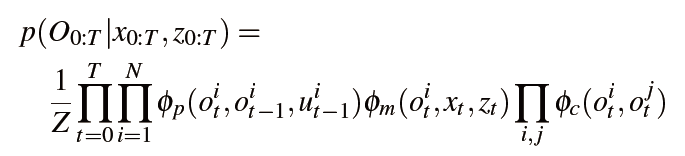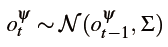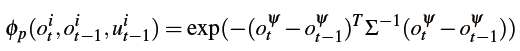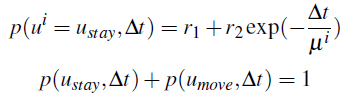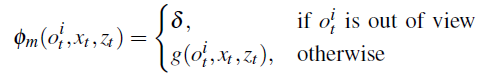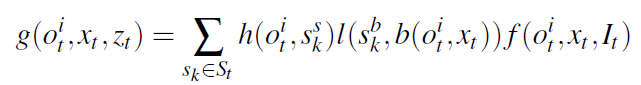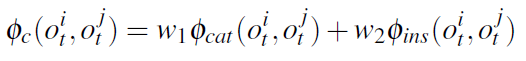论文地址:https://arxiv.org/abs/1810.11525
论文视频:https://www.youtube.com/watch?v=W-6ViSlrrZgwww.youtube.com
简介
作者提出同时进行目标检测和位姿估计,利用一段连续的图像帧,这个图像帧和slam不同之处在于它是对一个场景的扫描,运动的幅度可能很小,就在一个场景附近各个角度扫的一段图形序列,然后在机器人运动的时候通过ORBSLAM定位机器人自己的位置,利用faster-rcnn对物体进行目标检测,通过粒子滤波进行物体的位姿估计,使用提出的CT-Map方法来对检测结果进行纠正,得到更准确的检测结果和物体的位姿。
目标
使机器人能够在物体层面上对世界进行语义映射,其中世界的表示是对物体类别和位姿的置信度。随着神经网络物体检测的不断进步,作者为语义映射提供了更强大的构建模块。然而,由于训练数据集的偏差和多样性不足,这种物体检测在野外经常是嘈杂的。并且对来自此类网络的错误检测保持鲁棒性。作者将物体类别建模为生成推理的隐藏状态的一部分,而不是对检测器给出的类标签做出选择。
考虑到运动式RGB-D观测,作者的目标是推断解释观测结果的物体类别和位姿,同时考虑物体之间的上下文关系和物体位姿的时间一致性。在语义映射期间显式地建模物体-物体上下文关系,而不是假设每个物体在环境中是独立的。简单来说就是相同类别的物体比不同类别的物体更容易共同出现。此外,应加强物理合理性,以防止物体相互交叉,以及漂浮在空中。
物体位姿的时间一致性在语义映射中也起着重要作用。物体可以保留在过去观察的位置,或者随着时间的推移逐渐改变它们的语义位置。在遮挡的情况下,建模时间一致性可能有助于部分观察物体的定位。通过时间一致性建模,机器人可以获得物体永久性的概念,例如,即使没有直接观察物体,也相信物体仍然存在。
创新点
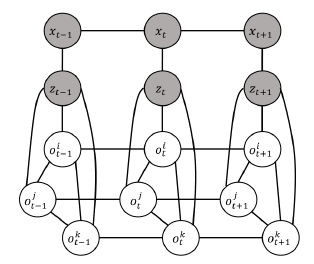
考虑到语义映射中的环境和时间因素,作者提出了环境时间映射(CT-MAP)方法来同时检测物体并通过运动的RGB-D相机观测定位它们的6D位姿。将语义映射问题利用概率表示为物体类别和位姿的置信度估计问题。使用条件随机场(CRF)来建模物体之间的上下文关系和物体位姿的时间一致性。 CRF模型中的依赖性包括以下方面:
作者提出了一种基于粒子滤波的算法,在CT-MAP中进行生成推理。
核心思想
使用一个个向量(物体的位置和概率)来代表场景中的物体。针对每个物体向量存在的概率,作者用粒子滤波和CRF来更新。基本的思想是利用不同帧之间的同一物体在空间位置的一致性来更新物体存在的置信度。用概率来表示物体存在的置信度的好处就是,即使机器人即使一段时间内没有识别出这个物体,这个物体还是一定概率和粒子的形式再场景中存在的。
方法
作者提出CT-Map的方法。 CT-Map方法保持了对观察场景中物体类别和位姿的置信度。 假设机器人通过外部定位程序(例如ORB-SLAM)在环境中定位。该语义地图由一组N个物体组成

{

}。 每个物体

= {

}包含物体类别

,物体几何结构

和物体位姿

,其中

是物体类别的集合

{

}。
在t时刻,机器人的位置为

。机器人的观测值为

{

},其中

是观察到的RGB-D图像,

是语义测量值。语义测量值

{

}

,由物体探测器得到,其中包含:
1)物体检测记录矢量

中的每个元素表示每个物体类别的检测置信度,
2)二维边界框

机器人位置

和观测值

是已知的。物体集合

是未知变量。作者对物体之间的环境依赖关系以及每个独立物体随时间变换的时间一致性建模。说白了就是在不同时刻,不同的位置对相同的物体进行观测。
作者是如何建模的?
其中Z是归一化常数,并且在t时刻应用于物体
的动作由

表示。

是预测势能(建模物体姿态的时间一致性)。

是测量势能(给定物体的三维网格的观察模型)。

是环境势能(捕获物体之间的上下文关系)。
如何建模时间一致性?
具体取决于物体是否在视野中。如果物体在视野中,将动作

建模为连续随机变量,其遵循具有零均值和小方差

的高斯分布。 该假设将三维中的小物体移动预测建模为:
当物体
很长一段时间内不在视野中时,它可以位于相同位置或移动到不同位置。物体
仍然处于最后一次观测到的位置的概率是时间的函数。为了考虑物体
可以移动到其他位置的事实,作者用离散随机变量{

}对时间动作

进行建模。具体来说,

表示没有操作,物体停留在同一位置,

表示使用移动操作,物体被移动到其他位置。而这些高层次的动作遵循一定的分布

。
其中

是常数,

是没有观察到物体
的持续时间。 随着Δt的增加,
的概率衰减,最终

,当
Δt 趋于无穷大时。 对于不同的物体
,控制衰减速度的系数

是不同的。作者在实验中为不同的物体提供了探索式
,而这些系数也可以使用Toris等人的介绍的方法来学习。
如何给定物体三维网格的观察模型?
作者使用非零常数δ来说明物体不在视野中的情况。
)
测量观测值
和

之间的兼容性。
其中

是检测置信度向量

对类别

置信度的打分。函数

I 评估两个边界框的最小面积上的交集。

是基于
的图像空间中投影

的最小封闭边界框。
假设已知物体的三维网格模型。函数

计算投影的
和

在边界框
内的相似性。如果机器人之前观测过物体
,对
的置信度表明它处于机器人当前的视野范围内。如果机器人无法检测到物体
,则该物体可能被遮挡,在这种情况下,使用

来估计物体潜在的位置。
如何捕获物体之间的上下文关系?
所有环境中的物体类别之间存在共同的上下文关系。例如,杯子出现在桌子上会比出现在地板上更频繁,鼠标在键盘旁边会比在咖啡机旁边出现得更频繁。作者将这些共同的上下文关系称为类别级的上下文关系。在特定环境中,某些物体实例之间存在上下文关系。例如,电视总是放在某个桌子上,麦片盒通常存储在特定的柜子中。作者将特定环境中的这些上下文关系称为实例级上下文关系。
作者手动将类别级上下文关系编码为模型的先验知识,也可以从公共场景数据集中学习。由于实例级上下文关系在不同环境中是变化的,因此必须随着时间的推移学习特定环境的关系。环境势能由类别级势能

和实例级势能

组成。
将

建模为混合高斯模型,

和

各自为高斯分量。在实验中,手动设计
作为先验知识,并通过贝叶斯更新
。设计
时应遵循两个原则:
1)简单的物理约束,例如不允许物体交叉,物体不应该悬浮在空中,
2)属于同一类别的物体对,比不同类别的物体对更经常同时出现。
粒子滤波的算法
实验和效果
使用Faster R-CNN 作为物体探测器。给定RGB-D观测的RGB通道,应用物体检测器并从区域提出网络中获取边界框,以及相应的类别得分向量。然后对这些边界框使用非最大抑制,并合并具有大于0.5的交叉联合(IoU)的边界框。
在所有实验中,作者使用等式5中的

来同等地处理类别级和实例级的势能。 如果一个物体在无限长时间内没有被观察到,假设物体在相同的位置或不同位置的概率是相同。因此,在等式3中使用

。
物体检测
作者使用Faster R-CNN物体探测器的噪声物体探测,而CT-Map可以通过将物体类别建模隐藏状态的一部分来纠正一些错误探测。为了评估CT-Map的物体检测性能,在数据集中的每个RGB-D序列的末尾处,对场景中所有物体进行六自由度位姿估计,并将它们投射回该序列中的每个相机帧上,以生成带有类别标签的边界框。通过考虑不同的势能集合来进行两个语义映射过程:
1)时间映射(T-Map):考虑CRF模型中的预测势能;
2)环境时间映射(CT-Map):考虑CRF模型中的预测和环境势能。
在观测中,T-Map和CT-Map均包括测量势能。
作者使用mAP作为物体检测指标。如下表所示,T-Map通过结合预测和观察势能改进了Faster R-CNN,并且CT-Map通过另外结合环境势能进一步改善了性能。Faster R-CNN在测试场景中表现不佳,因为训练数据不一定涵盖测试时遇到的差别。虽然通过提供更多的训练数据可以进一步提高Faster R-CNN的性能,但是CT-Map在训练受限的情况下提供了更具有鲁棒性的目标检测
在某些情况下,由于遮挡,Faster R-CNN检测到的物体不可靠。如果之前在环境中观测过一个物体,通过对物体的时间一致性进行建模,来预测物体可以去的位置。因此,即使由于遮挡而未触发对物体的检测,该方法仍然可以定位物体并声明检测。但是,如果物体存在很严重的遮挡且深度观测缺少物体足够的几何信息,无法对物体进行定位。
位姿估计
对于数据集中的每个RGB-D序列,定位最后看到每个物体的帧,并使用已知的相机矩阵将深度帧投影回3D点云。然后,手动标记物体的ground truth六自由度位姿。之后将每个RGB-D序列末尾估计出的物体位姿与ground truth进行比较。
位姿估计精度由

测量,其中

是正确定位的物体数量,

是数据集中存在的物体总数。如果物体位姿估计误差小于在某个位置误差阈值
和旋转误差阈值

,则称该物体被正确地定位。
是欧几里德距离的平移误差,
是方向上的绝对角度差。对于对称物体,忽略关于对称轴的旋转误差。
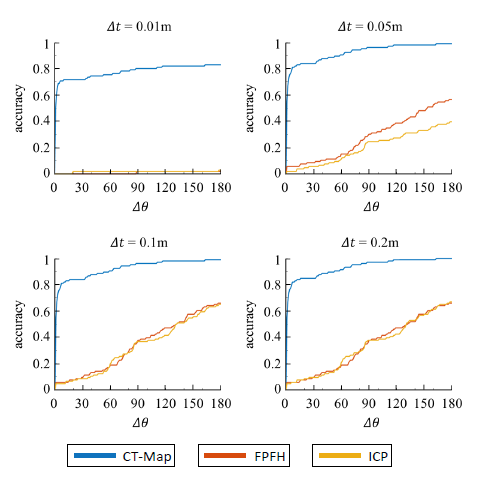
作者应用迭代最近点(ICP)和快点特征直方图(FPFH)算法作为六自由度物体位姿估计的基准。对于数据集中的每个RGB-D序列,作者采用标记帧的3D点云,并根据ground truth边界框裁剪它们。这些裁剪点云作为观察结果与物体3D网格模型一起被提供给基准。 ICP和FPFH用于将物体模型登记到裁剪的观测点云。允许最大迭代次数为50000次。
CT-Map显着优于ICP和FPFH。由于生成推断反复地对物体位姿假设进行采样并根据观察结果对其进行评估,因此CT-Map不会像ICP和FPFH这样的判别方法受到局部最小值的影响。
作者提供的视频,机器人带动RGBD相机移动的过程,采集到多帧数据(RGBD序列),粒子在不断运动,在数据末尾,粒子收敛到物体的范围内。
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- Adversarial Examples for Semantic Segmentation and Object Detection 阅读笔记
Adversarial Examples for Semantic Segmentation and Object Detection (语义分割和目标检测中的对抗样本) 作者:Cihang Xie, ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 目标检测(一)RCNN--Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik 该论文提出了一种简单且可扩展的检测算法,在VOC2012数据集上取得的mAP比当 ...
- 目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
目标检测系列 --- RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation Te ...
- 2 - Rich feature hierarchies for accurate object detection and semantic segmentation(阅读翻译)
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick Jeff ...
- 深度学习论文翻译解析(八):Rich feature hierarchies for accurate object detection and semantic segmentation
论文标题:Rich feature hierarchies for accurate object detection and semantic segmentation 标题翻译:丰富的特征层次结构 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- (转)Awesome Object Detection
Awesome Object Detection 2018-08-10 09:30:40 This blog is copied from: https://github.com/amusi/awes ...
随机推荐
- Spotlight 监控工具使用
监控MySQL数据库性能的工具:Spotlight on MySQL <转载> 我们的服务器数据库:是在windows2003上. 这款工具非常的花哨,界面很漂亮,自带报警. 1.创 ...
- 两篇很好的EPG相关文章
两篇很好的EPG相关文章 原文地址:http://blog.sina.com.cn/s/blog_53220cef0100pi8j.html 1 基于DVB-SI的数字有线电视机顶盒节目指南的设计实现 ...
- ypoj 2286 佳佳买菜
题目名称:佳佳买菜 描述 佳佳是我们的ACM社团的副社长,她感觉得自己没存在感,so-由于实验室要聚餐了,佳佳决定买点菜,来做菜给大家吃.佳佳喜欢吃娃娃菜,于是她来到买菜的地方.佳佳:我要10斤娃娃菜 ...
- swap和shm的区别
在使用docker的过程中,发现其有很多内存相关的命令,对其中的swap(交换内存)和shm(共享内存)尤其费解.于是查阅了一些资料,弄明白了二者的基本区别. swap 是一个文件,是使用硬盘空间的一 ...
- 【系统篇】Archlinux系统安装
本教程为最新安装Linux的教程,想看更详细可以到我B站主页看视频教程 ArchLinux安装配置手册[系统篇] 本教程参考自 https://wiki.archlinux.org/index.php ...
- sql的练习题
表名和字段 –1.学生表 Student(s_id,s_name,s_birth,s_sex) --学生编号,学生姓名, 出生年月,学生性别 –2.课程表 Course(c_id,c_name,t_i ...
- [红日安全]Web安全Day5 - 任意文件上传实战攻防
本文由红日安全成员: MisakiKata 编写,如有不当,还望斧正. 大家好,我们是红日安全-Web安全攻防小组.此项目是关于Web安全的系列文章分享,还包含一个HTB靶场供大家练习,我们给这个项目 ...
- 4款java快速开发平台推荐
JBoss Seam JBoss Seam,算得上是Java开源框架里面最优秀的快速开发框架之一. Seam框架非常出色,尤其是他的组件机制设计的很有匠心,真不愧是Gavin King精心打造的框架了 ...
- OCR场景文本识别:文字检测+文字识别
一. 应用背景 OCR(Optical Character Recognition)文字识别技术的应用领域主要包括:证件识别.车牌识别.智慧医疗.pdf文档转换为Word.拍照识别.截图识别.网络图片 ...
- css布局中的各种FC(BFC、IFC、GFC、FFC)
什么是FC?FC(Formatting Context)格式化上下文,其实指的是一个渲染区域,拥有一套渲染规则,它决定了其子元素如何定位,以及与其他元素之间的关系和相互作用. 什么是BFC? BFC( ...