2、flink入门程序Wordcount和sql实现
一、DataStream Wordcount
基于scala实现
maven依赖如下:
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- flink的hadoop兼容 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop2</artifactId>
<version>1.7.2</version>
</dependency>
<!-- flink的hadoop兼容 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink的scala的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink streaming的scala的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink的java的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink streaming的java的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink 的kafkaconnector -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 使用rocksdb保存flink的state -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink操作hbase -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hbase_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink运行时的webUI -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- flink table -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- mysql连接驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
</dependencies>
具体代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.util.Collector object SocketWordCount {
def main(args: Array[String]): Unit = {
val logPath: String = "/tmp/logs/flink_log" // 生成配置对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
// 定义socket 源
val socket: DataStream[String] = env.socketTextStream("localhost", 6666)
//scala开发需要加一行隐式转换,否则在调用operator的时候会报错
import org.apache.flink.api.scala._
// 定义 operators 解析数据,求Wordcount
val wordCount: DataStream[(String, Int)] = socket.flatMap(_.split(" ")).map((_, 1)).keyBy(_._1).sum(1)
//使用FlatMapFunction自定义函数来完成flatMap和map的组合功能
val wordCount2: DataStream[(String, Int)] = socket.flatMap(new FlatMapFunction[String, (String, Int)] {
override def flatMap(int: String, out: Collector[(String, Int)]): Unit = {
val strings: Array[String] = int.split(" ")
for (str <- strings) {
out.collect((str, 1))
}
}
}).setParallelism(2)
.keyBy(_._1).sum(1).setParallelism(2) // 打印结果
wordCount.print() // 定义任务的名称并运行,operator是惰性的,只有遇到execute才运行
env.execute("SocketWordCount")
}
}
二、flink table & sql Wordcount
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.configuration.{ConfigConstants, Configuration}
import org.apache.flink.table.api.Table
import org.apache.flink.table.api.scala.BatchTableEnvironment
import scala.collection.mutable.ArrayBuffer
/**
* @author xiandongxie
*/
object WordCountSql extends App {
val logPath: String = "/tmp/logs/flink_log"
// 生成配置对象
var conf: Configuration = new Configuration()
// 开启flink web UI
conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true)
// 配置web UI的日志文件,否则打印日志到控制台
conf.setString("web.log.path", logPath)
// 配置taskManager的日志文件,否则打印到控制台
conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, logPath)
// 获取local运行环境
val env: ExecutionEnvironment = ExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
//创建一个tableEnvironment
val tableEnv: BatchTableEnvironment = BatchTableEnvironment.create(env)
val words: String = "hello flink hello xxd"
val strings: Array[String] = words.split("\\W+")
val arrayBuffer = new ArrayBuffer[WordCount]()
for (f <- strings) {
arrayBuffer.append(new WordCount(f, 1))
}
val dataSet: DataSet[WordCount] = env.fromCollection(arrayBuffer)
//DataSet 转sql
val table: Table = tableEnv.fromDataSet(dataSet)
table.printSchema()
// 注册为一个表
tableEnv.createTemporaryView("WordCount", table)
// 查询
val selectTable: Table = tableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount GROUP BY word")
// 查询结果转为dataset,输出
val value: DataSet[WordCount] = tableEnv.toDataSet[WordCount](selectTable)
value.print()
}
/**
* 样例类
* @param word
* @param frequency
*/
case class WordCount(word: String, frequency: Long) {
override def toString: String = {
word + "\t" + frequency
}
}
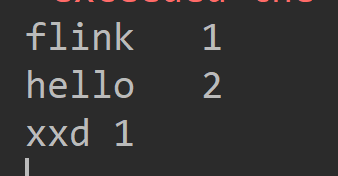
结果:
2、flink入门程序Wordcount和sql实现的更多相关文章
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
我们右键运行时相当于在本地启动了一个单机版本.生产中都是集群环境,并且是高可用的,生产上提交任务需要用到flink run 命令,指定必要的参数. 本课时我们主要介绍 Flink 的入门程序以及 SQ ...
- Hadoop入门程序WordCount的执行过程
首先编写WordCount.java源文件,分别通过map和reduce方法统计文本中每个单词出现的次数,然后按照字母的顺序排列输出, Map过程首先是多个map并行提取多个句子里面的单词然后分别列出 ...
- 零基础学习java------36---------xml,MyBatis,入门程序,CURD练习(#{}和${}区别,模糊查询,添加本地约束文件) 全局配置文件中常用属性 动态Sql(掌握)
一. xml 1. 文档的声明 2. 文档的约束,规定了当前文件中有的标签(属性),并且规定了标签层级关系 其叫html文档而言,语法要求更严格,标签成对出现(不是的话会报错) 3. 作用:数据格式 ...
- 从flink-example分析flink组件(1)WordCount batch实战及源码分析
上一章<windows下flink示例程序的执行> 简单介绍了一下flink在windows下如何通过flink-webui运行已经打包完成的示例程序(jar),那么我们为什么要使用fli ...
- flink入门实战总结
随着大数据技术在各行各业的广泛应用,要求能对海量数据进行实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理方式和早期的流式处理框架也越来越难以在延迟性.吞吐量.容错能力以及使用便 ...
- Flink入门宝典(详细截图版)
本文基于java构建Flink1.9版本入门程序,需要Maven 3.0.4 和 Java 8 以上版本.需要安装Netcat进行简单调试. 这里简述安装过程,并使用IDEA进行开发一个简单流处理程序 ...
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- Flink入门(三)——环境与部署
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群 ...
- Flink入门(四)——编程模型
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink的编程模型. 数据集类型: 无穷数据集:无穷的持续集成的数据集合 有界数据集:有 ...
随机推荐
- vue-父组件传递参数到子组件
案例: 父组件 <template> <div id="app"> <h1>vuex</h1> <h3>count:{{ ...
- 浅谈C#中Tuple和Func的使用
为什么将Tuple和Func混合起来谈呢? 首先,介绍一下:Tuple叫做元组,是.Net Framwork4.0引入的数据类型,用来返回多个数值.在C# 4.0之前我们函数有多个返回值,通常是使用r ...
- 实战级Stand-Alone Self-Attention in CV,快加入到你的trick包吧 | NeurIPS 2019
论文提出stand-alone self-attention layer,并且构建了full attention model,验证了content-based的相互关系能够作为视觉模型特征提取的主要基 ...
- javascript实现组合列表框中元素移动效果
应用背景:在页面中有两个列表框,需要把其中一个列表框的元素移动到另一个列表框 . 实现的基本思想: (1)编写init方法对两个列表框进行初始化: (2)为body添加onload事件调用init方 ...
- B 基因改造
时间限制 : - MS 空间限制 : - KB 问题描述 "人类智慧的冰峰,只有萌萌哒的我寂寞地守望."--TBTB正走在改造人类智慧基因的路上.TB发现人类智慧基因一点也不 ...
- 关于 Vue 中 我对中央事线管理器的(enentBus)误解
由于这段时间公司比较闲,就对vue 中的一些模糊的点做了一些加强,突然就想到了常挂在嘴边兄弟组件传值 我理解的兄弟组件的传值是可以跨理由传值的,比如我从http://localhost:8080/lo ...
- SpringAOP入门
Spring的AOP aop概述 Aspect Oriented Programing 面向切面(方面)编程, aop:扩展功能不修改源代码实现 aop采取横向抽取机制,取代了传统纵向继承体系重复性代 ...
- 从String 聊源码解读
@ 目录 源码实现 构造方法 equals 其他方法 常见面试题 你真的了解String吗?之前一篇博客写jvm时,就觉得String可以单独拎出来写一篇博客,毕竟几乎所有的面试都是以String开始 ...
- C语言 文件操作(五)
(1)size_t fread ( void * ptr, size_t size, size_t count, FILE * stream ); 其中,ptr:指向保存结果的指针:size:每个数据 ...
- javascript入门 之 ztree(四 自定义Icon)
<!DOCTYPE html> <HTML> <HEAD> <TITLE> ZTREE DEMO - Standard Data </TITLE& ...