深入理解Java AIO(三)—— Linux中的AIO实现
我们调用的Java AIO底层也是要调用OS的AIO实现,而OS主要也就Windows和Linux这两大类,当然还有Solaris和mac这些小众的。
- 在 Windows 操作系统中,提供了一个叫做 I/O Completion Ports 的方案,通常简称为 IOCP,操作系统负责管理线程池,其性能非常优异,所以在 Windows 中 JDK 直接采用了 IOCP 的支持。
- 而在 Linux 中其实也是有AIO 的实现的,但是限制比较多,性能也一般,所以 JDK 采用了自建线程池的方式,也就是说JDK并没有用Linux提供的AIO。但是本文主要想聊的,就是Linux中的AIO实现。
Linux AIO主要有三种实现:
- glibc 的 AIO 本质上是由多线程在用户态下模拟出来的异步IO,但是glibc下的POSIX AIO的bug太多,而且找不到相关资料,所以我们这里不详细讲。(我查了一下相关资料大多数是11年左右的那几篇文章,感兴趣的可以自己去了解一下)
- 而libeio的实现和glibc很像,也是由多线程在用户态下模拟出来的异步IO,是libev 的作者 Marc Alexander Lehmann大佬写的,一会会提及它
- Linux 2.6以上的版本实现了内核级别的AIO,内核的AIO只能以 O_DIRECT(直接写入磁盘) 的方式做直接 IO(使用了虚拟文件系统,其他OS不一定能用)
glibc 的 AIO
- 异步请求被提交到request_queue中;
- request_queue实际上是一个表结构,"行"是fd、"列"是具体的请求。也就是说,同一个fd的请求会被组织在一起;
- 异步请求有优先级概念,属于同一个fd的请求会按优先级排序,并且最终被按优先级顺序处理;
- 随着异步请求的提交,一些异步处理线程被动态创建。这些线程要做的事情就是从request_queue中取出请求,然后处理之;
- 为避免异步处理线程之间的竞争,同一个fd所对应的请求只由一个线程来处理;
- 异步处理线程同步地处理每一个请求,处理完成后在对应的aiocb中填充结果,然后触发可能的信号通知或回调函数(回调函数是需要创建新线程来调用的);
- 异步处理线程在完成某个fd的所有请求后,进入闲置状态;
- 异步处理线程在闲置状态时,如果request_queue中有新的fd加入,则重新投入工作,去处理这个新fd的请求(新fd和它上一次处理的fd可以不是同一个);
- 异步处理线程处于闲置状态一段时间后(没有新的请求),则会自动退出。等到再有新的请求时,再去动态创建;
更详细的可以自己去看Linux里面的源码是怎么写的
libeio 的 AIO
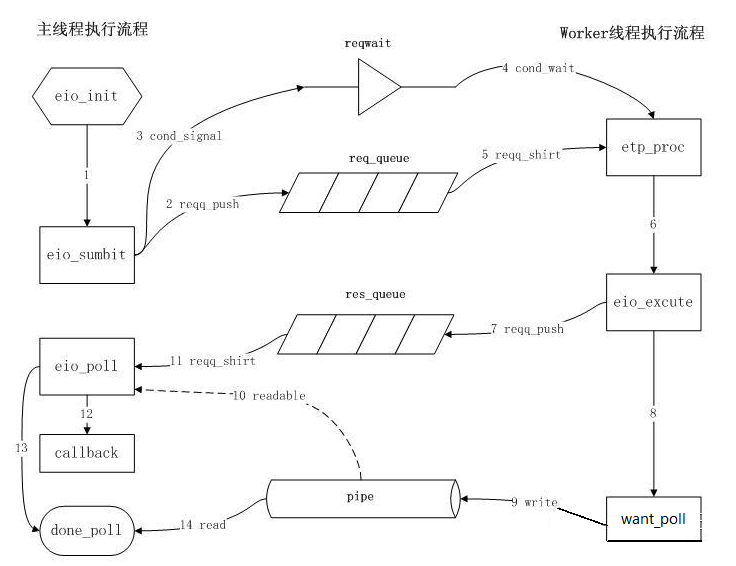
1. 主线程调用eio_init函数,主要是初始化req_queue(请求队列),res_queue(响应队列)以及对应的mutex(互斥锁)和cond(pthread,Linux多线程部分);
2-3. 所有的IO操作其实都是对eio_sumbit的调用,而eio_sumbit的职能是将IO操作封装为request并插入到req_queue;并调用cond_signal向worker线程发出reqwait已经OK的信号;
4. worker线程被创建后执行的函数为etp_proc,etp_proc启动后会一直等待reqwait条件的出现;
5-6. 当reqwait条件变量满足时,etp_proc从req_queue中取得一个待处理的request;并调用eio_execute来同步执行该IO操作;
7-8. eio_execute完成后,将response插入到res_queue队列中;同时调用want_poll来通知主线程request已经处理完毕;
9. 这里worker线程通知主线程的机制是通过向pipe[1]写一个byte数据;
10. 当主线程发现pipe[0]可读时,就调用eio_poll;
11. eio_poll从res_queue里取response,并调用该IO操作在init时设置的callback函数完成后续处理;
12. 在res_queue中没有待处理response时,调用done_poll;
13-14. done_poll从pipe[0]读出一个byte数据,该IO操作完成。
Linux libaio 内核级别AIO

- 首先是调用 io_setup 函数创建一个aio上下文 aio_context_t (对应内核中的kioctx),这个上下文包含等待队列等内容和一个存放 io_event 的 aio_ring_buffer
- 调用 io_submit 提交异步请求,每一个请求都会创建一个 iocb 结构用于描述这个请求(对应内核中的kiocb)
- 调用 aio_rw_vect_retry 提交请求到虚拟文件系统,这个方法调用了 file->f_op(open)->aio_read 或 file->f_op->aio_write 提交到了虚拟文件系统,提交完后 IO 请求立即返回,而不等待虚拟文件系统完成相应操作(这也就是为什么内核级别实现的aio不一定兼容其他OS的原因,因为使用了自有的文件系统)
- 调用wake_up_process唤醒被阻塞的进程(io_getevents的调用者)
- 最后然后调用aio_complete 将处理结果写回到对应的io_event中
- io_getevents返回结果
内核级AIO与用户线程级别的AIO(glibc和libeio)的比较
- 从上面的流程可以看出,linux版本的异步IO实际上只是利用了CPU和IO设备可以异步工作的特性(IO请求提交的过程主要还是在调用者线程上同步完成的,请求提交后由于CPU与IO设备可以并行工作,所以调用流程可以返回,调用者可以继续做其他事情)。相比同步IO,并不会占用额外的CPU资源。
- 而glibc版本的异步IO则是利用了线程与线程之间可以异步工作的特性,使用了新的线程来完成IO请求,这种做法会额外占用CPU资源(对线程的创建、销毁、调度都存在CPU开销,并且调用者线程和异步处理线程之间还存在线程间通信的开销)。不过,IO请求提交的过程都由异步处理线程来完成了(而linux版本是调用者来完成的请求提交),调用者线程可以更快地响应其他事情。如果CPU资源很富足,这种实现倒也还不错。
- 当调用者连续调用异步IO接口,提交多个异步IO请求时。在glibc版本的异步IO中,同一个fd的读写请求由同一个异步处理线程来完成。而异步处理线程又是同步地、一个一个地去处理这些请求。所以,对于底层的IO调度器来说,它一次只能看到一个请求。处理完这个请求,异步处理线程才会提交下一个。
- 而内核实现的异步IO,则是直接将所有请求都提交给了IO调度器,IO调度器能看到所有的请求。请求多了,IO调度器使用的类电梯算法就能发挥更大的功效。请求少了,极端情况下(比如系统中的IO请求都集中在同一个fd上,并且不使用预读),IO调度器总是只能看到一个请求,那么电梯算法将退化成先来先服务算法,可能会极大的增加碰头移动的开销。
- glibc版本的异步IO支持非direct-io,可以利用内核提供的page cache来提高效率。而linux版本只支持direct-io,cache的工作就只能靠用户程序来实现了。
顺便提一嘴,没有OS提供了本地文件的非阻塞IO(NIO),对于文件的读写,即使以O_NONBLOCK方式来打开一个文件,也会处于"阻塞"状态。因为文件时时刻刻处于可读状态。
不得不说,一旦把一样技术挖到比较深的地方的话,涉及到的就是各种OS的知识甚至C语言的东西了。而这对于我这种只会表面调包的码畜来说非常的不友好,毕竟我没有学过Linux内核相关的知识,没有Linux编程的基础(我甚至连C语言都不怎么熟悉)。希望以后能找时间补上。
(区区Linux AIO,可难不倒我名侦探野比大雄!)PS:如果有错的话希望大家指正,毕竟之前就写错了,虽然我知道根本没人看我blog。

参考资料:
深入理解Java AIO(三)—— Linux中的AIO实现的更多相关文章
- 运用《深入理解Java虚拟机》书中知识解决实际问题
前言 以前看别人博客说看完<深入理解Java虚拟机>这本书并没有让自己的编程水平提高多少,不过却大大提高了自己的装逼水平.其实,我倒不这么认为,至少在我看完一遍这本书后,有一种醍醐灌顶的感 ...
- 理解java的三种代理模式
代理模式是什么 代理模式是一种设计模式,简单说即是在不改变源码的情况下,实现对目标对象的功能扩展. 比如有个歌手对象叫Singer,这个对象有一个唱歌方法叫sing(). 1 public class ...
- 深入理解java虚拟机(三)-----类加载机制
类加载机制jvm把描述类的数据从class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被jvm直接使用的java类型.在java中,类型的加载.连接和初始化都是在程序运行期间完成的 ...
- 深入理解Java的三种工厂模式
一.简单工厂模式 简单工厂的定义:提供一个创建对象实例的功能,而无须关心其具体实现.被创建实例的类型可以是接口.抽象类,也可以是具体的类 实现汽车接口 public interface Car { S ...
- 虚拟机性能监控与故障处理工具(深入理解java虚拟机三)
JDK自带的工具可以方便的帮助我们处理一些问题,包括查看JVM参数,分析内存变化,查看内存区域,查看线程等信息. 我们熟悉的有java.exe,javac.exe,javap.exe(偶尔用),jps ...
- 深入理解Java虚拟机(三)——垃圾回收策略
所谓垃圾收集器的作用就是回收内存空间中不需要了的内容,需要解决的问题是回收哪些数据,什么时候回收,怎么回收. Java虚拟机的内存分为五个部分:程序计数器.虚拟机栈.本地方法栈.堆和方法区. 其中程序 ...
- 深入理解Java虚拟机(三)、垃圾收集算法
1.第一门真正使用内存动态分配和垃圾收集技术的语言:Lisp 2.程序计数器.虚拟机栈.本地方法栈这3个区域随线程而生灭,这几个区域的内存会随着方法结束或线程结束而回收,GC关注的是Java堆和方法区 ...
- Java复习(三)类中的方法
3.1方法的控制流程 与C/C++类似 3.2异常处理 Java处理错误的方法 抛出(throw)异常 在方法的运行过程中,如果发生了异常,则该方法生成一个代表该异常的代码并把它交给运行时系统,运行时 ...
- 深入理解Java AIO(一)—— Java AIO的简单使用
深入理解Java AIO(一)—— Java AIO的简单使用 深入理解AIO系列分为三个部分 第一部分也就是本节的Java AIO的简单使用 第二部分是AIO源码解析(只解析关键部分)(待更新) 第 ...
随机推荐
- swagger使用以及一些注解说明
@Api:作用于Conntroller类上 value:字段说明 description:描述 tags:分组 (经常用到tags,例如如下,我只是给value,则默认应用了类名) @ApiOpera ...
- Java面试必问之Hashmap底层实现原理(JDK1.7)
1. 前言 Hashmap可以说是Java面试必问的,一般的面试题会问: Hashmap有哪些特性? Hashmap底层实现原理(get\put\resize) Hashmap怎么解决hash冲突? ...
- python随用随学-元类
python中的一切都是对象 按着我的逻辑走: 首先接受一个公理,「python中的一切都是对象」.不要问为什么,吉大爷(Guido van Rossum,python之父)人当初就是这么设计的,不服 ...
- JS 增删改查操作XML
效果图: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <titl ...
- python大佬养成计划----HTML网页设计(序列)
序列化标签 1.有序标签--ol和li 有序列表标签是<ol>,是一个双标签.在每一个列表项目前要使用<li>标签.<ol>标签的形式是带有前后顺序之分的编号.如果 ...
- 十分钟复习CSS盒模型与BFC
css盒模型与BFC 本文为收集整理总结网上资源 旨在系统复习css盒模型与bfc 节省复习时间 阅读10分钟 什么是盒模型 每一个文档中,每个元素都被表示为一个矩形的盒子,它都会具有内容区.padd ...
- 【vue】---- 图片懒加载
1.作用 在图片较多的页面中,页面加载性能较差.使用图片懒加载可以让图片出现在可视区域时再进行加载,从而提高用户体验. 2.原理 设置img标签的src属性为空或统一的图片路径(如加载中样式),监听页 ...
- Effective Go中文版(更新中)
原文链接:https://golang.org/doc/effective_go.html Introduction Go是一种新兴的编程语言.虽然它借鉴了现有语言的思想,但它具有不同寻常的特性,使得 ...
- 吐血干货,直播首屏耗时400ms以下的优化实践
导读: 直播行业的竞争越来越激烈,进过18年这波洗牌后,已经度过了蛮荒暴力期,剩下的都是在不断追求体验.最近在帮做直播优化首开,通过多种方案并行,把首开降到500ms以下,希望能对大家有借鉴. 背景: ...
- typescript package.json vscode 终端 运行任务 Ctrl shift B
{ "dependencies": { "typescript": "^3.6.4" } }