HashTable原理和底层实现
1. 概述
上次讨论了HashMap的结构,原理和实现,本文来对Map家族的另外一个常用集合HashTable进行介绍。HashTable和HashMap两种集合非常相似,经常被各种面试官问到两者的区别。
对于两者的区别,主要有以下几点:
- HashMap是非同步的,没有对读写等操作进行锁保护,所以是线程不安全的,在多线程场景下会出现数据不一致的问题。而HashTable是同步的,所有的读写等操作都进行了锁(
synchronized)保护,在多线程环境下没有安全问题。但是锁保护也是有代价的,会对读写的效率产生较大影响。 - HashMap结构中,是允许保存
null的,Entry.key和Entry.value均可以为null。但是HashTable中是不允许保存null的。 - HashMap的迭代器(
Iterator)是fail-fast迭代器,但是Hashtable的迭代器(enumerator)不是fail-fast的。如果有其它线程对HashMap进行的添加/删除元素,将会抛出ConcurrentModificationException,但迭代器本身的remove方法移除元素则不会抛出异常。这条同样也是Enumeration和Iterator的区别。2. 原理
HashTable类中,保存实际数据的,依然是
Entry对象。其数据结构与HashMap是相同的。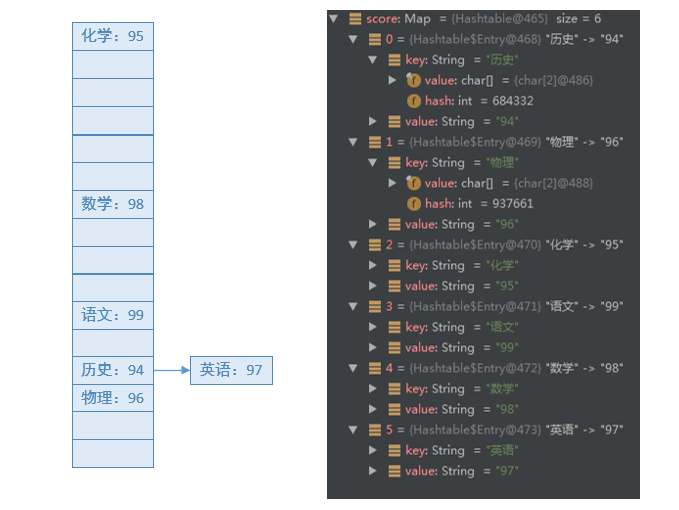
HashTable类继承自Dictionary类,实现了三个接口,分别是Map,Cloneable和java.io.Serializable,如下图所示。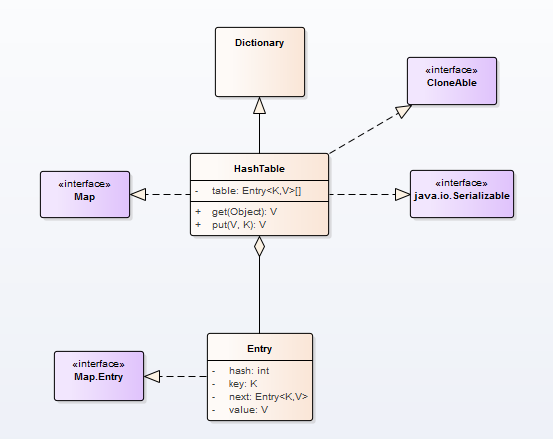
HashTable中的主要方法,如put,get,remove和rehash等,与HashMap中的功能相同,这里不作赘述,可以参考另外一篇文章HashMap原理和底层实现
3. 源码分析
HashTable的主要方法的源码实现逻辑,与HashMap中非常相似,有一点重大区别就是所有的操作都是通过synchronized锁保护的。只有获得了对应的锁,才能进行后续的读写等操作。
1. put方法
put方法的主要逻辑如下:
- 先获取
synchronized锁。 - put方法不允许
null值,如果发现是null,则直接抛出异常。 - 计算
key的哈希值和index - 遍历对应位置的链表,如果发现已经存在相同的hash和key,则更新value,并返回旧值。
- 如果不存在相同的key的Entry节点,则调用
addEntry方法增加节点。 addEntry方法中,如果需要则进行扩容,之后添加新节点到链表头部。
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
} private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}2. get方法
get方法的主要逻辑如下
- 先获取
synchronized锁。 - 计算key的哈希值和index。
- 在对应位置的链表中寻找具有相同hash和key的节点,返回节点的value。
- 如果遍历结束都没有找到节点,则返回
null。
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}3.rehash扩容方法
rehash扩容方法主要逻辑如下:
- 数组长度增加一倍(如果超过上限,则设置成上限值)。
- 更新哈希表的扩容门限值。
- 遍历旧表中的节点,计算在新表中的index,插入到对应位置链表的头部。
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}4.remove方法
remove方法主要逻辑如下:
- 先获取synchronized锁。
- 计算key的哈希值和index。
- 遍历对应位置的链表,寻找待删除节点,如果存在,用
e表示待删除节点,pre表示前驱节点。如果不存在,返回null。 - 更新前驱节点的
next,指向e的next。返回待删除节点的value值。
4. 总结
HashTable相对于HashMap的最大特点就是线程安全,所有的操作都是被synchronized锁保护的
作者:道可
链接:https://www.imooc.com/article/details/id/23015
来源:慕课网
本文原创发布于慕课网 ,转载请注明出处,谢谢合作
HashTable原理和底层实现的更多相关文章
- Android摄像头:只拍摄SurfaceView预览界面特定区域内容(矩形框)---完整(原理:底层SurfaceView+上层绘制ImageView)
Android摄像头:只拍摄SurfaceView预览界面特定区域内容(矩形框)---完整实现(原理:底层SurfaceView+上层绘制ImageView) 分类: Android开发 Androi ...
- HashMap与HashTable原理及数据结构
HashMap与HashTable原理及数据结构 hash表结构个人理解 hash表结构,以计算出的hashcode或者在hashcode基础上加工一个hash值,再通过一个散列算法 获取到对应的数组 ...
- java8 HashTable 原理
HashTable原理 Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现.Hashtable中的方法是同步的,而HashMap方法(在 ...
- HashMap的实现原理和底层数据结构
看了下Java里面有HashMap.Hashtable.HashSet三种hash集合的实现源码,这里总结下,理解错误的地方还望指正 HashMap和Hashtable的区别 HashSet和Hash ...
- Git 内部原理 - (1)底层命令和高层命令 (2Git 对象
文章摘选自git官网,这里复制下来表示我已阅读并学习过一次这些内容: 无论是从之前的章节直接跳到本章,还是读完了其余章节一直到这——你都将在本章见识到 Git 的内部工作原理和实现方式. 我们发现学习 ...
- Java集合详解(五):Hashtable原理解析
概述 本文是基于jdk8_271版本进行分析的. Hashtable与HashMap一样,是一个存储key-value的双列集合.底层是基于数组+链表实现的,没有红黑树结构.Hashtable默认初始 ...
- <TCP/IP原理> (三) 底层网络技术
传输介质 局域网(LAN) 交换(Switching) 广域网(WAN) 连接设备 第三章 底层网络技术 引言 1)Interne不是一种新的网络 建立在底层网络上的网际网 底层网络——“物理网”,网 ...
- HashTable原理与源码分析
本文版权归 远方的风lyh和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作,如有错误之处忘不吝批评指正! HashTable内部存储结构 HashTable内部存储结构为数组+单向链 ...
- 五.HashTable原理及实现学习总结
有两个类都提供了一个多种用途的hashTable机制,他们都可以将可以key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相对应的valu ...
随机推荐
- 痞子衡嵌入式:了解i.MXRTxxx系列ROM中灵活的串行NOR Flash启动硬复位引脚选择
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MXRTxxx系列ROM中灵活的串行NOR Flash启动硬复位引脚选择. 关于 i.MXRT 系列 BootROM 中串行 NOR ...
- UBUNTU 16.04 LTS SERVER 手动升级 MariaDB 到最新版 10.2
UBUNTU 16.04 LTS SERVER 手动升级 MariaDB 到最新版 10.2 1. 起因 最近因为不同软件的数据问题本来只是一些小事弄着弄着就越弄越麻烦了,期间有这么个需求,没看到有中 ...
- SpringBoot读取Resource下文件的几种方式(十五)
需求:提供接口下载resources目录下的模板文件,(或者读取resources下的文件)给后续批量导入数据提供模板文件. 方式一:ClassPathResource //获取模板文件:注意此处需要 ...
- tomcat默认端口
关于tomcat默认端口为8080: 网页浏览器的默认端口为80.
- 5G[generation]的知识收集
一.什么是5G? G的英文是"5 Generation",即第五代无线通讯系统. 二.发展历程 1G的速率只有2.4k.2G是64k.3G是2M.4G{2013年12月,我国第四代 ...
- TypeError: attrib() got an unexpected keyword argument 'convert'
使用pyinstaller -F aaa.py时,报错 TypeError: attrib() got an unexpected keyword argument 'convert' 没有exe生成 ...
- 第二十四篇 -- Cache学习
Cache存储器 电脑中为高速缓冲存储器,是位于CPU和主存储器DRAM(Dynamic Random Access Memory)之间,规模较小,但速度很高的存储器,通常由SRAM(Static R ...
- Flask 之db 配置坑
文件 .flaskenv中 DATABASE_URI = 'mysql://username:password@server/db' flask db init 报错 ImportError: No ...
- JS_点击事件_弹出窗口_自动消失
<!doctype html> <html> <head> <meta charset="utf-8"/> <title> ...
- Go interface 原理剖析--类型转换
hi, 大家好,我是 haohognfan. 可能你看过的 interface 剖析的文章比较多了,这些文章基本都是从汇编角度分析类型转换或者动态转发.不过随着 Go 版本升级,对应的 Go 汇编也发 ...