bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html
模块:requests,bs4,queue,sys,time
步骤:给出URL--> 访问URL --> 获取数据 --> 保存数据
第一步:给出URL
百度搜索笔趣阁,进入相关网页,找到自己想要看的小说,如“天下第九”,打开第一章,获得第一章的URL:https://www.52bqg.com/book_113099/37128558.html
第二步:访问URL
def get_content(url):
try:
# 进入主页
# https://www.52bqg.com/
# 随便搜索一步小说,找出变化规律
# https://www.52bqg.com/book_110102/
headers = {
'User-Agent': ""
}
res = requests.get(url=url, headers=headers)
res.encoding = "gbk"
content = res.text
return content
except:
s = sys.exc_info()
print("Error '%s' happened on line %d" % (s[1], s[2].tb_lineno))
return "ERROR"
返回的是此页面的内容
第三步:获取数据
def parseContent(first_url, content):
soup = BeautifulSoup(content, "html.parser")
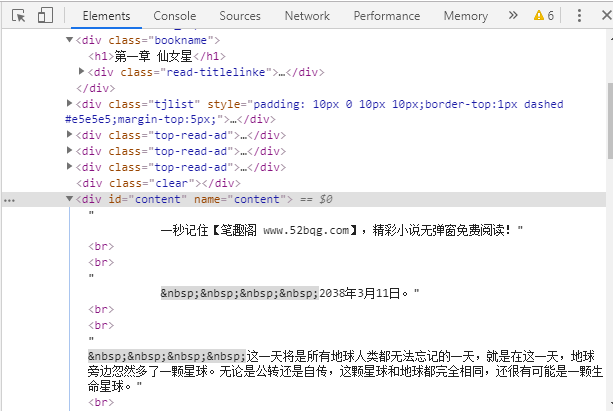
chapter = soup.find(name='div', class_="bookname").h1.text
content = soup.find(name="div", id="content").text
chapter获取的就是每一章的名称,例如:第一章 仙女星
content获取的就是每一章的内容,例如:这一天将是所有地球。。。。
第四步:保存数据
def save(chapter, content):
filename = 文件名字
f = open(filename, "a+", encoding="utf-8")
f.write("".join(chapter) + "\n")
f.write("".join(content.split()[2:]) + "\n")
f.close()
以上就是爬取数据的一般步骤,介绍了一章是如何爬取下来的,那么一本小说,有很多很多章,全部爬取下来的话,就将上面的步骤一次又一次的进行就好了。
这里采取的方法是队列形式,首先给出第一章的url,存放到一个队列中,然后从队列中提取url进行访问,在访问过程中找到第二章的url,放入队列中,然后提取第二个url访问,依次类推,直到将小说所有章节爬取下来,队列为空为止。文件名字这一块,也是通过访问小说的url获取到小说名字,然后以小说名字命名txt的名字。
完整代码如下:
#!/usr/bin/env python
# _*_ coding: UTF-8 _*_
"""=================================================
@Project -> File : Operate_system_ModeView_structure -> get_book_exe.py
@IDE : PyCharm
@Author : zihan
@Date : 2020/4/25 10:28
@Desc :爬取笔趣阁小说: https://www.52bqg.com/
将url放入一个队列中Queue
访问第一章的url得到第二章的url,放入队列,依次类推
=================================================""" import requests
from bs4 import BeautifulSoup
import sys
import time
import queue # 获取内容
def get_content(url):
try:
# 进入主页
# https://www.52bqg.com/
# 随便搜索一步小说,找出变化规律
# https://www.52bqg.com/book_110102/
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
res = requests.get(url=url, headers=headers) # 获取小说目录界面
res.encoding = "gbk"
content = res.text
return content
except:
s = sys.exc_info()
print("Error '%s' happened on line %d" % (s[1], s[2].tb_lineno))
return "ERROR" # 解析内容
def parseContent(q, first_url, content):
base_url_list = first_url.split("/")
html_order = base_url_list[-1]
last_number = first_url.find(html_order)
base_url = first_url[:last_number]
soup = BeautifulSoup(content, "html.parser")
chapter = soup.find(name='div', class_="bookname").h1.text
content = soup.find(name="div", id="content").text
save(base_url, chapter, content)
# 如果存在下一个章节的链接,则将链接加入队列
next1 = soup.find(name='div', class_="bottem").find_all('a')[3].get('href')
if next1 != base_url:
q.put(next1)
# print(next1)
return q def save(base_url, chapter, content):
book_name = get_book_name(base_url)
filename = book_name + ".txt"
f = open(filename, "a+", encoding="utf-8")
f.write("".join(chapter) + "\n")
f.write("".join(content.split()[2:]) + "\n")
f.close() # 获取书名
def get_book_name(base_url):
content = get_content(base_url)
soup = BeautifulSoup(content, "html.parser")
name = soup.find(name='div', class_="box_con").h1.text
return name def main():
first_url = input("请输入小说第一章的链接:")
start_time = time.time() # 进入主页
# https://www.52bqg.com/
# 随便搜索一步小说,找出变化规律
# https://www.52bqg.com/book_110102/
q = queue.Queue()
# 小说第一章链接
# first_url = "https://www.52bqg.com/book_110102/35620490.html"
q.put(first_url)
while not q.empty():
content = get_content(q.get())
q = parseContent(q, first_url, content)
end_time = time.time()
project_time = end_time - start_time
print("下载用时:", project_time) if __name__ == '__main__':
main()
欢迎大家分享一些新发现。
bs4爬取笔趣阁小说的更多相关文章
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 1. 首先导入相关的模块 import os import requests from ...
- scrapycrawl 爬取笔趣阁小说
前言 第一次发到博客上..不太会排版见谅 最近在看一些爬虫教学的视频,有感而发,大学的时候看盗版小说网站觉得很能赚钱,心想自己也要搞个,正好想爬点小说能不能试试做个网站(网站搭建啥的都不会...) 站 ...
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件
前言 首先先介绍一下Jsoup:(摘自官网) jsoup is a Java library for working with real-world HTML. It provides a very ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- 爬虫入门实例:利用requests库爬取笔趣小说网
w3cschool上的来练练手,爬取笔趣看小说http://www.biqukan.com/, 爬取<凡人修仙传仙界篇>的所有章节 1.利用requests访问目标网址,使用了get方法 ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
随机推荐
- mount 挂载操作
windows系统显示光盘内容 光盘文件-------->光驱设备--------->双击访问CD驱动器(访问点) Linux系统显示光盘内容 光盘文件-------->光驱设备-- ...
- 透彻详解(3)旁路电容100nF_0.1uF的由来计算
原文地址点击这里: 前一节我们已经详细解释了旁路电容在数字电路系统中所起的基本且重要作用,即储能与为高频噪声电流提供低阻抗路径,尽管还并未给旁路电容的这些功能概括一个"高大上"的名 ...
- [翻译]在GC上加入DPAD
本文90%通过机器翻译,另外10%译者按照自己的理解进行翻译,和原文相比有所删减,可能与原文并不是一一对应,但是意思基本一致. 译者水平有限,如果错漏欢迎批评指正 译者@Bing Translator ...
- unity的安装,配置,及问题
下载unity 在官网下载unity unity有三个版本,个人版免费,pro和专业版收费. 个人版 在导出exe文件时不能去掉水印片头.其他版本可以. 地址[https://store.unity. ...
- Redis 雪崩、穿透、击穿、并发、缓存讲解以及解决方案
1.缓存雪崩 数据未加载到缓存中,或者缓存同一时间大面积的失效,从而导致所有请求都去查数据库,导致数据库CPU和内存负载过高,甚至宕机. 比如一个雪崩的简单过程 1.redis集群大面积故障 2.缓存 ...
- 运行cmd时提示你可能没有适当的权限访问该项目
Windows无法访问指定设备.路径或文件.你可能没有适当的权限访问该项目. 方法/步骤 在C:\Windows\System32目录下中找到cmd.exe文件 右键点击 "属性 ...
- __sync_fetch_and_add函数(Redis源码学习)
__sync_fetch_and_add函数(Redis源码学习) 在学习redis-3.0源码中的sds文件时,看到里面有如下的C代码,之前从未接触过,所以为了全面学习redis源码,追根溯源,学习 ...
- 如何使用原生的Feign
什么是Feign Feign 是由 Netflix 团队开发的一款基于 Java 实现的 HTTP client,借鉴了 Retrofi. JAXRS-2.0.WebSocket 等类库.通过 Fei ...
- Redis:银河麒麟arm服务器安装redis5.0.3,配置开机自启
百度网盘下载地址 链接:https://pan.baidu.com/s/1f2ghL2-0brPt0IodjfqOqQ提取码:9al1 解压tar包 #解压tar包 tar -xvf arm-r ...
- Linux:Linux操作防火墙命令
首先查看Linux的防火墙是否关闭 firewall-cmd Linux上新用的防火墙软件,跟iptables差不多的工具. firewall-cmd --state # 显示防火墙状态 system ...