MySQL查询列必须和group by字段一致吗?
@
MySQL版本:8.0.27
场景:查询各部门薪水最高的员工。
CREATE TABLE `employee` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键ID',`dept` int NOT NULL COMMENT '部门',`user` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '员工',`salary` int NULL DEFAULT NULL COMMENT '薪水',`is_deleted` tinyint(1) NOT NULL DEFAULT 0 COMMENT '是否删除',`remark` varchar(512) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '备注',`modify_time` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '修改时间',PRIMARY KEY (`id`) USING BTREE) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '员工' ROW_FORMAT = Dynamic;INSERT INTO `employee` VALUES (1, 1, '张三', 1000, 0, NULL, '2021-12-23 09:20:19.606');INSERT INTO `employee` VALUES (2, 1, '李四', 1500, 0, NULL, '2021-12-23 09:20:21.679');INSERT INTO `employee` VALUES (3, 1, '王五', 2000, 0, NULL, '2021-12-23 09:20:23.371');INSERT INTO `employee` VALUES (4, 2, '赵六', 1000, 0, NULL, '2021-12-23 09:21:59.373');INSERT INTO `employee` VALUES (5, 2, '孙七', 1500, 0, NULL, '2021-12-23 09:22:15.000');
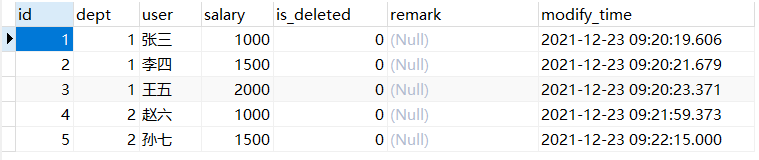
SELECT * FROM employee;
方法一:
SELECTt1.*FROMemployee t1LEFT JOIN employee t2 ON t2.dept = t1.dept AND t1.salary < t2.salaryWHEREt2.salary IS NULL;

方法二:
SELECT*FROM( SELECT * FROM `employee` ORDER BY dept, salary DESC LIMIT 1000 ) tGROUP BYdept;
(不加limit可能会失效)

看起来结果是一样的,但第二种其实会有问题的。
MySQL group by是如何决定哪一条数据留下的?
MySQL通过sql_mode来提供SQL语句的合法性检查,
在默认情况下,MySQL允许查询列target list中出现除了group by column、聚集函数等以外的表达式。
但是,那些不参与group by的字段具体会返回哪条数据的值在MySQL中是处于未定义规则的状态,
MySQL不承诺一定会返回哪条数据。
分组前的数据:
SELECT * FROM employee ORDER BY dept, salary DESC LIMIT 1000;
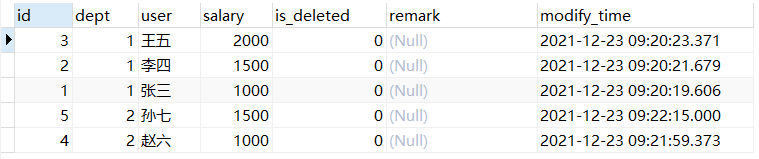
看起来方法二返回的是每个分组中的第一条的数据,
但实际上还会与存储引擎、物理位置、索引等有关,
如果是InnoDB的话,取决于在B+Tree上命中的第一条索引,
这里不展开说明,毕竟不是安全的用法,
有的时候可能返回的结果并不是我们想要的。
关于B+Tree,可以看下这篇文章:
通过B+Tree平衡多叉树理解InnoDB引擎的聚集和非聚集索引
所以对于target list中出现的不明确的列,MySQL是不确定哪一条数据留下的。
对于语法限制比较严格的数据库,都不支持target list中出现语义不明确的列,
MySQL中提供了一个修正的sql_mode,ONLY_FULL_GROUP_BY。
SET SESSION sql_mode = 'ONLY_FULL_GROUP_BY';
再执行方法二的SQL就被拒绝了:
SELECT*FROM( SELECT * FROM `employee` ORDER BY dept, salary DESC LIMIT 1000 ) tGROUP BYdept> 1055 - Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 't.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by> 时间: 0s
'only_full_group_by'模式下MySQL会对target list和group by column中的基础列、表达式、别名列进行严格匹配。
那么target list和group by column不匹配就一定不能执行吗?
我们看下另外一条SQL:
# 订单CREATE TABLE `order` (`order_id` int NOT NULL AUTO_INCREMENT COMMENT '订单ID',`order_amount` int NULL DEFAULT NULL COMMENT '订单金额',PRIMARY KEY (`order_id`) USING BTREE) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '订单' ROW_FORMAT = DYNAMIC;INSERT INTO `order` VALUES (1, 100);INSERT INTO `order` VALUES (2, 103);INSERT INTO `order` VALUES (3, 100);# 订单明细CREATE TABLE `order_detail` (`order_detail_id` int NOT NULL AUTO_INCREMENT COMMENT '主键ID',`order_id` int NOT NULL COMMENT '订单ID',`goods` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品名称',`goods_amount` int NOT NULL COMMENT '商品金额',PRIMARY KEY (`order_detail_id`) USING BTREE) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '订单明细' ROW_FORMAT = DYNAMIC;INSERT INTO `order_detail` VALUES (1, 1, '苹果', 10);INSERT INTO `order_detail` VALUES (2, 1, '橙子', 20);INSERT INTO `order_detail` VALUES (3, 1, '香蕉', 70);INSERT INTO `order_detail` VALUES (4, 2, '橘子', 50);INSERT INTO `order_detail` VALUES (5, 2, '菠萝', 53);
查询订单中所有商品
SELECTt1.order_id,t1.order_amount,GROUP_CONCAT( t2.goods, t2.goods_amount )FROM`order` t1LEFT JOIN order_detail t2 ON t2.order_id = t1.order_idGROUP BYt1.order_id;

这条SQL的target list和group by column并不是严格匹配的,但是也可以执行,
注意
t1.order_id是订单表的主键。
所以在'only_full_group_by'模式下,如果MySQL可以确定target list中所有列的返回值,
那么,即使target list和group by column中的基础列、表达式、别名列等不严格匹配,
MySQL也会认为它的语义是明确的,因此该条语句可以顺利通过。
MySQL查询列必须和group by字段一致吗?的更多相关文章
- mysql 查询结果集按照指定的字段值顺序排序
mysql 查询结果如果不给予指定的order by ,那么mysql会按照主键顺序(innodb引擎)对结果集加以排序,那么最后的排序可能就不是你想要的排序结果. 举个例子,我要按照前端传过来的mo ...
- MySQL查询-分组取组中某字段最大(小)值所有记录
最近做东西的时候,用到一个数据库的查询.将记录按某个字段分组,取每个分组中某个字段的最大值的所有记录.举栗子来说. 已知分数表“score”,包含字段“id", "name&quo ...
- MySql 查询列中包含数据库的关键字
MySQL查询列表中包含数据的关键字的处理办法是用``把关键字包起来(tab键上面的字符)
- mysql 查询 两个表中不同字段的 和,并通过两个表的时间来分组
( SELECT sum( a.cost_sum ) AS sum_cost, sum( a.phone_sum ) AS sum_phone, sum( a.arrive_sum ) AS sum_ ...
- MySQL 查询多张表中相同字段的最大值
MySql : 有N张表,N未知,每张表都有一个字段(id),每张表的字段结构不完全一样,如何查询所有表里面所有id的最大值?如下图所示: 对上面三张表进行操作的话,结果应该为:9 SQL语句: se ...
- mysql查询某个数据库某个表的字段
1.查看字段详细信息 -- 查看详细信息 SELECT COLUMN_NAME "字段名称", COLUMN_TYPE "字段类型长度", IF(EXTRA=& ...
- MYSQL实现列拼接,即同一个字段,多条记录拼接成一条
一.首先,新建三张表 DROP TABLE IF EXISTS `article`; CREATE TABLE `article` ( `id` ) unsigned NOT NULL AUTO_IN ...
- mysql查询用,或#隔开的字段
假如,user表有一字段 pids,pids字段是用#(实际用逗号合适)隔开的师傅id.现在查询师傅id:168的徒弟有哪些(徒弟.徒孙.徒孙的徒弟.徒孙的徒孙....) sql: select * ...
- mysql查询数据库中是否存在某个字段
select table_name from information_schema.columns where table_schema = '库名' and column_name='字段名';
随机推荐
- 《程序员漫画》| 萌新面试Google
Hello,大家好.今天的更新有点不一样.我给大家带来了一些程序员漫画.这些都是我自己画的哦.希望大家喜欢. 今天的漫画有简约的画风,也有一些写实的风格(漂亮MM总是有特殊待遇).不知道大家喜欢哪种呢 ...
- Python画一个四点连线并计算首尾距离
import turtle import math #先定义4个坐标 x1,y1=100,100 x2,y2=100,-100 x3,y3=-100,-100 x4,y4=-100,100 #然后 ...
- Feed系统设计分析(类似微博的用户动态分享问题)
Feed系统 最近在研究一个个人动态分享平台,对动态的推送方式有些疑惑,于是研究到了以下结果. 简介 在信息学里面,Feed其实是一个信息单元,比如一条朋友圈状态.一条微博.一条资讯或一条短视频等,所 ...
- [NOIP2017 提高组] 逛公园
考虑先做一个\(dp\),考虑正反建图,然后按0边拓扑,然后按1到这里的最小距离排序,然后扩展这个\(f_{i,j}\),即多了\(j\)的代价的方案数.
- 洛谷 P4426 - [HNOI/AHOI2018]毒瘤(虚树+dp)
题面传送门 神仙虚树题. 首先考虑最 trival 的情况:\(m=n-1\),也就是一棵树的情况.这个我相信刚学树形 \(dp\) 的都能够秒掉罢(确信).直接设 \(dp_{i,0/1}\) 在表 ...
- DirectX12 3D 游戏开发与实战第十章内容(上)
仅供个人学习使用,请勿转载.谢谢! 10.混合 本章将研究混合技术,混合技术可以让我们将当前需要光栅化的像素(也称为源像素)和之前已经光栅化到后台缓冲区的像素(也称为目标像素)进行融合.因此,该技术可 ...
- spring通过注解注册bean的方式+spring生命周期
spring容器通过注解注册bean的方式 @ComponentScan + 组件标注注解 (@Component/@Service...) @ComponentScan(value = " ...
- R包开发过程记录
目的 走一遍R包开发过程,并发布到Github上使用. 步骤 1. 创建R包框架 Rsutdio --> File--> New Project--> New Directory - ...
- phpMyAdmin简介及安装
phpMyAdmin是一个MySQL数据库管理工具,通过Web接口管理数据库方便快捷. Linux系统安装phpMyAdmin phpMyAdmin是一个MySQL数据库管理工具,通过Web接口管理数 ...
- Python基础之格式化输出的三种方式
目录 1. 格式化输出的三种方式 1.1 占位符 1.2 format格式化 1.3 f-string格式化 1. 格式化输出的三种方式 在程序中,需要将输出信息打印成固定的格式,这时候就需要格式化输 ...