文献名:Repeat-Preserving Decoy Database for False Discovery Rate Estimation in Peptide Identication (用于肽段鉴定中错误发生率估计的能体现重复性的诱饵数据库)
文献名:Repeat-Preserving Decoy Database for False Discovery Rate Estimation in Peptide Identication (用于肽段鉴定中错误发生率估计的能体现重复性的诱饵数据库)
期刊名:Journal of Proteome Research
发表时间:(2020年3月)
IF:3.78
单位:
- 滑铁卢大学计算机科学学院
- 多伦多细胞生物学和SPARC生物项目中心
- 多伦多大学分子遗传学系
技术:肽段鉴定,诱饵数据库构建
一、 概述:
该研究开发了一种基于de Bruijn图形模型的诱饵数据库构建算法。这种算法构建的诱饵数据库在保证随机性的同时,在很大程度上保留了目标数据库中的序列结构的重复性。而将de Bruijn策略与其他常见诱饵库构建策略进行对比得到的结果表明,在0.01这一较高的错误发生率(FDR)水平上该方法能鉴定到更多的肽段。
二、 研究背景:
在基于质谱的蛋白质组学研究中,数据库搜索方法是最常用的肽段鉴定方法。其原理首先利用蛋白质序列,通过酶切法将其转化为肽,建立理论肽段序列数据库;接着通过将实际谱图与理论数据库中的肽段序列相匹配来实现肽段鉴定。
数据库搜索方法需要一个合理的方法来评估结果的FDR,而目标诱饵(target-decoy)方法是最常见的一种。该方法使用由目标蛋白序列和人工生成的诱饵序列组成的串联序列数据库与MS/MS谱匹配。理想情况下,谱图匹配到诱饵和目标序列的概率分布是相同的。因此,诱饵匹配数成为目标数据库中错误匹配数的估计,FDR则是通过诱饵匹配数与报告的目标匹配数之间的比率来估计的。
因此合理地构建诱饵库就是目标诱饵方法的核心问题,使用de Bruijn方法构建诱饵库可以避免常用的反库或随机库等诱饵库所产生的缺陷。
三、实验设计:
四、研究成果:
1、目标库与不同方法生成的诱饵库中肽段总数与肽段种类数目。可以看出在目标库中大约有一半的数目是重复肽段。因此random shuffling与normalized shuffling生成的诱饵库包含的肽段种类更多,这最终会导致FDR的偏高。而其他四种方法利用一定的规则生成诱饵序列,避免或减少了这一问题。

2、不同诱饵库在1%FDR下的肽段谱图匹配数。Normalized Shuffling方法的FDR是在乘以0.519的标准化因子后计算的。从图中可以看出使用de brujin诱饵库得到的肽段数量最多。这个现象可以从以下几个角度解释:
对于Random Shuffling,Normalized Shuffling与TPP方法而言,性能较差的原因是诱饵数据库中肽段的种类比目标库要多。由于诱饵肽种类的增加,质谱谱图与更多的诱饵肽进行了匹配评分,这可能导致一些分数处在阈值上的真正该被匹配到的目标肽被随机产生的诱饵肽所淘汰。这对正确识别目标肽有不利的影响。
而对于Reversal与shifted Reversal方法,性能较差的原因可能是目标肽和诱饵肽及其谱图的碎片离子之间存在高度的相关性。

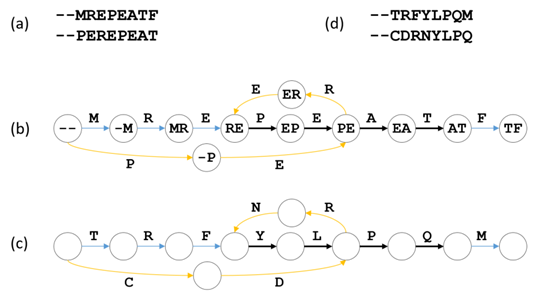
3、de brujin的原理实例图:(a) 两个目标库蛋白序列的示例。(b) 对应的k=2的de-Bruijn图。每个目标序列对应于图中的一条路径。第一个序列、第二个序列和两个序列共享的边分别为蓝色、橙色和黑色。(c) 边缘标签随机替换为其他氨基酸。(d) 诱饵蛋白序列是通过在重标记图中跟踪两个目标蛋白的路径获得的。
简而言之,氨基酸在替换时会考虑以此氨基酸为起始的k个氨基酸所组成的序列,相同的序列会将此氨基酸替换为同一个随机氨基酸,从而达到保护序列重复性的效果。
五、文章亮点(结论讨论):针对生成用于数据库搜库方法FDR估计的诱饵库,本文提出了一种数学上严格且易于实现的方法de brujin,能够在保留蛋白质重复结构的同时生成带有随机性的诱饵序列。此方法避免了简单的随机方法不保留目标数据库中的重复片段与Reversal方法使目标诱饵库之间相似性过高的问题,且从数据与原理两个角度说明了de Bruijn方法的良好性能。
阅读人:刘佳维
文献名:Repeat-Preserving Decoy Database for False Discovery Rate Estimation in Peptide Identication (用于肽段鉴定中错误发生率估计的能体现重复性的诱饵数据库)的更多相关文章
- False Discovery Rate, a intuitive explanation
[转载请注明出处]http://www.cnblogs.com/mashiqi Today let's talk about a intuitive explanation of Benjamini- ...
- MCP|MZL|Accurate Estimation of Context- Dependent False Discovery Rates in Top- Down Proteomics 在自顶向下蛋白组学中精确设定评估条件估计假阳性
一. 概述: 自顶向下的蛋白质组学技术近年来也发展成为高通量蛋白定性定量手段.该技术可以在一次的实验中定性上千种蛋白,然而缺乏一个可靠的假阳性控制方法阻碍了该技术的发展.在大规模流程化的假阳性控制手段 ...
- The database could not be exclusively locked to perform the operation(SQL Server 5030错误解决办法)(转)
Microsoft SQL Server 5030错误解决办法 今天在使用SQL Server时,由于之前创建数据库忘记了设置Collocation,数据库中插入中文字符都是乱码,于是到DataBas ...
- 假设用一个名为text的字符串向量存放文本文件的数据,其中的元素或者是一句话或者是一个用于表示段分隔的空字符串。将text中第一段全改为大写形式
#include<iostream> #include<string> #include<vector> using namespace std; int main ...
- Python scikit-learn机器学习工具包学习笔记
feature_selection模块 Univariate feature selection:单变量的特征选择 单变量特征选择的原理是分别单独的计算每个变量的某个统计指标,根据该指标来判断哪些指标 ...
- Population-based metagenomics analysis reveals markers for gut microbiome composition and diversity
读paper的时候觉得自己就是个24K纯学渣(=.=)一大堆问题等着我去解决...所以在这里写一个Q&A好了,先列问题,逐步填充答案- ××××××××××××××××××我是分割线么么哒×× ...
- Python scikit-learn机器学习工具包学习笔记:feature_selection模块
sklearn.feature_selection模块的作用是feature selection,而不是feature extraction. Univariate feature selecti ...
- Python —— sklearn.feature_selection模块
Python —— sklearn.feature_selection模块 sklearn.feature_selection模块的作用是feature selection,而不是feature ex ...
- Multi-batch TMT reveals false positives, batch effects and missing values(解读人:胡丹丹)
文献名:Multi-batch TMT reveals false positives, batch effects and missing values (多批次TMT定量方法中对假阳性率,批次效应 ...
随机推荐
- 前端实现html转pdf方法总结
最近要搞前端html转pdf的功能.折腾了两天,略有所收,踩了一些坑,所以做些记录,为后来的兄弟做些提示,也算是回馈社区.经过一番调(sou)研(suo)发现html导出pdf一般有这几种方式,各有各 ...
- Windows安装python包出现PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问的问题解决方案
在python中安装sqlalchemy时,总是提示(当安装依赖有vs的python包时,可能会出现以下错误:) PermissionError: [WinError 32] 另一个程序正在使用此文件 ...
- 一起了解 .Net Foundation 项目 No.15
.Net 基金会中包含有很多优秀的项目,今天就和笔者一起了解一下其中的一些优秀作品吧. 中文介绍 中文介绍内容翻译自英文介绍,主要采用意译.如与原文存在出入,请以原文为准. NUnit Test Fr ...
- python切片使用方法(超详细)
#切片:就是根据一个下标范围来获取一部分数据,切片通常结合字符串,列表,元组使用 # 为什么使用切片?因为下标只能获取一个数据,所以想要获取字符串或者列表当中一部分数据需要用切片. # 切片的语法格式 ...
- LoadRunner 11破解方法:
LoadRunner 11破解方法: 请严格安装顺序操作! a.用LR8.0中的mlr5lprg.dll.lm70.dll覆盖LR11安装目录下“bin”文件夹中的对应文件: b.运行deleteli ...
- 简单的猜数字小游戏--Python
猜数字小游戏: #coding=utf-8 import random answer =random.randint(1,100) #生成随机数 n=int (input("Please ...
- SpringBoot——Cache使用原理及Redis整合
前言及核心概念介绍 前言 本篇主要介绍SpringBoot2.x 中 Cahe 的原理及几个主要注解,以及整合 Redis 作为缓存的步骤 核心概念 先来看看核心接口的作用及关系图: CachingP ...
- ReentrantLock源码探究
ReentrantLock是一种可重入锁,可重入是说同一个线程可以多次获取同一个锁,内部会有相应的字段记录重入次数,它同时也是一把互斥锁,意味着同时只有一个线程能获取到可重入锁. 1.构造函数 pub ...
- Java安装和配置
一. Java安装和配置 1.JDK下载地址: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-21331 ...
- (转)协议森林07 傀儡 (UDP协议)
协议森林07 傀儡 (UDP协议) 作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 我们已经讲解了物理层.连接层和网络层.最开始的 ...