大数据学习(19)—— Flume环境搭建
系统要求
- Java1.8或以上
- 内存要足够大
- 硬盘足够大
- Agent对源和目的要有读写权限
Flume部署
我这8G内存的电脑之前搭建Hadoop、Hive和HBase已经苟延残喘了,怀疑会卡死,硬着头皮上吧。先解压缩,大数据的这些产品都是一个部署套路。
我准备在server01上部署flume,单节点就可以了。在公司生产环境部署要考虑高可用。
[root@server01 home]# tar -xvf apache-flume-1.9.0-bin.tar.gz -C /usr
[root@server01 home]# cd /usr
[root@server01 usr]# chown -R hadoop:hadoop apache-flume-1.9.0-bin/
[root@server01 usr]# mv apache-flume-1.9.0-bin/ apache-flume-1.9.0
在profile文件中添加配置
FLUME_HOME=/usr/apache-flume-1.9.0/
PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:$FLUME_HOME/bin
刷新配置文件
[root@server01 bin]# source /etc/profile
修改flume配置文件
[hadoop@server01 conf]$ pwd
/usr/apache-flume-1.9.0/conf
[hadoop@server01 conf]$ mv flume-env.sh.template flume-env.sh
[hadoop@server01 conf]$ vi flume-env.sh
把flume-env.sh里的JAVA_HOME修改为绝对路径
export JAVA_HOME=/usr/java/jdk1.8.0
Flume启动
我们试一下通过网络端口写入数据。新建一个配置文件。
[hadoop@server01 conf]$ vi config1
数据流向:telent -> source -> channel -> sink -> logger
具体配置内容如下。
[hadoop@server01 conf]$ cat config1
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = server01
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume。注意flume1.0以后叫ng(next generation),之前叫og(original generation)。
[hadoop@server01 apache-flume-1.9.0]$ flume-ng agent --conf conf --conf-file conf/config1 --name a1 -Dflume.root.logger=INFO,console
启动之后,另开server02对44444端口发送数据。
[hadoop@server02 ~]$ telnet server01 44444
Trying 182.182.0.8...
Connected to server01.
Escape character is '^]'.
hello
OK
thank you
OK
thank you very much
OK
how are you everyone
OK
看看server01控制台输出了啥。
2021-01-07 11:17:14,198 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
2021-01-07 11:18:24,209 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 68 61 6E 6B 20 79 6F 75 0D thank you. }
2021-01-07 11:18:34,088 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 68 61 6E 6B 20 79 6F 75 20 76 65 72 79 20 6D thank you very m }
2021-01-07 11:18:51,602 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 6F 77 20 61 72 65 20 79 6F 75 20 65 76 65 72 how are you ever }
我们可以看到,控制台只会输出前面几个字节的内容,但是信息已经获取到了。
再来一个例子
上面是一个最简单的例子,从网络端口获取数据,输出到控制台。再来一个复杂一点的,从日志文件获取增量数据,写入HDFS。
做过开发的都清楚用tail -f filename来查看最新的请求日志,配置文件新建config2,内容如下。
[hadoop@server01 conf]$ cat config2
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/log.txt # Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://mycluster/flume
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d
a1.sinks.k1.hdfs.useLocalTimeStamp = true # Use a channel which buffers events in file
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动hdfs,用上面的配置文件启动flume。
[hadoop@server01 apache-flume-1.9.0]$ flume-ng agent --name a1 --conf conf --conf-file conf/config2 -Dflume.root.logger=INFO,console
启动报错。
2021-01-07 19:19:51,905 (SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459)] process failed
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1380)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1361)
at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1703)
at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:221)
at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:572)
at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:748)
Exception in thread "SinkRunner-PollingRunner-DefaultSinkProcessor" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1380)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1361)
at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1703)
at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:221)
at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:572)
at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:748)
这跟Hive启动错误是一样的,原因就是与Hadoop的guava包版本不一致。把Hadoop的jar包拷到Flume路径下,删除老的jar包。在Flume的lib目录执行如下命令。
[hadoop@server01 lib]$ cp /usr/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar .
[hadoop@server01 lib]$ ll|grep guava
-rw-rw-r--. 1 hadoop hadoop 1648200 9月 13 2018 guava-11.0.2.jar
-rw-r--r--. 1 hadoop hadoop 2747878 1月 12 11:42 guava-27.0-jre.jar
[hadoop@server01 lib]$ rm guava-11.0.2.jar
[hadoop@server01 lib]$ ll|grep guava
-rw-r--r--. 1 hadoop hadoop 2747878 1月 12 11:42 guava-27.0-jre.jar
再次启动Flume。启动完毕后,模拟向/home/log.txt写入数据,中间间隔一段时间。
[root@server01 home]# echo "hello,thank you,thank you very much" >> log.txt
[root@server01 home]# echo "How are you Indian Mi fans?" >> log.txt
再去看看HDFS生成的文件里有什么内容。
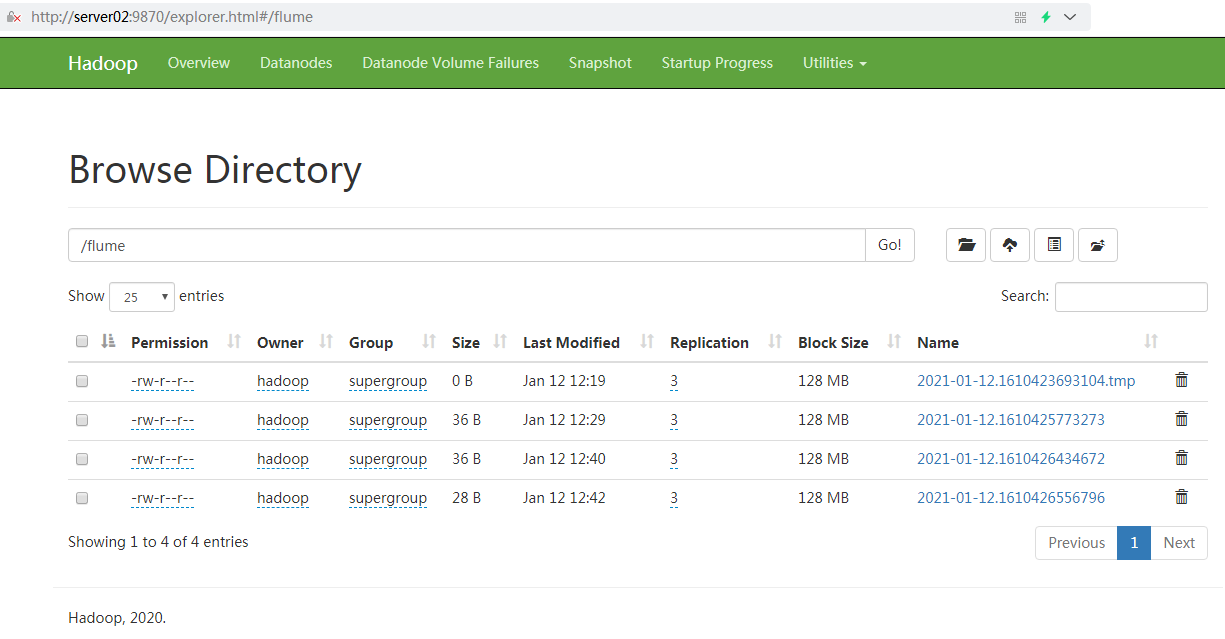
打开下面的两个文件,看看内容。原谅我不厚道地用了雷总歌词。
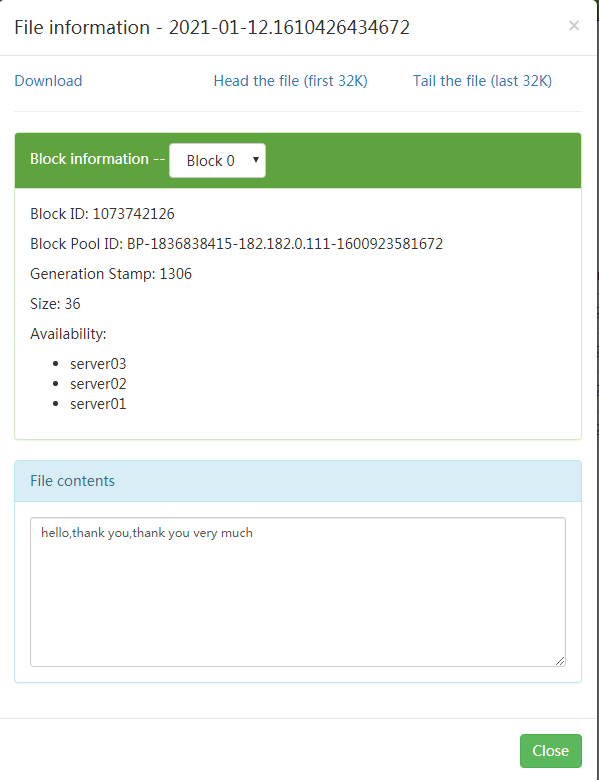
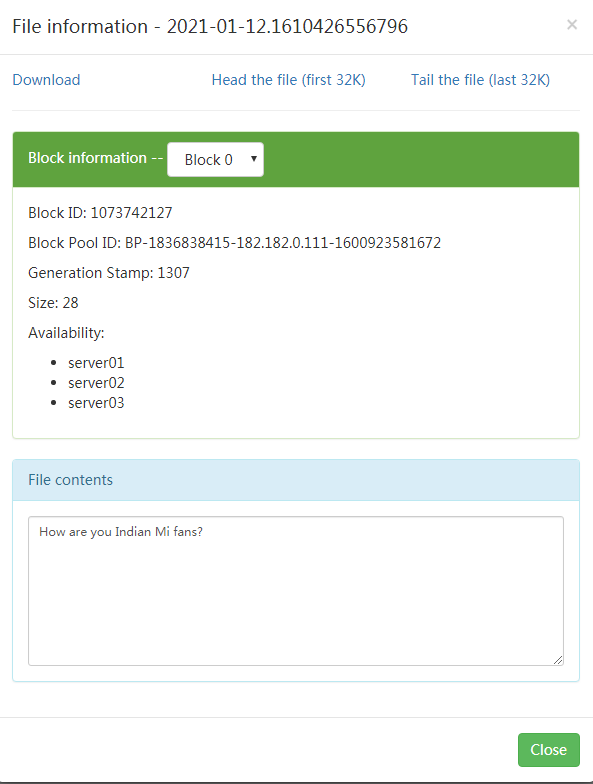
这样就把日志收集到HDFS了,后续可以通过MR任务来处理HDFS文件,提取需要的内容。
大数据学习(19)—— Flume环境搭建的更多相关文章
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- 《OD大数据实战》Flume环境搭建
一.CentOS 6.4安装Nginx http://shiyanjun.cn/archives/72.html 二.安装Flume 1. 下载flume-ng-1.5.0-cdh5.3.6.tar. ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 【原创干货】大数据Hadoop/Spark开发环境搭建
已经自学了好几个月的大数据了,第一个月里自己通过看书.看视频.网上查资料也把hadoop(1.x.2.x).spark单机.伪分布式.集群都部署了一遍,但经历短暂的兴奋后,还是觉得不得门而入. 只有深 ...
- 《OD大数据实战》MongoDB环境搭建
一.MongonDB环境搭建 1. 下载 https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz 2. 解压 tar -zxvf ...
- 《OD大数据实战》Hue环境搭建
官网: http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/ 一.Hue环境搭建 1. 下载 http://archive.cloude ...
- 大数据学习之路—环境配置——IP设置(虚拟机修改Ip的内在原因及实现)
一.IP原理 关于IP我的理解, (1)主要去理解IP地址的作用,IP地址包括网络相关部分和主机的相关部分.即:用一段特殊的数据,来标识网络特征和主机的特征. 至于具体的技术实现,日后可以慢慢体会和了 ...
- 《OD大数据实战》Storm环境搭建
一.环境搭建 1. 下载 http://www.apache.org/dyn/closer.lua/storm/apache-storm-0.9.6/apache-storm-0.9.6.tar.gz ...
随机推荐
- Ubuntu安装ibmmq
一.前言 安装整个ibmmq的过程中,真的气炸了,在网上搜索到的答案千篇一律,一个安装部署文档居然没有链接地址:为了找到这个开发版本的下载地址找了一下午,不容易啊.也提醒了自己写博文还是得有责任心,把 ...
- Qt之先用了再说系列-信号与槽
QT之信号与槽 简介:信号与槽可是Qt最大成功点,也是整个Qt基本核心机制,如果不会信号与槽,将无法领略Qt之美: 1.信号与槽函数原型: QObject::connect(const QObject ...
- CentOS8安装GNOME3桌面并设置开机启动图形界面
本篇文章介绍如何在CentOS8 Linux操作系统中安装GNOME3桌面环境和GDM(GNOME Display Manager)现实环境管理器. 环境 CentOS8 Minimal 安装GNOM ...
- 并发王者课-铂金10:能工巧匠-ThreadLocal如何为线程打造私有数据空间
欢迎来到<并发王者课>,本文是该系列文章中的第23篇,铂金中的第10篇. 说起ThreadLocal,相信你对它的名字一定不陌生.在并发编程中,它有着较高的出场率,并且也是面试中的高频面试 ...
- powerpoint2013去掉图片背景,转存png
1.打开powerpoint,点击菜单栏的[插入],如图: 2.点击『图像』,如图: 3.上传图片,如图: 4.上传的图片不是png的,现在需要去掉白色背景,保存成png,选中图片,点击菜单栏的『格式 ...
- 前端集合传参,springmvc后端如何接收
废话不多说,上代码 后端接收对象: class ObjectA{ private String a; private String b; private List<ObjectB> lis ...
- nmon打开nmon文件出现 运行时错误13类型不匹配问题解决
根据nmon工具安装及nmon analyser的使用 - 空谷幽兰LDD - 博客园 (cnblogs.com)文中,用nmon_analyse去打开监控到的nmon文件,出几个报错. 1 用WPS ...
- ESP-IDF硬件设计相关知识
1.更新ESP-IDF:直接删除您本地的 esp-idf 文件夹,然后克隆新版本:更新完成后,请执行 install.sh (Windows 系统中为 install.bat)脚本,避免新版 ESP- ...
- ESP32省电模式连接WIFI笔记
基于ESP-IDF4.1版本 main.c文件如下: #include <string.h> #include "freertos/FreeRTOS.h" #inclu ...
- LeetCode解题记录(贪心算法)(二)
1. 前言 由于后面还有很多题型要写,贪心算法目前可能就到此为止了,上一篇博客的地址为 LeetCode解题记录(贪心算法)(一) 下面正式开始我们的刷题之旅 2. 贪心 763. 划分字母区间(中等 ...