Hive面试题整理(一)
1、Hive表关联查询,如何解决数据倾斜的问题?(☆☆☆☆☆)
1)倾斜原因:map输出数据按key Hash的分配到reduce中,由于key分布不均匀、业务数据本身的特、建表时考虑不周、等原因造成的reduce 上的数据量差异过大。
(1)key分布不均匀;
(2)业务数据本身的特性;
(3)建表时考虑不周;
(4)某些SQL语句本身就有数据倾斜;
如何避免:对于key为空产生的数据倾斜,可以对其赋予一个随机值。
2)解决方案
(1)参数调节:
hive.map.aggr = true
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定位true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作。
(2)SQL 语句调节:
① 选用join key分布最均匀的表作为驱动表。做好列裁剪和filter操作,以达到两表做join 的时候,数据量相对变小的效果。
② 大小表Join:
使用map join让小的维度表(1000 条以下的记录条数)先进内存。在map端完成reduce。
③ 大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null 值关联不上,处理后并不影响最终结果。
④ count distinct大量相同特殊值:
count distinct 时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
2、Hive的HSQL转换为MapReduce的过程?(☆☆☆☆☆)
HiveSQL ->AST(抽象语法树) -> QB(查询块) ->OperatorTree(操作树)->优化后的操作树->mapreduce任务树->优化后的mapreduce任务树
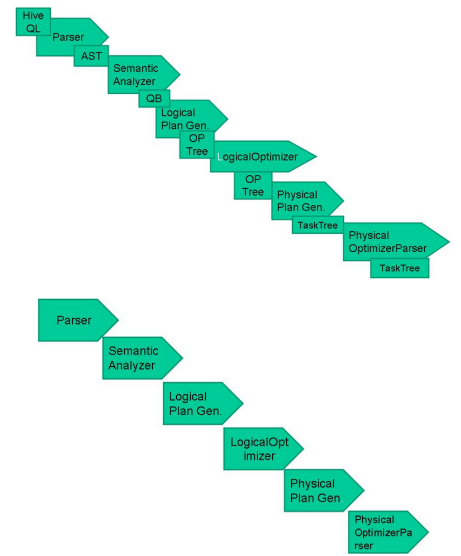
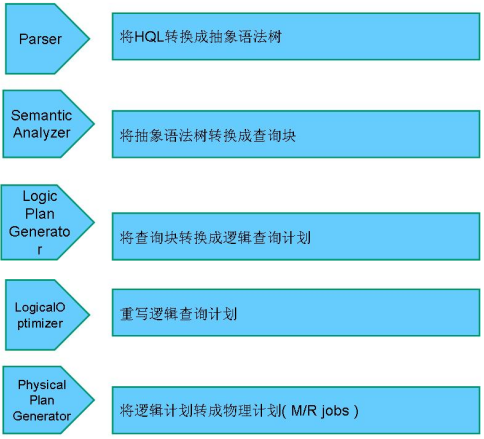
过程描述如下:
SQL Parser:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree;
Semantic Analyzer:遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
Logical plan:遍历QueryBlock,翻译为执行操作树OperatorTree;
Logical plan optimizer: 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
Physical plan:遍历OperatorTree,翻译为MapReduce任务;
Logical plan optimizer:物理层优化器进行MapReduce任务的变换,生成最终的执行计划。
3、Hive底层与数据库交互原理?(☆☆☆☆☆)
由于Hive的元数据可能要面临不断地更新、修改和读取操作,所以它显然不适合使用Hadoop文件系统进行存储。目前Hive将元数据存储在RDBMS中,比如存储在MySQL、Derby中。元数据信息包括:存在的表、表的列、权限和更多的其他信息。
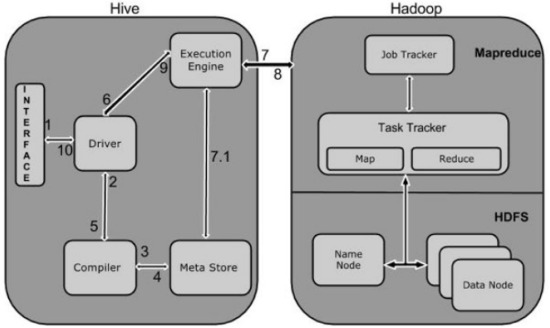
4、Hive的两张表关联,使用MapReduce怎么实现?(☆☆☆☆☆)
如果其中有一张表为小表,直接使用map端join的方式(map端加载小表)进行聚合。
如果两张都是大表,那么采用联合key,联合key的第一个组成部分是join on中的公共字段,第二部分是一个flag,0代表表A,1代表表B,由此让Reduce区分客户信息和订单信息;在Mapper中同时处理两张表的信息,将join on公共字段相同的数据划分到同一个分区中,进而传递到一个Reduce中,然后在Reduce中实现聚合。
5、请谈一下Hive的特点,Hive和RDBMS有什么异同?
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析,但是Hive不支持实时查询。
Hive与关系型数据库的区别:
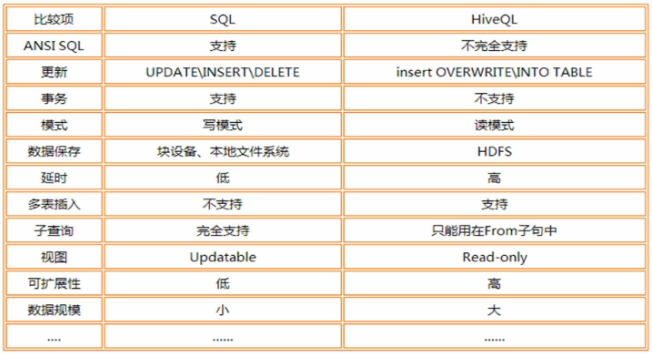
6、请说明hive中 Sort By,Order By,Cluster By,Distrbute By各代表什么意思?
order by:会对输入做全局排序,因此只有一个reducer(多个reducer无法保证全局有序)。只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
sort by:不是全局排序,其在数据进入reducer前完成排序。
distribute by:按照指定的字段对数据进行划分输出到不同的reduce中。
cluster by:除了具有 distribute by 的功能外还兼具 sort by 的功能。
7、写出hive中split、coalesce及collect_list函数的用法(可举例)?
split将字符串转化为数组,即:split('a,b,c,d' , ',') ==> ["a","b","c","d"]。
coalesce(T v1, T v2, …) 返回参数中的第一个非空值;如果所有值都为 NULL,那么返回NULL。
collect_list列出该字段所有的值,不去重 => select collect_list(id) from table。
8、Hive有哪些方式保存元数据,各有哪些特点?
Hive支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元存储服务器、远程元存储服务器,每种存储方式使用不同的配置参数。
内嵌式元存储主要用于单元测试,在该模式下每次只有一个进程可以连接到元存储,Derby是内嵌式元存储的默认数据库。
在本地模式下,每个Hive客户端都会打开到数据存储的连接并在该连接上请求SQL查询。
在远程模式下,所有的Hive客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift协议通信。
9、Hive内部表和外部表的区别?
创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
删除表时:在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
10、Hive 中的压缩格式TextFile、SequenceFile、RCfile 、ORCfile各有什么区别?
1、TextFile
默认格式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,压缩后的文件不支持split,Hive不会对数据进行切分,从而无法对数据进行并行操作。并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
2、SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,存储方式为行存储,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
优势是文件和hadoop api中的MapFile是相互兼容的
3、RCFile
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低;
其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取;
4、ORCFile
存储方式:数据按行分块 每块按照列存储。
压缩快、快速列存取。
效率比rcfile高,是rcfile的改良版本。
总结:相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。
数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
11、所有的Hive任务都会有MapReduce的执行吗?
不是,从Hive0.10.0版本开始,对于简单的不需要聚合的类似SELECT from LIMIT n语句,不需要起MapReduce job,直接通过Fetch task获取数据。
12、Hive的函数:UDF、UDAF、UDTF的区别?
UDF:单行进入,单行输出
UDAF:多行进入,单行输出
UDTF:单行输入,多行输出
13、说说对Hive桶表的理解?
桶表是对数据进行哈希取值,然后放到不同文件中存储。
数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。物理上,每个桶就是表(或分区)目录里的一个文件,一个作业产生的桶(输出文件)和reduce任务个数相同。
桶表专门用于抽样查询,是很专业性的,不是日常用来存储数据的表,需要抽样查询时,才创建和使用桶表。
Hive面试题整理(一)的更多相关文章
- 【web前端面试题整理06】成都第一弹,邂逅聚美优品
前言 上周四回了成都,休息了一下下,工作问题还是需要解决的,于是今天去面试了一下,现在面试回来了,我感觉还是可以整理一下心得. 这个面试题整理系列是为了以后前端方面的兄弟面试时候可以得到一点点帮助,因 ...
- C++ 面试题整理
我和朋友们面到的c++试题整理 虚表 static const sizeof 可构造不可继承的类 stl Iterator失效 map vector vector的removed_if 优化 ---- ...
- Touch事件or手机卫士面试题整理回答(二)
Touch事件or手机卫士面试题整理回答(二) 自定义控件 1. Touch事件的传递机制 顶级View->父View->子View,不处理逆向返回 OnInterceptTouchEve ...
- 尚学堂Java面试题整理
博客分类: 经典分享 1. super()与this()的差别? - 6 - 2. 作用域public,protected,private,以及不写时的差别? - 6 - 3. 编程输出例如以 ...
- 【JAVA面试】java面试题整理(4)
版权声明:转载请注明 https://blog.csdn.net/qq_33591903/article/details/83473779 ...
- 北京Java笔试题整理
北京Java笔试题整理 1.什么是java虚拟机?为什么ava被称作是"平台无关的编程语言? 答:Java虚拟机可以理解为一个特殊的"操作系统",只是它连接的不是硬件,而 ...
- Java笔试面试题整理第八波
转载至:http://blog.csdn.net/shakespeare001/article/details/51388516 作者:山代王(开心阳) 本系列整理Java相关的笔试面试知识点,其他几 ...
- Java笔试面试题整理第六波(修正版)
转载至:http://blog.csdn.net/shakespeare001/article/details/51330745 作者:山代王(开心阳) 本系列整理Java相关的笔试面试知识点,其他几 ...
- Java笔试面试题整理第五波
转载至:http://blog.csdn.net/shakespeare001/article/details/51321498 作者:山代王(开心阳) 本系列整理Java相关的笔试面试知识点,其他几 ...
随机推荐
- 20210803 noip29
考场 第一次在 hz 考试.害怕会困,但其实还好 看完题感觉不太难,估计有人 AK. T3 比较套路,没办法枚举黑点就从 LCA 处考虑,在一个点变成黑点时计算其他点和它的 LCA 的贡献,暴力跳父亲 ...
- 基于Ubuntu18.04一站式部署(python-mysql-redis-nginx)
基于Ubuntu18.04一站式部署 Python3.6.8的安装 1. 安装依赖 ~$ sudo apt install openssl* zlib* 2. 安装python3.6.8(个人建议从官 ...
- Mybatis-基本学习(下)
四,MAP的使用--超常用 思考:多表连接查询怎么做?---MAP的好处!---返回List
- wrap()包裹被选元素的内容
<!doctype html><html><head><meta charset="utf-8"><title>修改代码 ...
- jq给动态标签绑定事件
$(document).on("click", ".autocompleteDiv .autocomplete_ul li", function () { lo ...
- LVS+keepalived集群
一.Keepalived工具介绍专为LVS和HA设计的一款健康检查工具 支持故障自动切换(Failover) 支持节点健康状态检查(Health Checking) 官方网站:http://www.k ...
- 常见shell脚本测试题 if/case语句
1.检查用户家目录中的 test.sh 文件是否存在,并且检查是否有执行权限2.提示用户输入100米赛跑的秒数,要求判断秒数大于0且小于等于10秒的进入选拔赛,大于10秒的都淘汰,如果输入其它字符则提 ...
- 小狐狸钱包怎么使用?MetaMask(小狐狸) 使用教程 - 如何添加BSC链、Heco链
MetaMask介绍 MetaMask是一款在谷歌浏览器Chrome上使用的插件类型的以太坊钱包,只需要在谷歌浏览器添加对应的扩展程序即可使用. 1.Download & Install: 官 ...
- docker run配置参数
Usage: docker run [OPTIONS] IMAGE [COMMAND] [ARG...] -d, --detach=false 指定容器运行于前台还是后台,默认为false -i, - ...
- PHP中的PDO对象操作学习(一)初始化PDO及原始SQL语句操作
PDO 已经是 PHP 中操作数据库事实上的标准.包括现在的框架和各种类库,都是以 PDO 作为数据库的连接方式.基本上只有我们自己在写简单的测试代码或者小的功能时会使用 mysqli 来操作数据库. ...