sum.index, method="nearest")
dmop_with_power_data = pd.concat([power_raw_with_sum, dmop_data], axis=1)
dmop_with_power_data.columns
sns.jointplot("dmop_sum", "power_sum", dmop_with_power_data)

dmop_with_power_data = dmop_with_power_data.resample("24h").mean()
sns.pairplot(dmop_with_power_data, x_vars=dmop_commands_by_hour.columns[0:6], y_vars="power_sum")
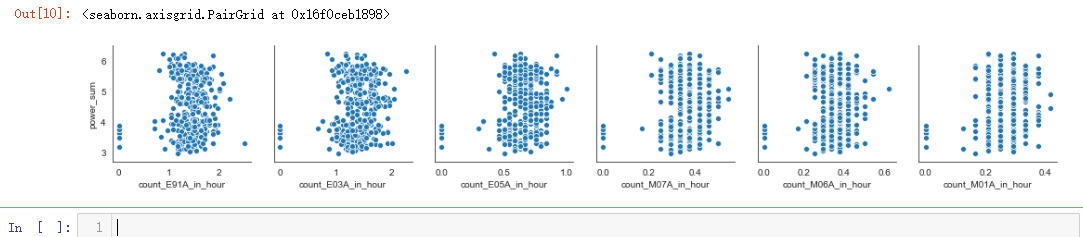
sns.pairplot(dmop_with_power_data, x_vars=dmop_commands_by_hour.columns[0:6], y_vars=power_raw.columns[0:6])
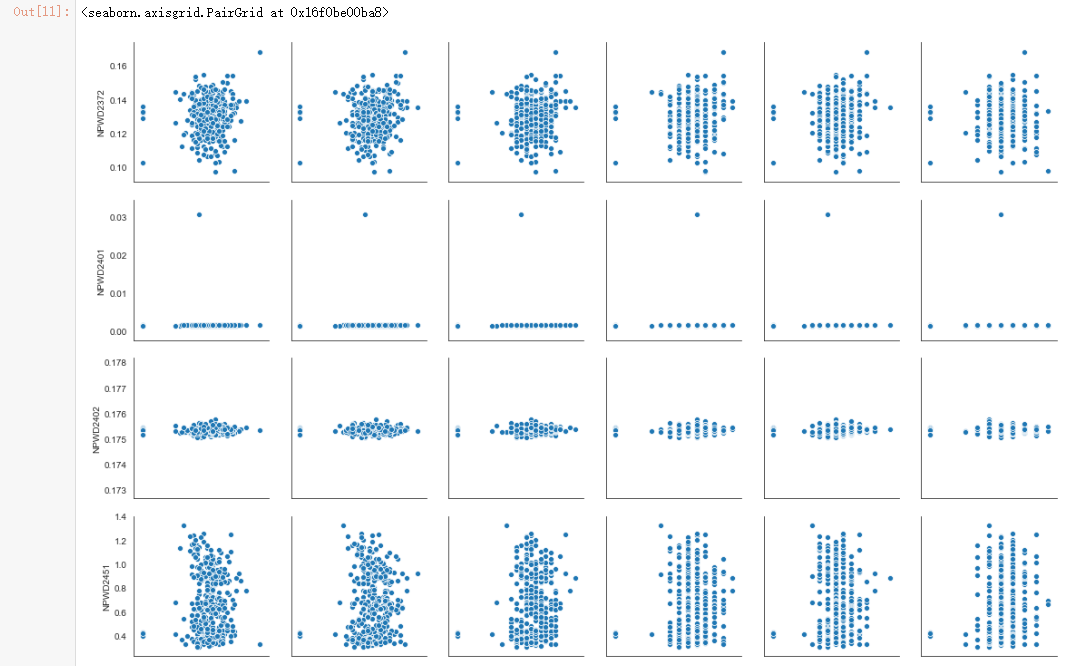
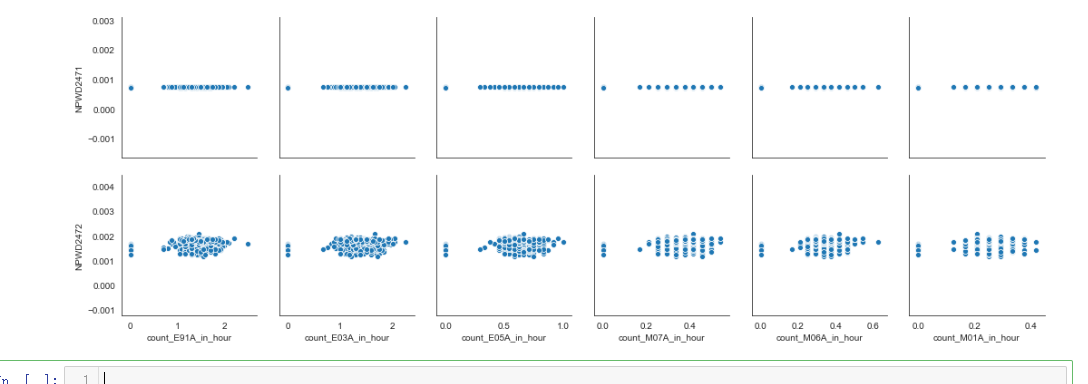
important_event_names = list(filter(lambda name: (not("_START" in name) and not("_END" in name)), important_events(evtf_raw)))
important_evtf = evtf_raw[evtf_raw["description"].isin(important_event_names)]
important_evtf["description"].value_counts()
important_evtf_with_count = important_evtf.copy()
important_evtf_with_count["count"] = 1
important_evtf_data_per_hour = generate_count_in_hour_from_raw_data(important_evtf_with_count, "description")
important_evtf_data_per_hour.head()
evtf_data = important_evtf_data_per_hour.reindex(power_raw_with_sum.index, method="nearest")
evtf_with_power_data = pd.concat([power_raw_with_sum, evtf_data])
evtf_with_power_data.columns

evtf_with_power_data = evtf_with_power_data.resample("24h").mean()
sns.pairplot(evtf_with_power_data, x_vars=important_evtf_data_per_hour.columns[0:6], y_vars="power_sum")
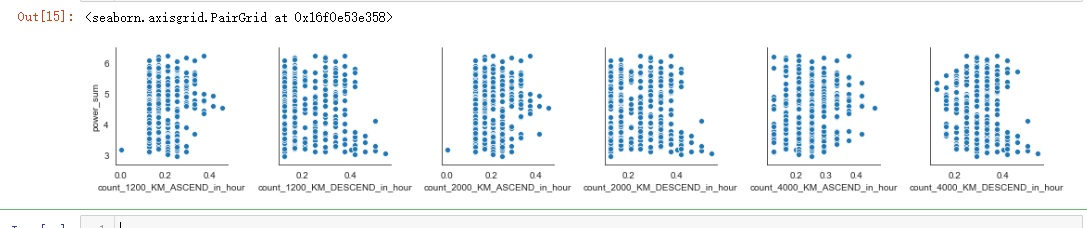
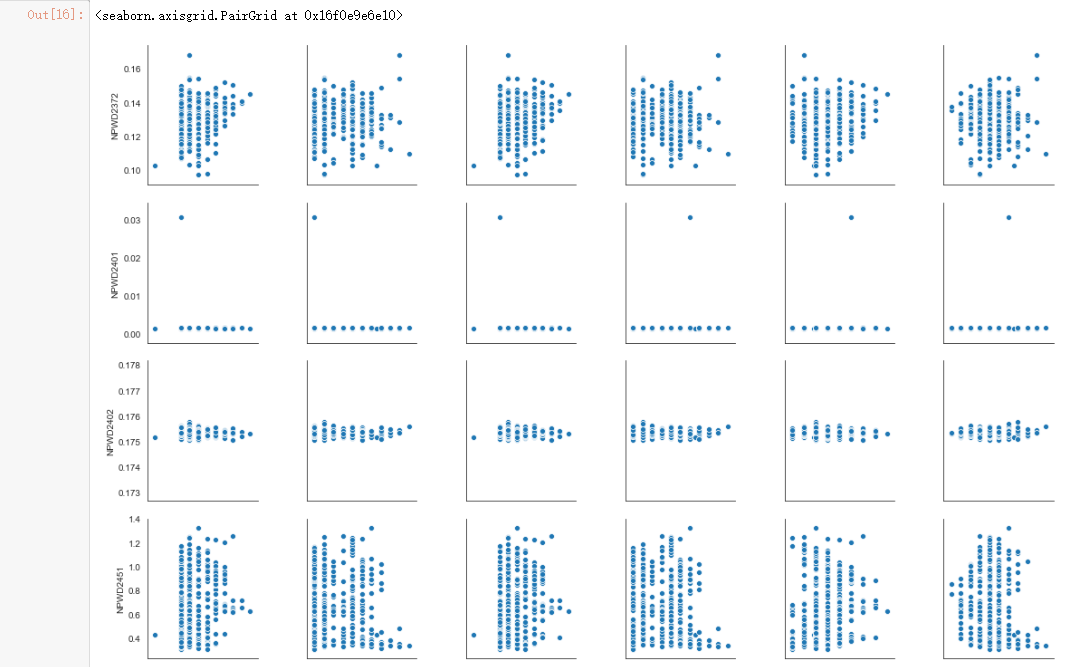
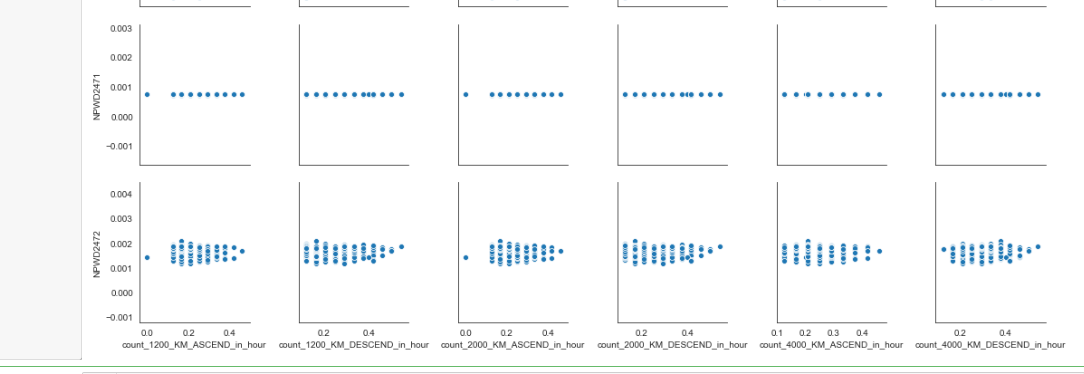
sns.pairplot(evtf_with_power_data, x_vars=important_evtf_data_per_hour.columns[0:6], y_vars=power_raw.columns[0:6])
def is_start_event(description, event_type):
return int((event_type in description) and ("START" in description))
msl_events = ["MSL_/_RANGE_06000KM_START", "MSL_/_RANGE_06000KM_END"]
mrb_events = ["MRB_/_RANGE_06000KM_START", "MRB_/_RANGE_06000KM_END"]
penumbra_events = ["MAR_PENUMBRA_START", "MAR_PENUMBRA_END"]
umbra_events = ["MAR_UMBRA_START", "MAR_UMBRA_END"] msl_events_df = evtf_raw[evtf_raw["description"].isin(msl_events)].copy()
msl_events_df["in_msl"] = msl_events_df["description"].map(lambda row: is_start_event(row, "MSL"))
msl_events_df = msl_events_df["in_msl"] mrb_events_df = evtf_raw[evtf_raw["description"].isin(mrb_events)].copy()
mrb_events_df["in_mrb"] = mrb_events_df["description"].map(lambda row: is_start_event(row, "MRB"))
mrb_events_df = mrb_events_df["in_mrb"] penumbra_events_df = evtf_raw[evtf_raw["description"].isin(penumbra_events)].copy()
penumbra_events_df["in_penumbra"] = penumbra_events_df["description"].map(lambda row: is_start_event(row, "PENUMBRA"))
penumbra_events_df = penumbra_events_df["in_penumbra"] umbra_events_df = evtf_raw[evtf_raw["description"].isin(umbra_events)].copy()
umbra_events_df["in_umbra"] = umbra_events_df["description"].map(lambda row: is_start_event(row, "UMBRA"))
umbra_events_df = umbra_events_df["in_umbra"]
ltdata_raw.columns

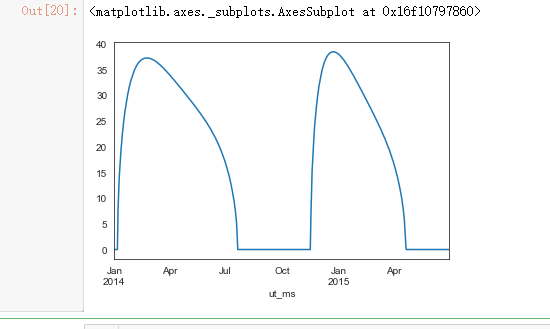
ltdata_raw["eclipseduration_min"].plot()
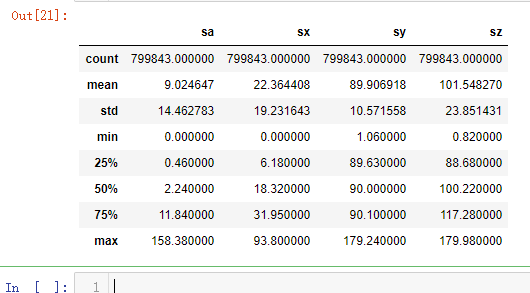
saaf_raw.describe()
dmop_data = dmop_data_per_hour.reindex(power_raw.index, method="nearest")
evtf_events_data = important_evtf_data_per_hour.reindex(power_raw.index, method="nearest")
msl_period_events_data = msl_events_df.reindex(power_raw.index, method="pad").fillna(0)
mrb_period_events_data = mrb_events_df.reindex(power_raw.index, method="pad").fillna(0)
penumbra_period_events_data = penumbra_events_df.reindex(power_raw.index, method="pad").fillna(0)
umbra_period_events_data = umbra_events_df.reindex(power_raw.index, method="pad").fillna(0)
ltdata_data = ltdata_raw.reindex(power_raw.index, method="nearest")
saaf_data = saaf_raw.reindex(power_raw.index, method="nearest")
all_data = pd.concat([power_raw, dmop_data, evtf_events_data, msl_period_events_data, mrb_period_events_data, penumbra_period_events_data, umbra_period_events_data, ltdata_data, saaf_data], axis=1)
print(all_data.columns, all_data.shape)

plt.figure(figsize=(20, 10))
plt.imshow(all_data.values.T, aspect='auto', vmin=0, vmax=5, cmap="viridis")

train_set_start_date, train_set_end_date = power_train_raw.index[0], power_train_raw.index[-1]
train_data = all_data[all_data.index <= train_set_end_date].copy()
test_data = all_data.loc[power_test_raw.index].copy()
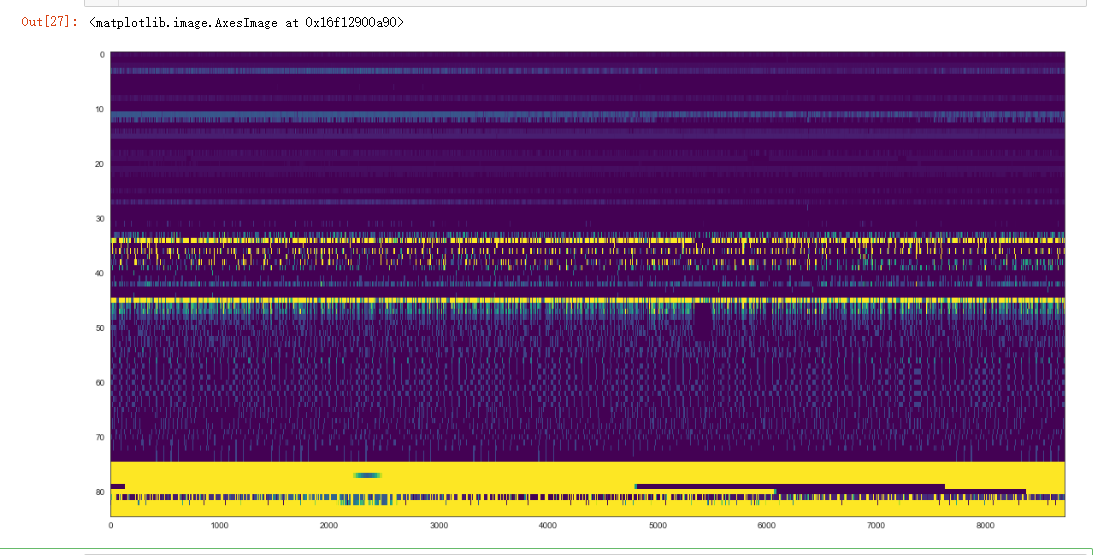
plt.figure(figsize=(20, 10))
plt.imshow(train_data.values.T, aspect='auto', vmin=0, vmax=5, cmap="viridis")
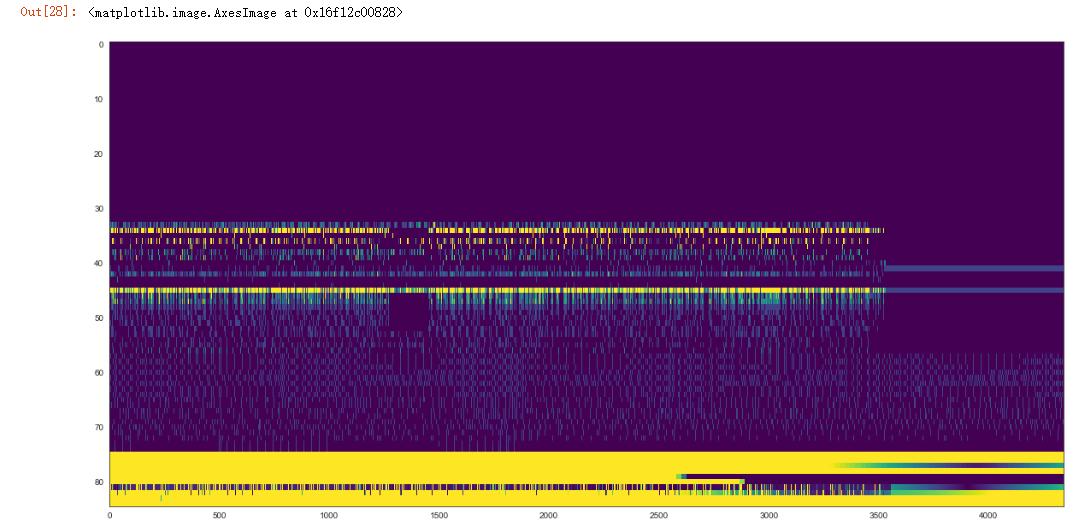
plt.figure(figsize=(20, 10))
plt.imshow(test_data.values.T, aspect='auto', vmin=0, vmax=5, cmap="viridis")
X_train = train_data[train_data.columns.difference(power_raw.columns)]
y_train = train_data[power_raw.columns]
from sklearn.model_selection import train_test_split X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=0.3, random_state=0)
from sklearn import linear_model
from sklearn.metrics import mean_squared_error
reg = linear_model.LinearRegression()
reg.fit(X_train, y_train)
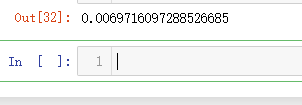
y_validation_predicted = reg.predict(X_validation)
mean_squared_error(y_validation, y_validation_predicted)
elastic_net = linear_model.ElasticNet()
elastic_net.fit(X_train, y_train)
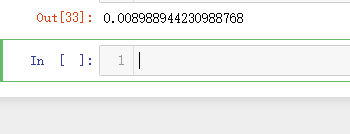
y_validation_predicted = elastic_net.predict(X_validation)
mean_squared_error(y_validation, y_validation_predicted)
吴裕雄--天生自然 PYTHON语言数据分析:ESA的火星快车操作数据集分析的更多相关文章
- 吴裕雄--天生自然 python语言数据分析:开普勒系外行星搜索结果分析
import pandas as pd pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]}) pd.DataFrame({'Bob': ['I liked i ...
- 吴裕雄--天生自然 R语言数据分析:火箭发射的地点、日期/时间和结果分析
dfS = read.csv("F:\\kaggleDataSet\\spacex-missions\\database.csv") library(dplyr) library( ...
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- 吴裕雄--天生自然python学习笔记:pandas模块强大的数据处理套件
用 Python 进行数据分析处理,其中最炫酷的就属 Pa ndas 套件了 . 比如,如果我 们通过 Requests 及 Beautifulsoup 来抓取网页中的表格数据 , 需要进行较复 杂的 ...
- 吴裕雄--天生自然python学习笔记:Python3 正则表达式
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参 ...
- 吴裕雄--天生自然python学习笔记:Python3 命名空间和作用域
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的. 命名空间提供了在项目中避免名字冲突的一种方法.各个命名空间是独立的,没有任何关系的,所以一个 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(1)
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行 ...
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
随机推荐
- 关于电脑识别不出自己画的板子上的USB接口问题
现在在画一个Cortex-A5的底板,现在已经完成,正在测试各个模块,发现USB插上后,电脑提示报错,如下: 网上查了很多,有的说是配置问题,有的说是走线问题,首先配置肯定没问题,因为同一台电脑,在买 ...
- 1016D.Vasya And The Matrix#矩阵存在
题目出处:http://codeforces.com/contest/1016/problem/D #include<iostream> #define ll long long int ...
- webpack--删除dist目录
1.安装clean-webpack-plugin插件 npm install clean-webpack-plugin --D 2.在webpack.dev.conf.js或者webpack.conf ...
- flutter 命令卡主的问题
情况 1 镜像的问题 如果你的镜像已经设置,却仍然卡主,那么请参考情况 2 这种情况在中文官网上已经有了,并且有这修改镜像的方法,附上链接: https://flutter.cn/community/ ...
- anaconda学习笔记
anaconda介绍 Anaconda指的是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项. Conda是一个开源的包.环境管理器,可以用于在同一个机器上 ...
- 吴裕雄--天生自然 PYTHON3开发学习:循环语句
n = 100 sum = 0 counter = 1 while counter <= n: sum = sum + counter counter += 1 print("1 到 ...
- Educational Codeforces Round 76 (Rated for Div. 2)E(dp||贪心||题解写法)
题:https://codeforces.com/contest/1257/problem/E 题意:给定3个数组,可行操作:每个数都可以跳到另外俩个数组中去,实行多步操作后使三个数组拼接起来形成升序 ...
- Qt QString 和 LPCWSTR 的相互转换
在windosw 编程中,常用到LPCWSTR 变量,QT中最常用到QString,下面提供QString和LPCWSTR 相互转换的方法 LPWSTR 转换成QString LPCWSTR str; ...
- Java基础的坑
仍会出现NPE 需要改成
- VMware-workstation虚拟机安装及配置
目录 安装准备 开始安装 设置虚拟机文件默认位置 安装准备 系统环境:Windows10 专业版 软件:VMware-workstation-full-14.0.0.24051.exe 秘钥:FF31 ...