Pytorch AdaptivePooing操作转Pooling操作
Pytorch AdaptivePooing操作转Pooling操作
多数的前向推理框架不支持AdaptivePooing操作,此时需要将AdaptivePooing操作转换为普通的Pooling操作。AdaptivePooling与Max/AvgPooling相互转换提供了一种转换方法,但我在Pytorch1.6中的测试结果是错误的。通过查看Pytorch源码(pytorch-master\aten\src\ATen\native\AdaptiveAveragePooling.cpp)我找出了正确的转换方式。
inline int start_index(int a, int b, int c) {
return (int)std::floor((float)(a * c) / b);
}
inline int end_index(int a, int b, int c) {
return (int)std::ceil((float)((a + 1) * c) / b);
}
template <typename scalar_t>
static void adaptive_avg_pool2d_single_out_frame(
scalar_t *input_p,
scalar_t *output_p,
int64_t sizeD,
int64_t isizeH,
int64_t isizeW,
int64_t osizeH,
int64_t osizeW,
int64_t istrideD,
int64_t istrideH,
int64_t istrideW)
{
at::parallel_for(0, sizeD, 0, [&](int64_t start, int64_t end) {
for (auto d = start; d < end; d++)
{
/* loop over output */
int64_t oh, ow;
for(oh = 0; oh < osizeH; oh++)
{
int istartH = start_index(oh, osizeH, isizeH);
int iendH = end_index(oh, osizeH, isizeH);
int kH = iendH - istartH;
for(ow = 0; ow < osizeW; ow++)
{
int istartW = start_index(ow, osizeW, isizeW);
int iendW = end_index(ow, osizeW, isizeW);
int kW = iendW - istartW;
/* local pointers */
scalar_t *ip = input_p + d*istrideD + istartH*istrideH + istartW*istrideW;
scalar_t *op = output_p + d*osizeH*osizeW + oh*osizeW + ow;
/* compute local average: */
scalar_t sum = 0;
int ih, iw;
for(ih = 0; ih < kH; ih++)
{
for(iw = 0; iw < kW; iw++)
{
scalar_t val = *(ip + ih*istrideH + iw*istrideW);
sum += val;
}
}
/* set output to local average */
*op = sum / kW / kH;
}
}
}
});
}
上述代码段中isizeH,isizeW分别表示输入张量的宽高osizeH,osizeW则表示输出宽高。关注第二个for循环for(oh = 0; oh < osizeH; oh++){.....}中的内容。假设输入的宽高均为223isizeH = isizeW = 223,输出的宽高均为7osizeH = osizeW = 224,然后简单分析一下oh=0,1,2时的情况:
oh=0, istartH = 0, iendH = ceil(223/7)=32, kH = 32oh=1, istartH = floor(223/7) = 31, iendH = ceil(223*2/7)=64, kH = 33oh=2, istartH = floor(223*2/7) = 63, iendH = ceil(223*3/7)=96, kH = 33
这里的kH就是kernel_size的大小. oh=0时的kernel_size比其他情况要小,所以需要在输入上添加padding,让oh=0时的kernel_size与其他情况相同。添加的padding大小为1,等价于让istartH从-1开始,即kH = 32-(-1) = 33. 下一个需要获取的参数是stride,stride = istartH[oh=i]-istartH[oh=i-1], 在上述例子中即为32。按照上述的例子分析输入宽高为224的情况可以发现padding=0,所以padding也是一个需要转换的参数。下面给出3个参数的转换公式:
stride = ceil(input_size / output_size)kernel_size = ceil(2 * input_size / output_size) - floor(input_size / output_size)padding = ceil(input_size / output_size) - floor(input_size / output_size)
在上述的代码中最后部分,可以看见均值使用*op = sum / kW / kH计算得到的。这表明在边缘部分计算均值没有考虑padding,所以对应的AvgPool中的count_include_pad应该设为False。下面贴出我的测试代码:
def test(size):
import numpy as np
import torch
x = torch.randn(1,1,size,size)
input_size = np.array(x.shape[2:])
output_size = np.array([7,7])
# stride = ceil(input_size / output_size)
# kernel_size = ceil(2 * input_size / output_size) - floor(input_size / output_size)
# padding = ceil(input_size / output_size) - floor(input_size / output_size)
stride = numpy.ceil(input_size / output_size).astype(int)
kernel_size = (numpy.ceil(2 * input_size / output_size) - numpy.floor(input_size / output_size)).astype(int)
padding = (numpy.ceil(input_size / output_size) - numpy.floor(input_size / output_size)).astype(int)
print(stride)
print(kernel_size)
print(padding)
avg1 = nn.AdaptiveAvgPool2d(list(output_size))
avg2 = nn.AvgPool2d(kernel_size=kernel_size.tolist(), stride=stride.tolist(), padding=padding.tolist(), ceil_mode=False, count_include_pad=False)
max1 = nn.AdaptiveMaxPool2d(list(output_size))
max2 = nn.MaxPool2d(kernel_size=kernel_size.tolist(), stride=stride.tolist(), padding=padding.tolist(), ceil_mode=False )
avg1_out = avg1(x)
avg2_out = avg2(x)
max1_out = max1(x)
max2_out = max2(x)
print(avg1_out-avg2_out)
print(max1_out-max2_out)
print(torch.__version__)
- inH = inW=224时的输出
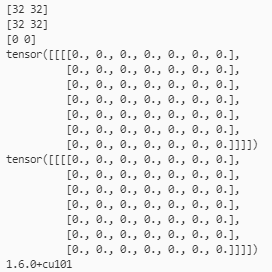
- inH = inW=223时的输出

Pytorch AdaptivePooing操作转Pooling操作的更多相关文章
- python基础操作以及hdfs操作
目录 前言 基础操作 hdfs操作 总结 一.前言 作为一个全栈工程师,必须要熟练掌握各种语言...HelloWorld.最近就被"逼着"走向了python开发之路, ...
- [WCF编程]10.操作:单向操作
一.单向操作概述 WCF提供了单向操作,一旦客户端调用,WCF会生成一个请求,但没有相关的应答信息返回给客户端.所以,单向操作是不能有返回值,服务抛出的任何异常都不会传递给客户端. 理想情况下,一旦客 ...
- Linq查询操作之聚合操作(count,max,min,sum,average,aggregate,longcount)
在Linq中有一些这样的操作,根据集合计算某一单一值,比如集合的最大值,最小值,平均值等等.Linq中包含7种操作,这7种操作被称作聚合操作. 1.Count操作,计算序列中元素的个数,或者计算满足一 ...
- Linq查询操作之排序操作
在Linq中排序操作可以按照一个或多个关键字对序列进行排序.其中第一个排序关键字为主要关键字,第二个排序关键字为次要关键字.Linq排序操作共包含以下5个基本的操作. 1.OrderBy操作,根据排序 ...
- Linq查询操作之投影操作
投影操作,乍一看不知道在说啥.那么什么是投影操作呢?其实就是Select操作,名字起的怪怪的.和Linq查询表达式中的select操作是一样的.它能够选择数据源中的元素,并指定元素的表现形式.投影操作 ...
- Laravel框架数据库CURD操作、连贯操作
这篇文章主要介绍了Laravel框架数据库CURD操作.连贯操作.链式操作总结,本文包含大量数据库操作常用方法,需要的朋友可以参考下 一.Selects 检索表中的所有行 $users = DB::t ...
- Laravel框架数据库CURD操作、连贯操作总结
这篇文章主要介绍了Laravel框架数据库CURD操作.连贯操作.链式操作总结,本文包含大量数据库操作常用方法,需要的朋友可以参考下 一.Selects 检索表中的所有行 复制代码代码如下: $use ...
- IOS文件操作的两种方式:NSFileManager操作和流操作
1.常见的NSFileManager文件方法 -(NSData *)contentsAtPath:path //从一个文件读取数据 -(BOOL)createFileAtPath: path cont ...
- ThinkPHP - 前置操作+后置操作
前置操作和后置操作 系统会检测当前操作(不仅仅是index操作,其他操作一样可以使用)是否具有前置和后置操作,如果存在就会按照顺序执行,前置和后置操作的方法名是在要执行的方法前面加 _before ...
随机推荐
- 遇到奇怪的问题:web.py 0.40中使用web.input(),出现一堆奇怪的错误
有的请求很正常,有的请求就出现了500错误. 这里使用POST请求,然后在web.input()中出现了很长很长的错误. 猜测是这个机器上安装了python2.7 / python 3.6 / pyt ...
- java-异常-异常应用
1 package p1.exception; 2 3 4 /* 5 * 老师用电脑上课. 6 * 7 * 问题领域中涉及两个对象. 8 * 老师,电脑. 9 * 10 * 分析其中的问题. 11 * ...
- 多线程概述(好处和弊端)(jvm多线程解析、主线程运行示例)
1 package multithread; 2 3 /* 4 * 进程:正在进行中的程序(直译). 5 * 6 * 线程:就是进程中一个负责程序执行的控制单元(执行路径). 7 * 一个进程中可以多 ...
- es6 快速入门 系列 —— 类 (class)
其他章节请看: es6 快速入门 系列 类 类(class)是 javascript 新特性的一个重要组成部分,这一特性提供了一种更简洁的语法和更好的功能,可以让你通过一个安全.一致的方式来自定义对象 ...
- 使用 Kubeadm+Containerd 部署一个 Kubernetes 集群
本文独立博客阅读地址:https://ryan4yin.space/posts/kubernetes-deployemnt-using-kubeadm/ 本文由个人笔记 ryan4yin/knowle ...
- 从容器中获取宿主机IP地址
背景: docker 中的程序需要连接外部的程序,连接的过程中会告知外部程序自己的ip地址,然后外部的程序会回连docker中的程序.由于docker使用的是rancher中的托管模式,外部程序是没办 ...
- css3有趣的transform形变
在CSS3中,transform属性应用于元素的2D或3D转换,可以利用transform功能实现文字或图像的旋转.缩放.倾斜.移动这4中类型的形变处理 语法: div{ transform: non ...
- 最大公因数与最小公倍数-gcd&lcm
一.一些性质 \(gcd(a,b)=gcd(b,a)\) \(gcd(-a,b)=gcd(a,b)\) \(gcd(a,a)=|a|, gcd(a,0)=|a|\) \(gcd(a,1)=1\) \( ...
- react 高阶组件的实现
由于强大的mixin功能,在react组件开发过程中存在众多不理于组件维护的因素,所以react社区提出了新的方法来替换mixin,那就是高阶组件: 首先在工程中安装高阶组件所需的依赖: npm in ...
- java实现HTTPS单向认证&TLS指定加密套件
1.HTTPS介绍 由于HTTP是明文传输,会造成安全隐患,所以在一些特定场景中,必须使用HTTPS协议,简单来说HTTPS=HTTP+SSL/TLS.服务端和客户端的信息传输都是通过TLS进行加密. ...