【面试QA】Attention
Attention机制的原理
- 关键的三个变量 Query, Key, Value,计算 Attention 的过程即使用一个 Query,对所有的 Key 计算相似度,然后根据相似度对 Value 进行加权求和
Attention机制的类别
Hard/Soft Attention:Soft Attention是利用注意力分数加权和的方法得到注意力表征,即传统的 Attention 计算。而 Hard Attention 则是一个随机过程,将将注意力分数当作采样概率,对 Value 进行采样,采样过程是无法求导的(即 Soft/Hard 的区别)
Local/Globel Attention:区别在于 Local Attention 需要定义一个窗口,最后只加权窗口之内的词信息,而 Globel Attention 则是关注整个上下文的信息。
一维匹配/二维匹配:一维匹配模型指的是 Query 直接表征为一个一维向量,注意力分数即为 Query 对 Key 中每个词的注意力分数,这个注意力关系是一个一维匹配的关系;而二维匹配模型则是可以看作有多个 Query 与多个 Key 计算相关分数,是一个 N2N 的二维匹配关系。
双向注意力
- 双向注意力模型即在求得二维匹配矩阵之后,在两个不同方向上的 Softmax 归一化即为两个不同方向上的注意力分数,再利用注意力分数对相应的注意力对象加权即可,得到 context-to-query attention 表征以及 query-to-context atteniton 表征,再通过拼接的方式将其整合为上下文的 query-aware 表征。
Self-Attention 与 Soft-Attention 的区别
- Soft-Attention 中的 Key 和 Query 为不同值,而 Self-Attention 中的 Key, Query 和 Value 为同一个值经过不同的线性变换的
Transformer

Multi-Head Attention 机制
- 多个 Self-Attention 并行堆叠在一起实现多头注意力模型。
- 并行堆叠的意义:通过初始化不同的线性映射矩阵,使得不同的 Self-Attention 能够聚焦在不同的位置,保证最后输出的多个表征具有多方面的自注意力信息。最后将多个 Self-Attention 的输出在词向量维度上拼接,通过一个线性映射将其压缩到原来的词表征维度。
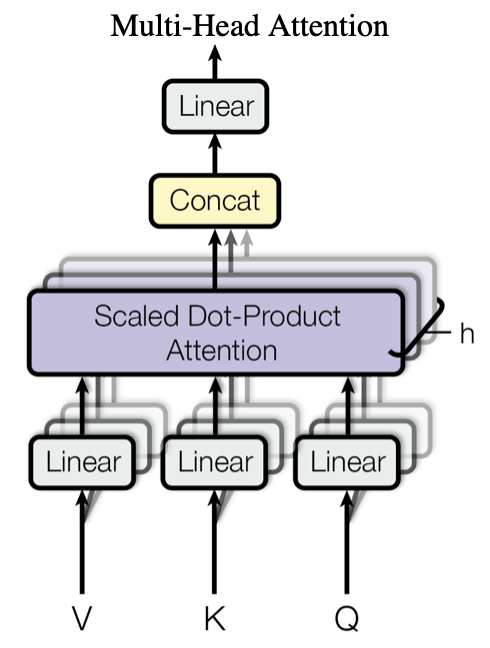
Self-Attention机制
- 输入的 Key、Query 和 Value 向量均为输入序列的线性映射,计算 Key 和 Query 的注意力分数再对 Value 进行注意力加权,实际上是一个对序列自身的注意力加权编码机制
\]

Position-wise Feed-Forward Layer
- Feed-Forward Layer 的作用就是将 Multi-Head Attention 输出的向量再投影到一个更大的空间,最后再投影回token向量原来的空间,便于在高维空间中提取需要的信息,激活函数使用ReLU
使用残差连接的部分
- Multi-Head Attention 前后和 Fead Forward 前后
- 残差连接之后还需要进行 Layer Normalization 进行归一化
Transformer Decoder 与 Encoder 之间的区别
- Transformer Decoder Block的结构与Encode Block略有不同,就是在Multi-Head Attention 之前额外添加了一个Masked Multi-Head Attention。
- Masked Attention,就是为了在解码过程中防止句子看到当前解码对象之后的序列,仅须对二维匹配注意力分数矩阵乘上一个下三角矩阵 \(M\) 即可,表明每一个时刻仅能看到过去时刻的解码输出
\]
位置编码
- 在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
- 这样的编码方式包含了相对位置信息,位置为pos+k的词可以由位置为pos和k的词来表示,且可以证明:间隔为k的任意两个位置编码的欧式空间距离是恒等的,只与k有关
PE_{2i}(p)=sin(p/10000^{2i/d_{pos}}) \\
PE_{2i+1}(p)=cos(p/10000^{2i/d_{pos}})
\end{cases}\]
- 相对位置的表示主要与下面的正余弦公式有关
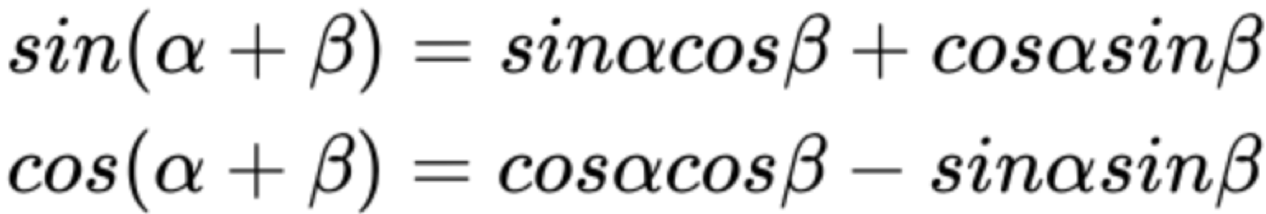
- 因此,可以将 \(PE_{pos}\) 和 \(PE_{pos+k}\) 的关系表示如下:
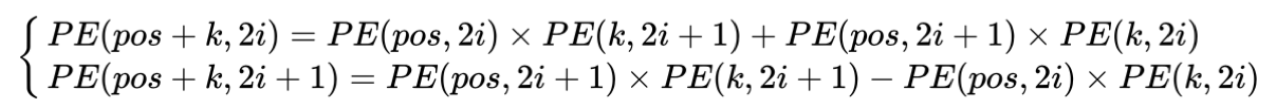
【面试QA】Attention的更多相关文章
- 如何面试QA(面试官角度)
面试是一对一 或者多对一的沟通,是和候选人 互相交换信息.平等的. 面试的目标是选择和雇佣最适合的人选.是为了完成组织目标.协助人力判断候选人是否合适空缺职位. 面试类型: (1)预判面试(查看简历后 ...
- 【NLP面试QA】预训练模型
目录 自回归语言模型与自编码语言 Bert Bert 中的预训练任务 Masked Language Model Next Sentence Prediction Bert 的 Embedding B ...
- 【NLP面试QA】基本策略
目录 防止过拟合的方法 什么是梯度消失和梯度爆炸?如何解决? 在深度学习中,网络层数增多会伴随哪些问题,怎么解决? 关于模型参数 模型参数初始化的方法 模型参数初始化为 0.过大.过小会怎样? 为什么 ...
- 【NLP面试QA】激活函数与损失函数
目录 Sigmoid 函数的优缺点是什么 ReLU的优缺点 什么是交叉熵 为什么分类问题的损失函数为交叉熵而不能是 MSE? 多分类问题中,使用 sigmoid 和 softmax 作为最后一层激活函 ...
- 机器阅读理解(看各类QA模型与花式Attention)
目录 简介 经典模型概述 Model 1: Attentive Reader and Impatient Reader Model 2: Attentive Sum Reader Model 3: S ...
- 机器阅读理解(看各类QA模型与花式Attention)(转载)
目录 简介 经典模型概述 Model 1: Attentive Reader and Impatient Reader Attentive Reader Impatient Reader Model ...
- PHP面试题目搜集
搜集这些题目是想在学习PHP方面知识有更感性的认识,单纯看书的话会很容易看后就忘记. 曾经看过数据结构.设计模式.HTTP等方面的书籍,但是基本看完后就是看完了,没有然后了,随着时间的推移,也就渐渐忘 ...
- .NET面试题目
简单介绍下ADO.NET和ADO主要有什么改进? 答:ADO以Recordset存储,而ADO.NET则以DataSet表示,ADO.NET提供了数据集和数据适配器,有利于实现分布式处理,降低了对数据 ...
- C语言面试
最全的C语言试题总结 第一部分:基本概念及其它问答题 1.关键字static的作用是什么? 这个简单的问题很少有人能回答完全.在C语言中,关键字static有三个明显的作用: 1). 在函数体,一个被 ...
随机推荐
- Win10+GTX906M+Tensorflow-gpu==2.1.0
环境 Windows10 GeForce GTX 960M python 3.7.6 tensorflow-gpu==2.1.0 CUDA 10.2 cuDNN v7.9.4.38 for windo ...
- 【转】Android Monkey 命令行可用的全部选项
常规 事件 约束限制 调试 原文参见:http://www.douban.com/note/257030384/ 常规 –help 列出简单的用法. -v 命令行的每一个 -v 将增加反馈信息的级别. ...
- 初识Machine Learning
What is Machine Learning 定义 Arthur Samuel:Field of study that gives computers the ability to learn w ...
- iOS自建分发
1.首先满足具有https证书的域名和空间.2.通常使用github或者国内第三方托管平台.3.上传ipa文件到空间内,获取ipa文件的下载地址.4.然后编辑plist文件(注意:ipa文件和plis ...
- Linux 信号介绍
是内容受限时的一种异步通信机制 首先是用来通信的 是异步的 本质上是 int 型的数字编号,早期Unix系统只定义了32种信号,Ret hat7.2支持64种信号,编号0-63(SIGRTMIN=31 ...
- 利用canvas绘画二级树形结构图
上周需要做一个把页面左侧列表内容拖拽到右侧区域,并且绘制成关系树的功能.看了设计图,第一反应是用canvas绘制关系线.吭哧吭哧搞定这个功能后,发现用canvas绘图,有一个很严重的缺陷.那就是如果左 ...
- OpenFlow(OVS)下的“路由技术”
前言 熟悉这款设备的同学,应该也快到不惑之年了吧!这应该是Cisco最古老的路由器了.上个世纪80年代至今,路由交换技术不断发展,但是在这波澜壮阔的变化之中,总有一些东西在嘈杂的机房内闪闪发光,像极了 ...
- CSS+DIV自适应布局
CSS+DIV自适应布局 1.两列布局(左右两侧,左侧固定宽度200px;右侧自适应占满) 代码如下: <!doctype html> <html> <head> ...
- 【30分钟学完】canvas动画|游戏基础(4):边界与碰撞
前言 本系列前几篇中常出现物体跑到画布外的情况,本篇就是为了解决这个问题. 阅读本篇前请先打好前面的基础. 本人能力有限,欢迎牛人共同讨论,批评指正. 越界检测 假定物体是个圆形,如图其圆心坐标即是物 ...
- Spring Cloud Feign 优雅的服务调用
Fegin 是由NetFlix开发的声明式.模板化HTTP客户端,可用于SpringCloud 的服务调用.提供了一套更优雅.便捷的HTTP调用API,并且SpringCloud整合了Fegin.Eu ...