十 | 门控循环神经网络LSTM与GRU(附python演练)
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习、深度学习的知识!
目录:
- 门控循环神经网络简介
- 长短期记忆网络(LSTM)
- 门控制循环单元(GRU)
- TensorFlow实现LSTM和GRU
- 参考文献
一、门控循环神经网络
门控循环神经网络在简单循环神经网络的基础上对网络的结构做了调整,加入了门控机制,用来控制神经网络中信息的传递。门控机制可以用来控制记忆单元中的信息有多少需要保留,有多少需要丢弃,新的状态信息又有多少需要保存到记忆单元中等。这使得门控循环神经网络可以学习跨度相对较长的依赖关系,而不会出现梯度消失和梯度爆炸的问题。如果从数学的角度来理解,一般结构的循环神经网络中,网络的状态和之间是非线性的关系,并且参数W在每个时间步共享,这是导致梯度爆炸和梯度消失的根本原因。门控循环神经网络解决问题的方法就是在状态和之间添加一个线性的依赖关系,从而避免梯度消失或梯度爆炸的问题。
二、长短期记忆网络(LSTM)
长短期记忆网络(Long Short-term Memory,简称LSTM)的结构如图1所示,LSTM[1]的网络结构看上去很复杂,但实际上如果将每一部分拆开来看,其实也很简单。在一般的循环神经网络中,记忆单元没有衡量信息的价值量的能力,因此,记忆单元对于每个时刻的状态信息等同视之,这就导致了记忆单元中往往存储了一些无用的信息,而真正有用的信息却被这些无用的信息挤了出去。LSTM正是从这一点出发做了相应改进,和一般结构的循环神经网络只有一种网络状态不同,LSTM中将网络的状态分为内部状态和外部状态两种。LSTM的外部状态类似于一般结构的循环神经网络中的状态,即该状态既是当前时刻隐藏层的输出,也是下一时刻隐藏层的输入。这里的内部状态则是LSTM特有的。
在LSTM中有三个称之为“门”的控制单元,分别是输入门(input gate)、输出门(output gate)和遗忘门(forget gate),其中输入门和遗忘门是LSTM能够记忆长期依赖的关键。输入门决定了当前时刻网络的状态有多少信息需要保存到内部状态中,而遗忘门则决定了过去的状态信息有多少需要丢弃。最后,由输出门决定当前时刻的内部状态有多少信息需要输出给外部状态。
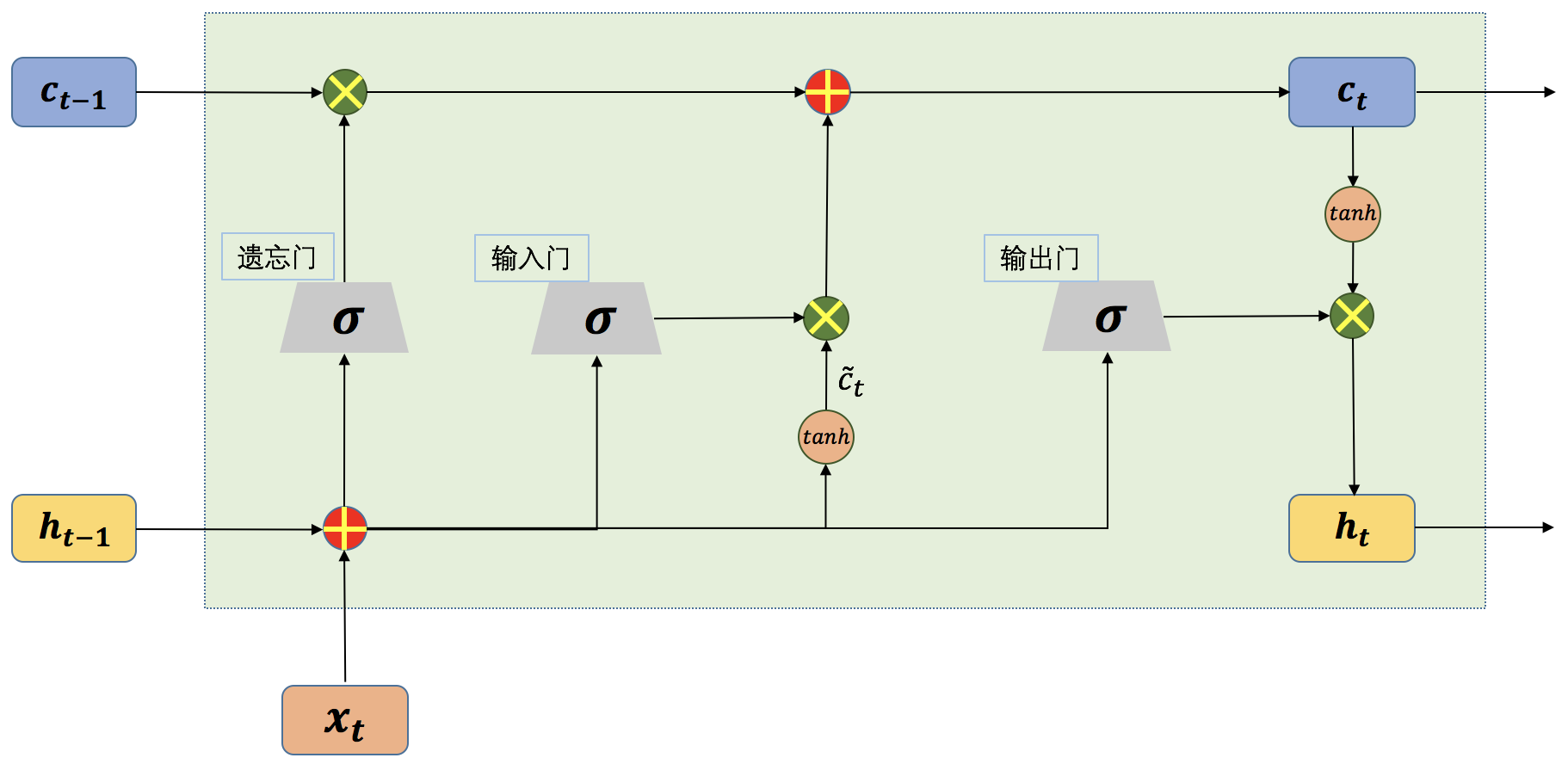
图1 单个时间步的LSTM网络结构示意图
从上图我们可以看到,一个LSTM单元在每个时间步都会接收三个输入,当前时刻的输入,来自上一时刻的内部状态以及上一时刻的外部状态。其中,和同时作为三个“门”的输入。为Logistic函数,。
接下来我们将分别介绍LSTM中的几个“门”结构。首先看一下输入门,如图2所示:
从上图我们可以看到,一个LSTM单元在每个时间步都会接收三个输入,当前时刻的输入,来自上一时刻的内部状态以及上一时刻的外部状态。其中,和同时作为三个“门”的输入。为Logistic函数,。
接下来我们将分别介绍LSTM中的几个“门”结构。首先看一下输入门,如图2所示:
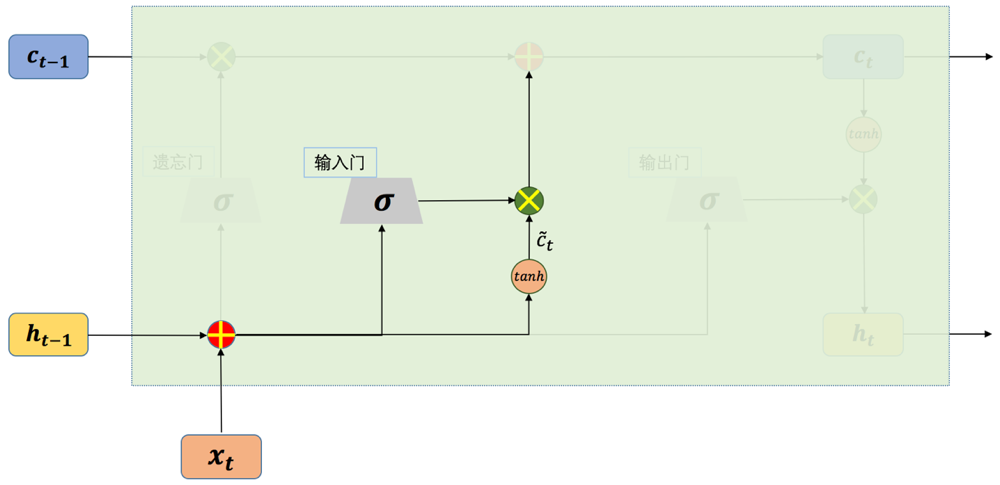
图2 LSTM的输入门结构示意图
LSTM中也有类似于RNN(这里特指前面介绍过的简单结构的循环神经网络)的前向计算过程,如图2,如果去掉输入门部分,剩下的部分其实就是RNN中输入层到隐藏层的结构,“tanh”可以看作是隐藏层的激活函数,从“tanh”节点输出的值为:
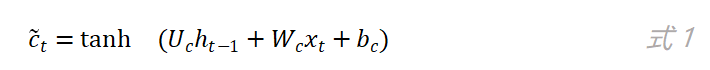
上式中,参数的下标“c”代表这是“tanh”节点的参数,同理,输入门参数的下标为“i”,输出门参数的下标为“o”,遗忘门参数的下标为“f”。上式与简单结构循环神经网络中隐藏层的计算公式一样。在LSTM中,我们将“tanh”节点的输出称为候选状态。
输入门是如何实现其控制功能的?输入门的计算公式如下:
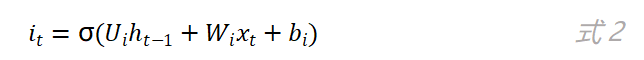
由于为Logistic函数,其值域为,因此输入门的值就属于。LSTM将“tanh”节点的输出(即候选状态)乘上输入门的值后再用来更新内部状态。如果的值趋向于0的话,那么候选状态就只有极少量的信息会保存到内部状态中,相反的,如果的值趋近于1,那么候选状态就会有更多的信息被保存。输入门就是通过这种方法来决定保存多少中的信息,值的大小就代表了新信息的重要性,不重要的信息就不会被保存到内部状态中。
再来看遗忘门,如图3所示:
图3 LSTM的遗忘门结构示意图
遗忘门的计算公式如下:
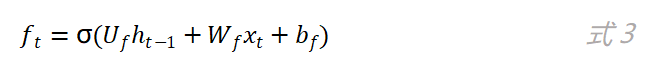
和输入门是同样的方法,通过f_t的值来控制上一时刻的内部状态c_(t-1)有多少信息需要“遗忘”。当f_t的值越趋近于0,被遗忘的信息越多。同样的原理,我们来看“输出门”,如图4所示。输出门的计算公式如下:
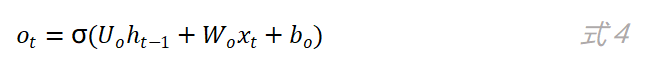
当o_t的值月接近于1,则当前时刻的内部状态c_t就会有更多的信息输出给当前时刻的外部状态h_t。
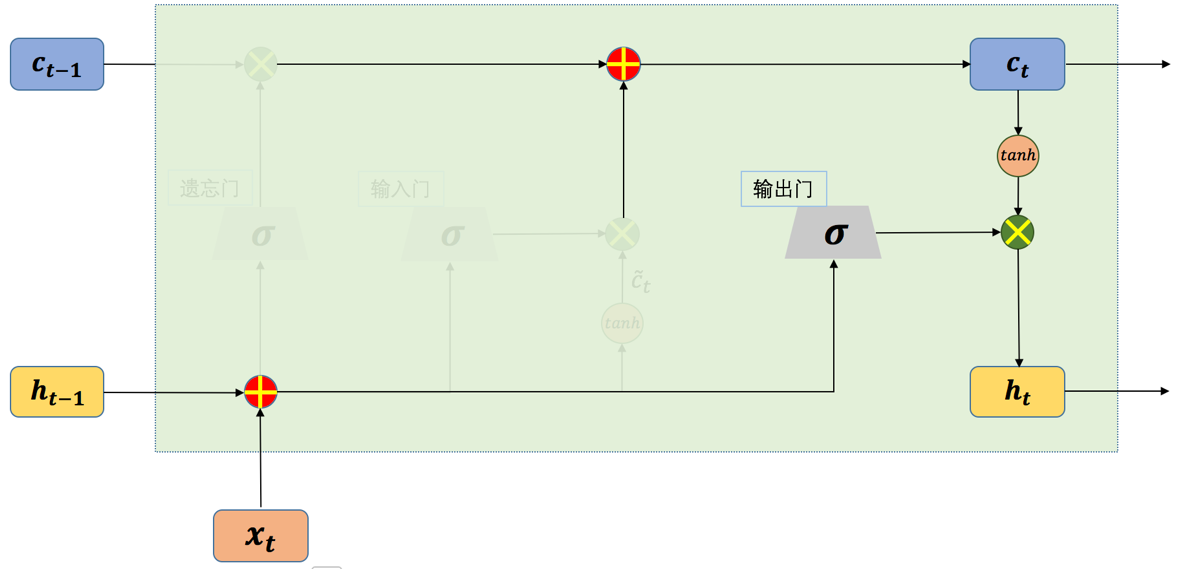
图4 LSTM的输出门结构示意图
以上就是LSTM的整个网络结构以及各个“门”的计算公式。通过选择性的记忆和遗忘状态信息,使的LSTM要比一般的循环神经网络能够学习更长时间间隔的依赖关系。根据不同的需求,LSTM还有着很多不同的变体版本,这些版本的网络结构大同小异,但都在其特定的应用中表现出色。
三、门控制循环单元(GRU)
门控制循环单元(gated recurrent unit,GRU)网络是另一种基于门控制的循环神经网络,GRU[2]的网络结构相比LSTM要简单一些。GRU将LSTM中的输入门和遗忘门合并成了一个门,称为更新门(update gate)。在GRU网络中,没有LSTM网络中的内部状态和外部状态的划分,而是通过直接在当前网络的状态h_t和上一时刻网络的状态h_(t-1)之间添加一个线性的依赖关系,来解决梯度消失和梯度爆炸的问题。
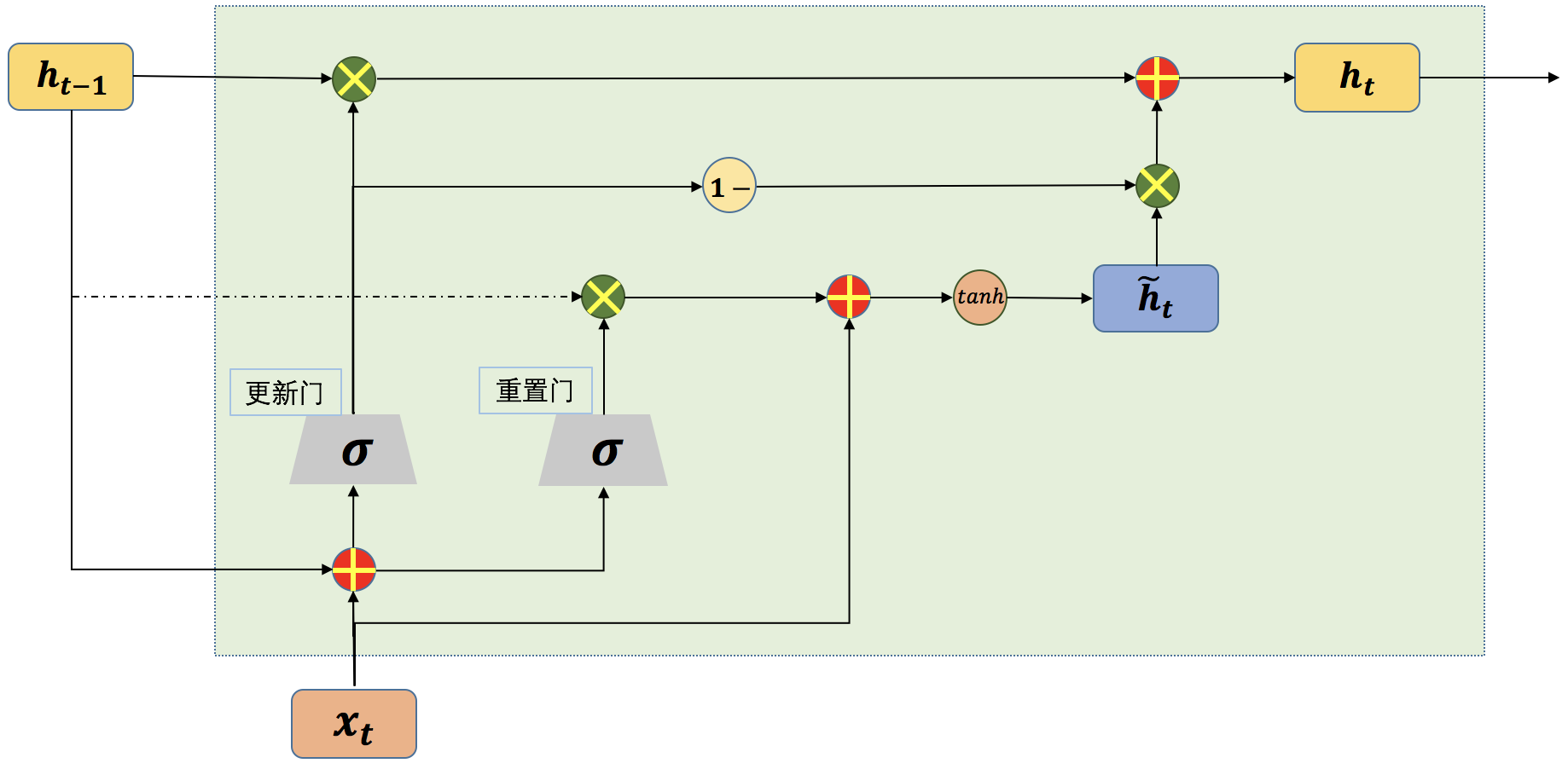
图5 单个时间步的GRU网络结构示意图
在GRU网络中,更新门用来控制当前时刻输出的状态h_t中要保留多少历史状态h_(t-1),以及保留多少当前时刻的候选状态h ̃_t。更新门的计算公式如下:
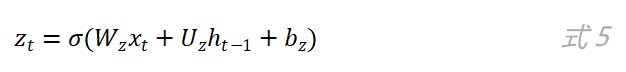
如图5所示,更新门的输出分别和历史状态h_(t-1)以及候选状态h ̃_t进行了乘操作,其中和h ̃_t相乘的是1-z_t。最终当前时刻网络的输出为:
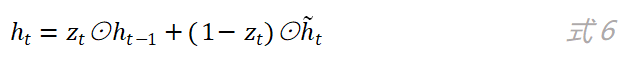
重置门的作用是决定当前时刻的候选状态是否需要依赖上一时刻的网络状态以及需要依赖多少。从图5可以看到,上一时刻的网络状态h_t先和重置门的输出r_t相乘之后,再作为参数用于计算当前时刻的候选状态。重置门的计算公式如下:
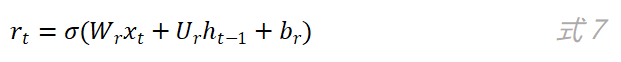
r_t的值决定了候选状态h ̃_t对上一时刻的状态h_(t-1)的依赖程度,候选状态h ̃_t的计算公式如下:
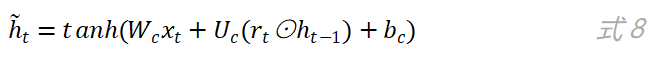
其实当z_t的值为0且r_t的值为1时,GRU网络中的更新门和重置门就不再发挥作用了,而此时的GRU网络就退化成了简单循环神经网络,因为此时有:
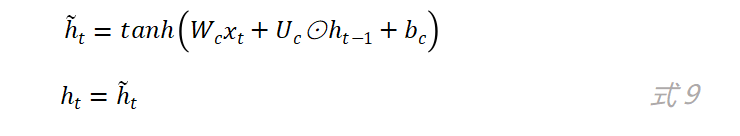
四、TensorFlow实现LSTM和GRU
前面介绍了LSTM和GRU的理论知识,这一小节里我们使用TensorFlow来实现一个LSTM模型。为了方便,这里我们使用前面介绍过的mnist数据集。可能读者对于在循环神经网络中使用图像数据会有一点疑惑,因为通常情况下图像数据一般都是使用卷积神经网络来训练。事实的确是这样,由于卷积神经网络和循环神经网络的结构不同,也就使得它们各自有不同的适用场景,但这不代表卷积神经网络只能用来处理时序数据,同样也不能认为循环神经网络不能用来处理图像数据,只要在输入数据的格式上稍作调整即可,就像上一章中我们使用卷积神经网络网络来处理文本数据一样。
mnist数据集我们在第三章中就已经使用过,这里就不再多做介绍了,直接上代码:
1 from tensorflow.examples.tutorials.mnist import input_data
2 import tensorflow as tf
3 from tensorflow.contrib import rnn
4
5 batch_size = 100 # batch的大小
6 time_step = 28 # LSTM网络中的时间步(每个时间步处理图像的一行)
7 data_length = 28 # 每个时间步输入数据的长度(这里就是图像的宽度)
8 learning_rate = 0.01 # 学习率
我们首先导入需要的包,然后定义了神经网络中的一些相关参数。其中第6行代码定义了LSTM中的时间步的长度,由于我们mnist数据集的图像大小为28X28,所以我们将一行像素作为一个输入,这样我们就需要有28个时间步。第7行代码定义了每个时间步输入数据的长度(每个时间步的输入是一个向量),即一行像素的长度。
9 # 下载mnist数据集,当前目录有已下载的数据集的话,就直接读取,
10 mnist = input_data.read_data_sets("data", one_hot=True, reshape=False, validation_size=1000)
11
12 # 定义相关数据的占位符
13 X_ = tf.placeholder(tf.float32, [None, 28, 28, 1]) # 输入数据
14 Y_ = tf.placeholder(tf.int32, [None, 10]) # mnist数据集的类标
15 # dynamic_rnn的输入数据(batch_size, max_time, ...)
16 inputs = tf.reshape(X_, [-1, time_step, data_length])
17 # 验证集
18 validate_data = {X_: mnist.validation.images, Y_: mnist.validation.labels}
19 # 测试集
20 test_data = {X_: mnist.test.images, Y_: mnist.test.labels}
第10行代码用来加载mnist数据集,并通过参数“validation_size”指定了验证集的大小。第16行代码用来将mnist数据集的格式转换成“dynamic_rnn”函数接受的数据格式“[batch_size, max_time, data_length]”。
21 # 定义一个两层的LSTM模型
22 lstm_layers = rnn.MultiRNNCell([rnn.BasicLSTMCell(num_units=num)
for num in [100, 100]], state_is_tuple=True)
23 # 定义一个两层的GRU模型
24 # gru_layers = rnn.MultiRNNCell([rnn.GRUCell(num_units=num)
# for num in [100, 100]], state_is_tuple=True)
25
26 outputs, h_ = tf.nn.dynamic_rnn(lstm_layers, inputs, dtype=tf.float32)
27 # outputs, h_ = tf.nn.dynamic_rnn(gru_layers, inputs, dtype=tf.float32)
28
29 output = tf.layers.dense(outputs[:, -1, :], 10) # 获取LSTM网络的最后输出状态
30
31 # 定义交叉熵损失函数和优化器
32 loss = tf.losses.softmax_cross_entropy(onehot_labels=Y_, logits=output) # compute cost
33 train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)
34
35 # 计算准确率
36 accuracy = tf.metrics.accuracy(
labels=tf.argmax(Y_, axis=1), predictions=tf.argmax(output, axis=1))[1]
37
38 # 初始化变量
39 sess = tf.Session()
40 init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
41 sess.run(init)
在上面的代码中,我们定义了一个两层的LSTM网络结构,并使用了交叉熵损失函数和“Adam”优化器。LSTM多层网络结构的定义和我们前面使用过的多层神经网络的定义方法一样,只是将“BasicRNNCell”类换成了“BasicLSTMCel”类。
42 for step in range(3000):
43 # 获取一个batch的训练数据
44 train_x, train_y = mnist.train.next_batch(batch_size)
45 _, loss_ = sess.run([train_op, loss], {X_: train_x, Y_: train_y})
46
47 # 在验证集上计算准确率
48 if step % 50 == 0:
49 val_acc = sess.run(accuracy, feed_dict=validate_data)
50 print('train loss: %.4f' % loss_, '| val accuracy: %.2f' % val_acc)
51
52 # 计算测试集上的准确率
53 test_acc = sess.run(accuracy, feed_dict=test_data)
54 print('test loss: %.4f' % test_acc)
在上面的整个代码中,我们使用的参数都是比较随意的进行选择的,没有进行任何的优化,最终在测试集上的结果能达到96%左右,当然这肯定不是LSTM网络处理mnist数据集所能达到的最好的效果,有兴趣的读者可以试着去调整网络的结构和参数,看是否能达到更高的准确率。
TensorFlow中实现LSTM和GRU的切换非常简单,在上面的代码中,将第22和26行代码注释掉,然后取消第24和27行代码的注释,实现的就是GRU。
本文介绍了门控循环神经网络LSTM以及GRU的原理及其tensorflow代码实现,希望能让大家对常用到的LSTM及GRU能够有更好的理解。下一篇,我们将介绍RNN循环神经网络的应用部分,分析RNN循环神经网络是怎样用在文本分类,序列标注以及机器翻译上的,以及其存在的不足与改进方法。
五、 参考文献
[1]Sepp Hochreiter: Long Short-term Memory .1997
[2]Kazuki Irie, Zoltán Tüske, TamerAlkhouli, Ralf Schlüter, Hermann Ney:LSTM, GRU, Highway and a Bit of Attention:An Empirical Overview for Language Modeling in Speech Recognition. INTERSPEECH2016: 3519-3523
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习、深度学习的知识!
十 | 门控循环神经网络LSTM与GRU(附python演练)的更多相关文章
- [DeeplearningAI笔记]序列模型1.7-1.9RNN对新序列采样/GRU门控循环神经网络
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.7对新序列采样 基于词汇进行采样模型 在训练完一个模型之后你想要知道模型学到了什么,一种非正式的方法就是进行一次新序列采 ...
- 门控循环单元(GRU)与 LSTM 的区别
29 November 2019 14:48 GRU is a popular variant of LSTM which replaces the forget gate and the input ...
- 三步理解--门控循环单元(GRU),TensorFlow实现
1. 什么是GRU 在循环神经⽹络中的梯度计算⽅法中,我们发现,当时间步数较⼤或者时间步较小时,循环神经⽹络的梯度较容易出现衰减或爆炸.虽然裁剪梯度可以应对梯度爆炸,但⽆法解决梯度衰减的问题.通常由于 ...
- 第十四章——循环神经网络(Recurrent Neural Networks)(第二部分)
本章共两部分,这是第二部分: 第十四章--循环神经网络(Recurrent Neural Networks)(第一部分) 第十四章--循环神经网络(Recurrent Neural Networks) ...
- 循环神经网络LSTM RNN回归:sin曲线预测
摘要:本篇文章将分享循环神经网络LSTM RNN如何实现回归预测. 本文分享自华为云社区<[Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测 丨[百变AI秀]& ...
- 第十四章——循环神经网络(Recurrent Neural Networks)(第一部分)
由于本章过长,分为两个部分,这是第一部分. 这几年提到RNN,一般指Recurrent Neural Networks,至于翻译成循环神经网络还是递归神经网络都可以.wiki上面把Recurrent ...
- Pytorch循环神经网络LSTM时间序列预测风速
#时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大 ...
- 『PyTorch』第十弹_循环神经网络
RNN基础: 『cs231n』作业3问题1选讲_通过代码理解RNN&图像标注训练 TensorFlow RNN: 『TensotFlow』基础RNN网络分类问题 『TensotFlow』基础R ...
- 序列模型(4)----门控循环单元(GRU)
一.GRU 其中, rt表示重置门,zt表示更新门. 重置门决定是否将之前的状态忘记.(作用相当于合并了 LSTM 中的遗忘门和传入门) 当rt趋于0的时候,前一个时刻的状态信息ht−1会被忘掉,隐藏 ...
随机推荐
- HTML标签学习总结(3)
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- jQuery样式及html属性操作
样式及html属性操作1,行内样式 css(); a:获取样式 元素.css(样式名称); b:设置单个样式 元素.css("样式名称":"样式值"); c:设 ...
- KEMET推出新的多层陶瓷电容器,用于市电供电的应用
前言:2019年12月2日,全球领先的电子组件供应商KEMET公司 (“ KEMET”或“公司”)推出了一系列新的表面安装设备(SMD)安全认证的多层陶瓷电容器(MLCC),用于市电供电的应用.与现有 ...
- PhalApi 2.7 开发快速上手
PhalApi是一款国人制作的PHP纯后端框架.它的开发相当简单,同时也具备文档生成等特色功能.下面,我通过简单的几点,让你可以快速入门使用该框架的开发. 建议使用PHPStorm作为IDE,代码提示 ...
- ES6 常用知识点总结
ES6常用知识总结 之前总结了es5中js的一些知识点.这段时间看了石川blue老师讲解的es6课程,结合阮一峰老师的es6教程,随手做了一些笔记和总结分享给大家.内容还是es6主要的知识点,基本没有 ...
- python学习记录_IPython基础,Tab自动完成,内省,%run命令_
这是我第一次写博客,之前也有很多想法,想把自己所接触的,以文本的形式储存,总是没有及时行动.此次下定决心,想把自己所学,所遇到的问题做个记录共享给诸位,与此同时自己作为备忘,感谢各位访问我的博 ...
- Yuchuan_Linux_C 编程之十一 进程间通信
一.整体大纲 二.进程间通信概念及方法 Linux环境下,进程地址空间相互独立,每个进程各自有不同的用户地址空间.任何一个进程的全局变量在另一个进程中都看不到,所以进程和进程之间不能相互访问,要交换 ...
- Apollo 高可用配置中心搭建教程
Apollo开源文档中搭建流程讲的很详细,此处只提供传送门 1.Apollo配置中心开源地址 2.服务包下载地址 3.教程文档地址 4.视频教程地址 5.Apollo使用指南 说明: apollo-c ...
- getBoundingClientRect的实用场景
在用vue开发项目时候,遇到一个问题,首页有代办列表,是固定定位,滚动时候需要监听距离页面顶部的距离,如果很接近顶部则将代办列表展示,首页隐藏,如果再网上翻动则又回到首页. 因为是是fixed定位,所 ...
- 迄今为止最硬核的「Java8时间系统」设计原理与使用方法
为了使本篇文章更容易让读者读懂,我特意写了上一篇<任何人都需要知道的「世界时间系统」构成原理,尤其开发人员>的科普文章.本文才是重点,绝对要读,走起! Java平台时间系统的设计方案 几乎 ...