利用python爬取全国水雨情信息
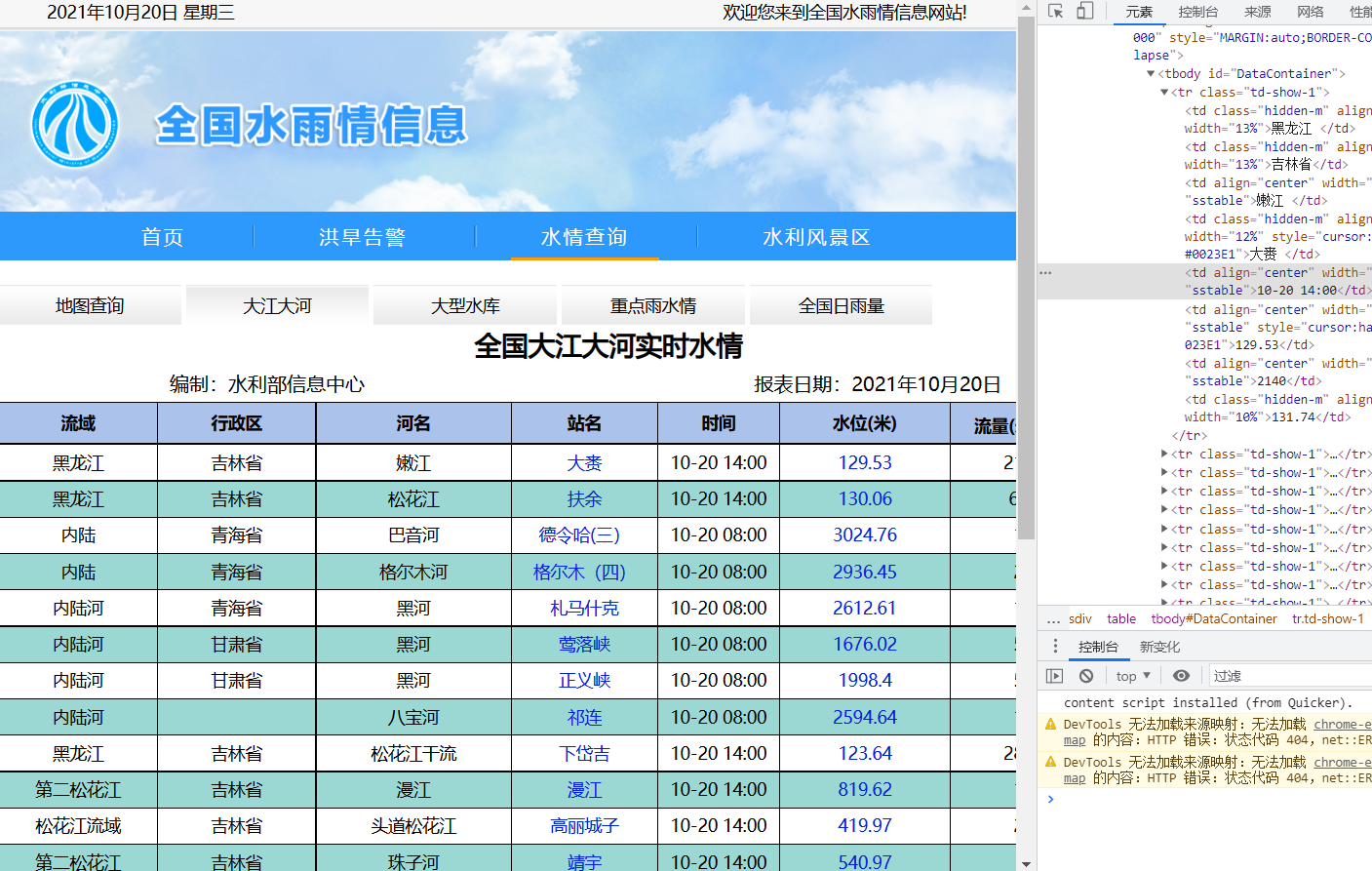
分析
我们没有找到接口,所以打算利用selenium来爬取。
代码
import datetime
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options #建议使用谷歌浏览器
import time
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome()
# 存储中英文对应的变量的中文名
word_dict = {"poiBsnm": "流域",
"poiAddv": "行政区",
"rvnm": "河名",
"stnm": "站名",
"tm": "时间",
"zl": "水位(米)",
"ql": "流量(立方米/秒)",
"wrz": "警戒水位(米)"}
# 空df接收结果
rain_total = pd.DataFrame([])
url = 'http://xxfb.mwr.cn/sq_dxsk.html'
driver.get(url)
time.sleep(5)
infos = driver.find_elements_by_xpath("/html/body//tbody[@id='DataContainer']/tr")
# pd.set_option('display.max_columns', None)#所有列
# pd.set_option('display.max_rows', None)#所有行
# 列表提取
for info in infos:
poiBsnm = info.find_element_by_xpath("./td[1]").text
poiAddv = info.find_element_by_xpath("./td[2]").text
rvnm = info.find_element_by_xpath("./td[3]").text
stnm = info.find_element_by_xpath("./td[4]").text
tm = info.find_element_by_xpath("./td[5]").text
zl = info.find_element_by_xpath("./td[6]").text
ql = info.find_element_by_xpath("./td[7]").text
wrz = info.find_element_by_xpath("./td[8]").text
# 组成pandas对象
rain_data = [[poiBsnm,poiAddv,rvnm,stnm,tm,zl,ql,wrz]]
rain_df = pd.DataFrame(data=rain_data,columns=list(word_dict.values()))
rain_total = pd.concat([rain_total,rain_df])
print(rain_total)
# 关闭浏览器
driver.close()
# 保存数据
data_str = datetime.datetime.now().strftime('%Y_%m_%d')
rain_total.to_csv("%s_全国水雨情信息.csv" % (data_str),index=None, encoding="GB18030")
结果
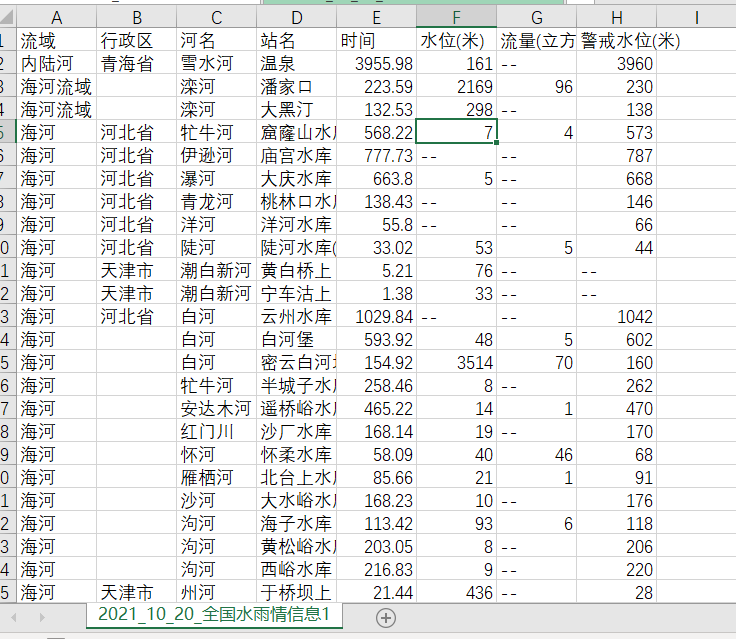
反思
时间爬取出现了一点问题,我也很不理解,其次,循环哪里应该可以简洁代码,写的不是很好,第三,没有形成模块化的代码。还有就是谢谢崔工的支持。
利用python爬取全国水雨情信息的更多相关文章
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- python爬取 “得到” App 电子书信息
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 静觅 崔庆才 PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- Python爬取房天下二手房信息
一.相关知识 BeautifulSoup4使用 python将信息写入csv import csv with open("11.csv","w") as csv ...
随机推荐
- 搭建私服仓库:(一)Windows安装Nuxus
Nexus下载 官网.官网下载.百度云盘 提取码:su33 将nexus下载下来,以2.14.5的windows版本为例子(3.x暂时下载不下来,迅雷会员都不行) 下载后进行解压,得到以下目录: 其中 ...
- Python - 进度条库 tqdm
前言 在写生成器的时候,网上看到一个进度条库,感觉蛮有意思,记录下 这个库感觉只有在调试的时候会用到,不做深入学习 内置库,不需要安装 示例代码 from tqdm import tqdm for i ...
- 《通过刷leetcode学习Go语言》之(1):序言
Author : Email : vip_13031075266@163.com Date : 2021.03.07 Version : 北京 C ...
- container of()函数简介
在linux 内核编程中,会经常见到一个宏函数container_of(ptr,type,member), 但是当你通过追踪源码时,像我们这样的一般人就会绝望了(这一堆都是什么呀? 函数还可以这样定义 ...
- 第09课:GDB 实用调试技巧(下)
本节课的核心内容: 多线程下禁止线程切换 条件断点 使用 GDB 调试多进程程序 多线程下禁止线程切换 假设现在有 5 个线程,除了主线程,工作线程都是下面这样的一个函数: void thread_p ...
- AI:用软件逻辑做硬件爆款
"我们的野心不止那么一点点." 百度集团副总裁.百度智能生活事业群组(SLG)总经理.小度CEO景鲲曾多次对外表达过这样的观点. 在2021年百度世界大会上,小度又一口气发布了四款 ...
- Linux内核下包过滤框架——iptables&netfilter
iptables & netfilter 1.简介 netfilter/iptables(下文中简称为iptables)组成Linux内核下的包过滤防火墙,完成封包过滤.封包重定向和网络地址转 ...
- 【Nginx】Linux常用命令------启动、停止、重启
启动 启动代码格式:nginx安装目录地址 -c nginx配置文件地址 例如: [root@LinuxServer sbin]# /usr/local/nginx/sbin/nginx -c /us ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- 关于goto
(下面一段来源<征服C指针>) 75: ReadLineStatus read_line(FILE *fp, char **line) 76: { 77: int ch; 78: Read ...