Sequence Model-week2编程题1-词向量的操作【余弦相似度 词类比 除偏词向量】
1. 词向量上的操作(Operations on word vectors)
因为词嵌入的训练是非常耗资源的,所以ML从业者通常 都是 选择加载训练好 的 词嵌入(Embedding)数据集。(不用自己训练啦~~~)
任务:
导入 预训练词向量,使用余弦相似性(cosine similarity)计算相似度
使用词嵌入来解决 “Man is to Woman as King is to __.” 之类的 词语类比问题
修改词嵌入 来减少它们的性别歧视
import numpy as np
from w2v_utils import *
导入词向量,这个任务中,使用 50维的GloVe向量 来表示单词,导入 load the word_to_vec_map.
words, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt') # Embedding vector已知
print(list(words)[:10])
print(word_to_vec_map['mauzac'])
['1945gmt', 'mauzac', 'kambojas', '4-b', 'wakan', 'lorikeet', 'paratroops', 'wittkower', 'messageries', 'oliver']
[ 0.049225 -0.36274 -0.31555 -0.2424 -0.58761 0.27733
0.059622 -0.37908 -0.59505 0.78046 0.3348 -0.90401
0.7552 -0.30247 0.21053 0.03027 0.22069 0.40635
0.11387 -0.79478 -0.57738 0.14817 0.054704 0.973
-0.22502 1.3677 0.14288 0.83708 -0.31258 0.25514
-1.2681 -0.41173 0.0058966 -0.64135 0.32456 -0.84562
-0.68853 -0.39517 -0.17035 -0.54659 0.014695 0.073697
0.1433 -0.38125 0.22585 -0.70205 0.9841 0.19452
-0.21459 0.65096 ]
导入的数据:
words: 词汇表中单词集.word_to_vec_map: dictionary 映射单词到它们的 GloVe vector 表示.
Embedding vectors vs one-hot vectors
one-hot向量不能很好捕捉单词之间的相似度水平(每一个one-hot向量与任何其他one-hot向量有相同的欧几里得距离(Euclidean distance))
Embedding vector,如Glove vector提供了许多关于 单个单词含义 的有用信息
下面介绍如何使用 GloVe向量 来度量两个单词之间的 相似性
1.1 余弦相似度(Cosine similarity)
为了测量两个单词之间的相似性, 我们需要一个方法来测量两个单词的两个embedding vectors的相似性程度。 给定两个向量 \(u\) 和 \(v\), cosine similarity 定义如下:
\]
\(u \cdot v\) 是两个向量的点积(内积)
\(||u||_2\) 向量 \(u\) 的范数(长度)
\(\theta\) 是 \(u\) 与 \(v\) 之间的夹角角度
余弦相似性 依赖于 \(u\) and \(v\) 的角度.
- 如果 \(u\) 和 \(v\) 很相似, 那么 \(cos(\theta)\) 越接近1.
- 如果 \(u\) 和 \(v\) 不相似, 那么 \(cos(\theta)\) 得到一个很小的值.
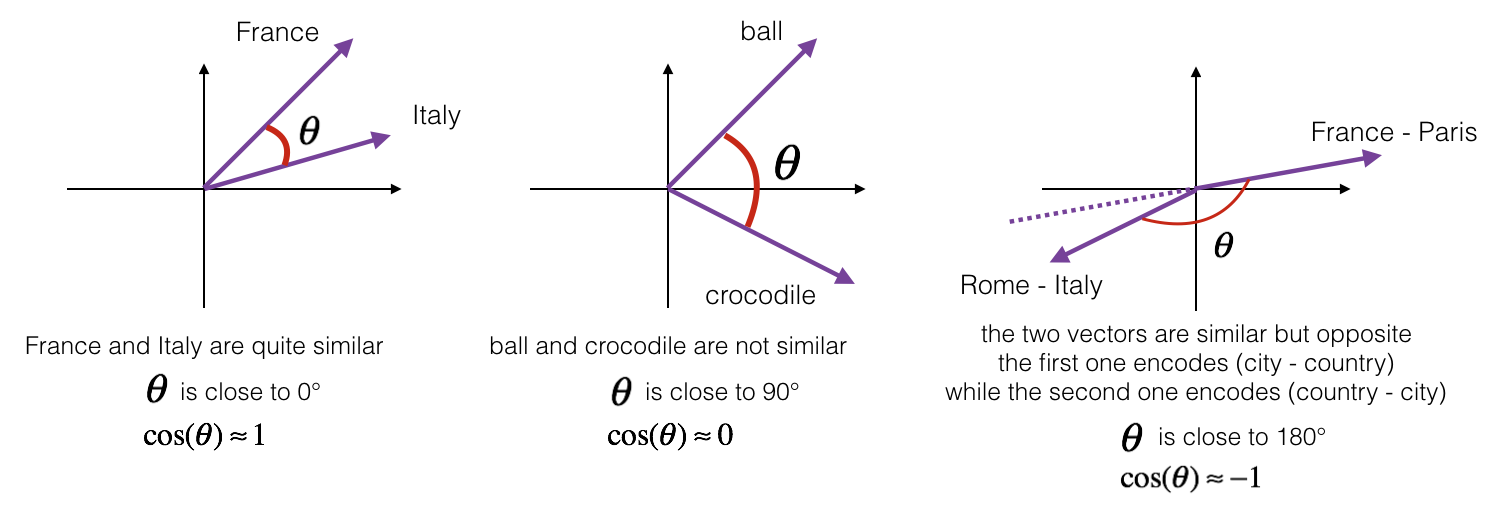
**Figure 1**: The cosine of the angle between two vectors is a measure their similarity
Exercise: 实现函数 cosine_similarity() 来计算两个词向量之间的 相似性.
Reminder: \(u\) 的范式定义为 \(||u||_2 = \sqrt{\sum_{i=1}^{n} u_i^2}\)
提示: 使用 np.dot, np.sum, or np.sqrt 很有用.
# GRADED FUNCTION: cosine_similarity
def cosine_similarity(u, v):
"""
Cosine similarity reflects the degree of similarity between u and v
Arguments:
u -- a word vector of shape (n,)
v -- a word vector of shape (n,)
Returns:
cosine_similarity -- the cosine similarity between u and v defined by the formula above.
"""
distance = 0.0
### START CODE HERE ###
# Compute the dot product between u and v (≈1 line)
dot = np.sum(u * v)
# Compute the L2 norm of u (≈1 line)
norm_u = np.sqrt(np.sum(np.square(u)))
# Compute the L2 norm of v (≈1 line)
norm_v = np.sqrt(np.sum(np.square(v)))
# Compute the cosine similarity defined by formula (1) (≈1 line)
cosine_similarity = dot / (norm_u * norm_v)
### END CODE HERE ###
return cosine_similarity
测试:
father = word_to_vec_map["father"]
mother = word_to_vec_map["mother"]
ball = word_to_vec_map["ball"]
crocodile = word_to_vec_map["crocodile"]
france = word_to_vec_map["france"]
italy = word_to_vec_map["italy"]
paris = word_to_vec_map["paris"]
rome = word_to_vec_map["rome"]
print("cosine_similarity(father, mother) = ", cosine_similarity(father, mother))
print("cosine_similarity(ball, crocodile) = ",cosine_similarity(ball, crocodile))
print("cosine_similarity(france - paris, rome - italy) = ",cosine_similarity(france - paris, rome - italy)) # (国家-首都, 首都-国家)-->接近-1
print("cosine_similarity(france - paris, italy - rome) = ",cosine_similarity(france - paris, italy - rome))
cosine_similarity(father, mother) = 0.890903844289
cosine_similarity(ball, crocodile) = 0.274392462614
cosine_similarity(france - paris, rome - italy) = -0.675147930817
cosine_similarity(france - paris, italy - rome) = 0.675147930817
随意的修改单词,查看他们相似性。
1.2 词类比工作(Word analogy task)
在词类比工作(word analogy task)中,我们完成句子:
"a is to b as c is to ____".举例:
'man is to woman as king is to queen' .我们尝试找到一个单词 d,使得相关的单词向量 \(e_a, e_b, e_c, e_d\) 以下列方式关联:
\(e_b - e_a \approx e_d - e_c\)我们将使用cosine similarity测量 \(e_b - e_a\) 和 \(e_d - e_c\) 的相似性.
Exercise:完成函数complete_analogy 实现 word analogies.
# GRADED FUNCTION: complete_analogy
def complete_analogy(word_a, word_b, word_c, word_to_vec_map):
"""
Performs the word analogy task as explained above: a is to b as c is to ____.
Arguments:
word_a -- a word, string
word_b -- a word, string
word_c -- a word, string
word_to_vec_map -- dictionary that maps words to their corresponding vectors.
Returns:
best_word -- the word such that v_b - v_a is close to v_best_word - v_c, as measured by cosine similarity
"""
# convert words to lower case
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
### START CODE HERE ###
# Get the word embeddings v_a, v_b and v_c (≈1-3 lines)
e_a, e_b, e_c = word_to_vec_map[word_a],word_to_vec_map[word_b],word_to_vec_map[word_c]
### END CODE HERE ###
words = word_to_vec_map.keys()
max_cosine_sim = -100 # Initialize max_cosine_sim to a large negative number
best_word = None # Initialize best_word with None, it will help keep track of the word to output
# loop over the whole word vector set
for w in words:
# to avoid best_word being one of the input words, pass on them.
if w in [word_a, word_b, word_c] :
continue
### START CODE HERE ###
# Compute cosine similarity between the vector (e_b - e_a) and the vector ((w's vector representation) - e_c) (≈1 line)
cosine_sim = cosine_similarity(e_b - e_a,word_to_vec_map[w] - e_c)
# If the cosine_sim is more than the max_cosine_sim seen so far,
# then: set the new max_cosine_sim to the current cosine_sim and the best_word to the current word (≈3 lines)
if cosine_sim > max_cosine_sim:
max_cosine_sim = cosine_sim
best_word = w
### END CODE HERE ###
return best_word
测试:
triads_to_try = [('italy', 'italian', 'spain'), ('india', 'delhi', 'japan'), ('man', 'woman', 'boy'), ('small', 'smaller', 'large')]
for triad in triads_to_try:
print ('{} -> {} :: {} -> {}'.format( *triad, complete_analogy(*triad,word_to_vec_map)))
italy -> italian :: spain -> spanish
india -> delhi :: japan -> tokyo
man -> woman :: boy -> girl
small -> smaller :: large -> larger
也存在一些单词,算法不能给出正确答案:
triad = ['small', 'smaller', 'big']
print ('{} -> {} :: {} -> {}'.format( *triad, complete_analogy(*triad, word_to_vec_map)))
small -> smaller :: big -> competitors
1.3 总结
Cosine similarity 求两个词向量的相似度不错
对于NLP应用,通常使用预训练好的词向量数据集
2. 除偏词向量(Debiasing word vectors)
在这一部分,我们将研究反映在词嵌入中的性别偏差,并试着去去除这一些偏差.
首先看一下 GloVe词嵌入如何关联性别的,你将计算一个向量 \(g = e_{woman}-e_{man}\),\(e_{woman}\) 代表 woman 的词向量,\(e_{man}\)代表man的词向量,得到的结果 \(g\) 粗略的包含性别这一概念,计算 \(g_1 = e_{mother}-e_{father}\),\(g_2 = e_{girl}-e_{boy}\) 的平均值可能会更准确点,现在使用 \(e_{woman}-e_{man}\) 足够了。
g = word_to_vec_map['woman'] - word_to_vec_map['man'] # 计算w与g的余弦相似度时,为正更接近女人,为负更接近男人
print(g)
[-0.087144 0.2182 -0.40986 -0.03922 -0.1032 0.94165
-0.06042 0.32988 0.46144 -0.35962 0.31102 -0.86824
0.96006 0.01073 0.24337 0.08193 -1.02722 -0.21122
0.695044 -0.00222 0.29106 0.5053 -0.099454 0.40445
0.30181 0.1355 -0.0606 -0.07131 -0.19245 -0.06115
-0.3204 0.07165 -0.13337 -0.25068714 -0.14293 -0.224957
-0.149 0.048882 0.12191 -0.27362 -0.165476 -0.20426
0.54376 -0.271425 -0.10245 -0.32108 0.2516 -0.33455
-0.04371 0.01258 ]
考虑不同单词与 \(g\) 的余弦相似度, 考虑一下正相似值 与 负余弦相似值的关系。
print ('List of names and their similarities with constructed vector:')
# girls and boys name
name_list = ['john', 'marie', 'sophie', 'ronaldo', 'priya', 'rahul', 'danielle', 'reza', 'katy', 'yasmin']
for w in name_list:
print (w, cosine_similarity(word_to_vec_map[w], g))
List of names and their similarities with constructed vector:
john -0.23163356146
marie 0.315597935396
sophie 0.318687898594
ronaldo -0.312447968503
priya 0.17632041839
rahul -0.169154710392
danielle 0.243932992163
reza -0.079304296722
katy 0.283106865957
yasmin 0.233138577679
可以看到,女性的名字与 \(g\) 的余弦相似度为正,男性的名字与 \(g\) 的余弦相似度为负。
尝试其他
print('Other words and their similarities:')
word_list = ['lipstick', 'guns', 'science', 'arts', 'literature', 'warrior','doctor', 'tree', 'receptionist',
'technology', 'fashion', 'teacher', 'engineer', 'pilot', 'computer', 'singer']
for w in word_list:
print (w, cosine_similarity(word_to_vec_map[w], g))
Other words and their similarities:
lipstick 0.276919162564
guns -0.18884855679
science -0.0608290654093
arts 0.00818931238588
literature 0.0647250443346
warrior -0.209201646411
doctor 0.118952894109
tree -0.0708939917548
receptionist 0.330779417506
technology -0.131937324476
fashion 0.0356389462577
teacher 0.179209234318
engineer -0.0803928049452
pilot 0.00107644989919
computer -0.103303588739
singer 0.185005181365
可以发现,比如“computer”就接近于“man”,“literature ”接近于“woman”,但是这些都是不对的一些观念,那么我们该如何减少这些偏差呢?
对于一些特殊的词汇而言,比如“男演员(actor)”与“女演员(actress)”或者“祖母(grandmother)”与“祖父(grandfather)”之间应该是具有性别差异的,而其他词汇比如“接待员(receptionist)”与“技术(technology )”是不应该有性别差异的,当我们处理这些词汇的时候应该区别对待。
2.1 中和非性别特定词汇的偏见(Neutralize bias for non-gender specific words)
下面的一张图表示了消除偏差之后的效果。如果我们使用的是50维的词嵌入,那么50维的空间可以分为两个部分: 偏置方向 \(g\),和 剩下的49维 \(g_{\perp}\)。 在线性代数中,将 49维的 \(g_{\perp}\) 与 \(g\) 垂直(perpendicular)或正交("orthogonal"),即 \(g_{\perp}\) 与 \(g\) 成90°角 。在中和步骤中,取一个向量,如 \(e_{receptionist}\)向量, 将 \(g\) 方向的组成 归零,得到 \(e_{receptionist}^{debiased}\) 向量。
即使 \(g_{\perp}\) 是 49维, 鉴于只能在2D屏幕上绘制图像的局限性,我们使用下面的一维坐标轴来说明它。
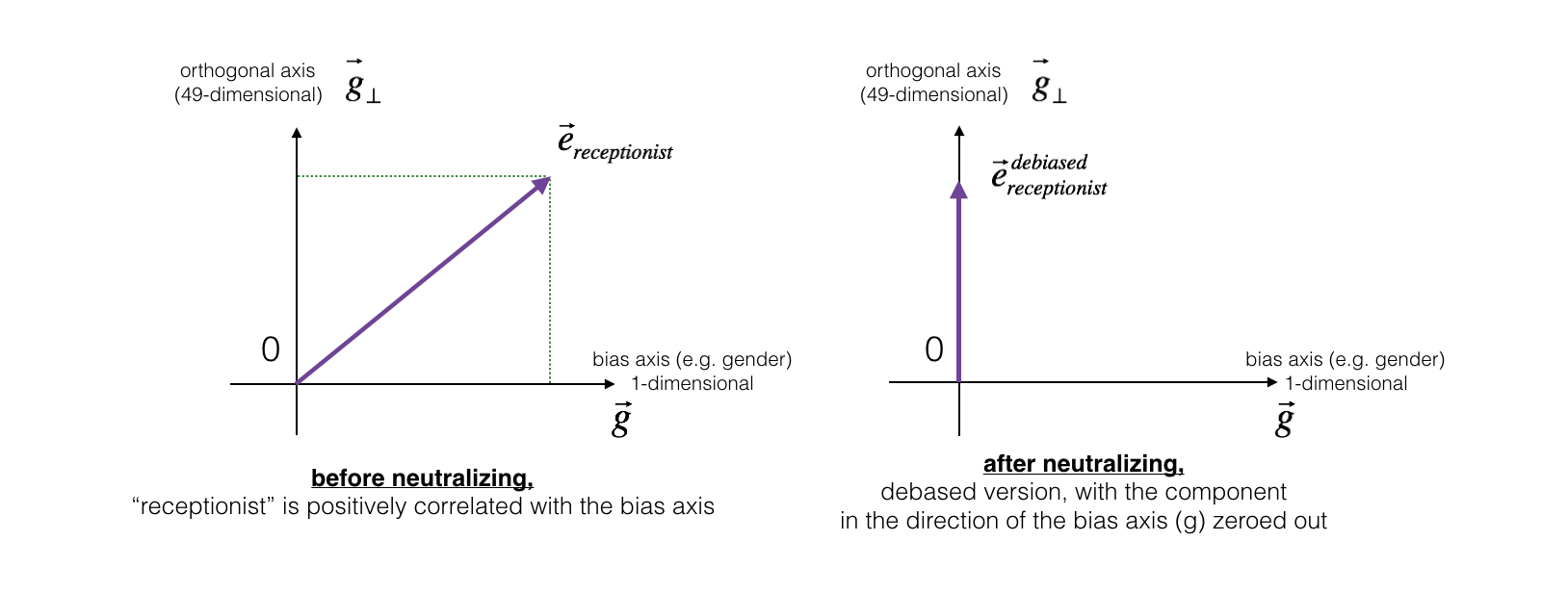
**Figure 2**: The word vector for "receptionist" represented before and after applying the neutralize operation.
Exercise: 实现 neutralize() 来消除词汇 的偏见,如 "receptionist" 和 "scientist"。 给定一个词嵌入输入\(e\),可以使用下面的公式计算 \(e^{debiased}\):
\]
\]
\(e^{bias\_component}\) 是 \(e\) 在 \(g\) 方向的投影。
def neutralize(word, g, word_to_vec_map):
"""
Removes the bias of "word" by projecting it on the space orthogonal to the bias axis.
This function ensures that gender neutral words are zero in the gender subspace.
Arguments:
word -- string indicating the word to debias
g -- numpy-array of shape (50,), corresponding to the bias axis (such as gender)
word_to_vec_map -- dictionary mapping words to their corresponding vectors.
Returns:
e_debiased -- neutralized word vector representation of the input "word"
"""
### START CODE HERE ###
# Select word vector representation of "word". Use word_to_vec_map. (≈ 1 line)
e = word_to_vec_map[word]
# Compute e_biascomponent using the formula give above. (≈ 1 line)
e_biascomponent = np.divide(np.sum(e * g), np.square(np.linalg.norm(g))) * g
# Neutralize e by substracting e_biascomponent from it
# e_debiased should be equal to its orthogonal projection. (≈ 1 line)
e_debiased = e - e_biascomponent
### END CODE HERE ###
return e_debiased
测试:
e = "receptionist"
print("cosine similarity between " + e + " and g, before neutralizing: ", cosine_similarity(word_to_vec_map["receptionist"], g))
e_debiased = neutralize("receptionist", g, word_to_vec_map)
print("cosine similarity between " + e + " and g, after neutralizing: ", cosine_similarity(e_debiased, g))
cosine similarity between receptionist and g, before neutralizing: 0.330779417506
cosine similarity between receptionist and g, after neutralizing: -5.60374039375e-17
2.2 性别词的均衡算法(Equalization algorithm for gender-specific words)
接下来我们来看看在关于有特定性别词组中,如何将它们进行均衡,比如“男演员”与“女演员”中,与“保姆”一词更接近的是“女演员”,我们可以消去“保姆”的性别偏差,但是这并不能保证“保姆”一词与“男演员”与“女演员”之间的距离相等,我们要学的均衡算法将解决这个问题。
均衡(equalization)关键思想:确保 一对特定的单词 与 49维 \(g_\perp\) 距离相等。均衡步骤还确保 两个被均衡的step 现在与 \(e_{receptionist}^{debiased}\) 或 任何已被中和的其他工作的距离相同。下面展示equalization如何工作:
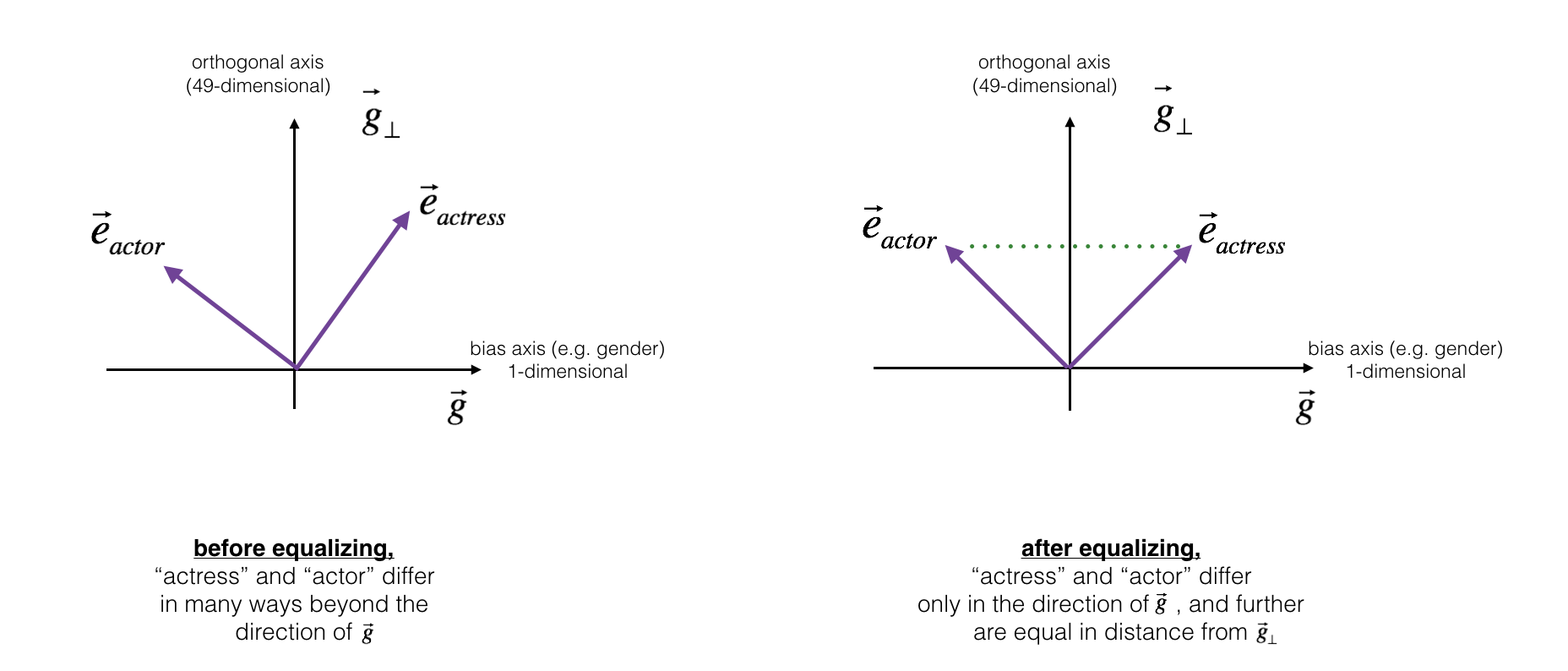
线性代数的推导过程很复杂(See Bolukbasi et al., 2016 for details.) 关键的公式:
\]
\tag{5}\]
\]
\tag{7}\]
\tag{8}\]
\]
\]
\]
\]
Exercise: 使用这些上述公式 得到这对单词的最终均衡版本.
def equalize(pair, bias_axis, word_to_vec_map):
"""
Debias gender specific words by following the equalize method described in the figure above.
Arguments:
pair -- pair of strings of gender specific words to debias, e.g. ("actress", "actor")
bias_axis -- numpy-array of shape (50,), vector corresponding to the bias axis, e.g. gender
word_to_vec_map -- dictionary mapping words to their corresponding vectors
Returns
e_1 -- word vector corresponding to the first word
e_2 -- word vector corresponding to the second word
"""
### START CODE HERE ###
# Step 1: Select word vector representation of "word". Use word_to_vec_map. (≈ 2 lines)
w1, w2 = pair
e_w1, e_w2 = word_to_vec_map[w1],word_to_vec_map[w2]
# Step 2: Compute the mean of e_w1 and e_w2 (≈ 1 line)
mu = (e_w1 + e_w2) / 2
# Step 3: Compute the projections of mu over the bias axis and the orthogonal axis (≈ 2 lines)
mu_B = np.divide(np.dot(mu, bias_axis) * bias_axis, np.sum(bias_axis**2))
mu_orth = mu - mu_B
# Step 4: Use equations (7) and (8) to compute e_w1B and e_w2B (≈2 lines)
e_w1B = (np.dot(e_w1,bias_axis) * bias_axis) / (np.sum(bias_axis**2))
e_w2B = (np.dot(e_w2,bias_axis) * bias_axis) / (np.sum(bias_axis**2))
# Step 5: Adjust the Bias part of e_w1B and e_w2B using the formulas (9) and (10) given above (≈2 lines)
corrected_e_w1B = (np.sqrt(np.abs(1 - (np.sum(mu_orth**2))))) * np.divide(e_w1B - mu_B, np.abs((e_w1 - mu_orth) - mu_B))
corrected_e_w2B = (np.sqrt(np.abs(1 - (np.sum(mu_orth**2))))) * np.divide(e_w2B - mu_B, np.abs((e_w2 - mu_orth) - mu_B))
# Step 6: Debias by equalizing e1 and e2 to the sum of their corrected projections (≈2 lines)
e1 = corrected_e_w1B + mu_orth
e2 = corrected_e_w2B + mu_orth
### END CODE HERE ###
return e1, e2
测试:
print("cosine similarities before equalizing:")
print("cosine_similarity(word_to_vec_map[\"man\"], gender) = ", cosine_similarity(word_to_vec_map["man"], g))
print("cosine_similarity(word_to_vec_map[\"woman\"], gender) = ", cosine_similarity(word_to_vec_map["woman"], g))
print()
e1, e2 = equalize(("man", "woman"), g, word_to_vec_map)
print("cosine similarities after equalizing:")
print("cosine_similarity(e1, gender) = ", cosine_similarity(e1, g))
print("cosine_similarity(e2, gender) = ", cosine_similarity(e2, g))
cosine similarities before equalizing:
cosine_similarity(word_to_vec_map["man"], gender) = -0.117110957653
cosine_similarity(word_to_vec_map["woman"], gender) = 0.356666188463
cosine similarities after equalizing:
cosine_similarity(e1, gender) = -0.716572752584
cosine_similarity(e2, gender) = 0.739659647493
Debiasing algorithms 减少偏见很有用,但并不完美,不能消除所有的偏置痕迹
- 如:这种实现的一个缺点: \(g\) 的偏差方向 只使用 单词对 woman 和 man 来定义。如果通过计算 \(g_1 = e_{woman} - e_{man}\),\(g_2 = e_{mother} - e_{father}\),\(g_3 = e_{girl} - e_{boy}\),然后使用 \(g = avg(g_1, g_2, g_3)\) 来计算他它们平均,你将更好的估计50维词嵌入空间中的 "gender" 维度。
Sequence Model-week2编程题1-词向量的操作【余弦相似度 词类比 除偏词向量】的更多相关文章
- 改善深层神经网络-week2编程题(Optimization Methods)
1. Optimization Methods Gradient descent goes "downhill" on a cost function \(J\). Think o ...
- 【剑指Offer面试编程题】题目1390:矩形覆盖--九度OJ
题目描述: 我们可以用2*1的小矩形横着或者竖着去覆盖更大的矩形.请问用n个2*1的小矩形无重叠地覆盖一个2*n的大矩形,总共有多少种方法? 输入: 输入可能包含多个测试样例,对于每个测试案例, 输入 ...
- 【剑指Offer面试编程题】题目1355:扑克牌顺子--九度OJ
题目描述: LL今天心情特别好,因为他去买了一副扑克牌,发现里面居然有2个大王,2个小王(一副牌原本是54张^_^)...他随机从中抽出了5张牌,想测测自己的手气,看看能不能抽到顺子,如果抽到的话,他 ...
- 【剑指Offer面试编程题】题目1214:丑数--九度OJ
把只包含因子2.3和5的数称作丑数(Ugly Number).例如6.8都是丑数,但14不是,因为它包含因子7. 习惯上我们把1当做是第一个丑数.求按从小到大的顺序的第N个丑数. 输入: 输入包括一个 ...
- 【剑指Offer面试编程题】题目1518:反转链表--九度OJ
题目描述: 输入一个链表,反转链表后,输出链表的所有元素. (hint : 请务必使用链表) 输入: 输入可能包含多个测试样例,输入以EOF结束. 对于每个测试案例,输入的第一行为一个整数n(0< ...
- 【剑指Offer面试编程题】题目1388:跳台阶--九度OJ
题目描述: 一只青蛙一次可以跳上1级台阶,也可以跳上2级.求该青蛙跳上一个n级的台阶总共有多少种跳法. 输入: 输入可能包含多个测试样例,对于每个测试案例, 输入包括一个整数n(1<=n< ...
- 【剑指Offer面试编程题】题目1385:重建二叉树--九度OJ
题目描述: 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树.假设输入的前序遍历和中序遍历的结果中都不含重复的数字.例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7 ...
- 【剑指Offer面试编程题】题目1510:替换空格--九度OJ
题目描述: 请实现一个函数,将一个字符串中的空格替换成"%20".例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy. 输入: 每个 ...
- POJ C++程序设计 编程题#4 字符串操作
编程题#4: 字符串操作 来源: POJ (Coursera声明:在POJ上完成的习题将不会计入Coursera的最后成绩.) 注意: 总时间限制: 1000ms 内存限制: 65536kB 描述 给 ...
随机推荐
- 性能测试工具JMeter 基础(六)—— 测试元件: 线程组
线程组的定义: 线程组是测试计划执行的入口,所有的逻辑控制器和取样器都必须在线程组下,其他的元件根据位置的不同作用域是不同的. 线程组是每个线程都是独立运行测试脚本,一个线程组就等于一个用户,通过多个 ...
- python 修改图像大小和分辨率
1 概念: 分辨率,指的是图像或者显示屏在长和宽上各拥有的像素个数.比如一张照片分辨率为1920x1080,意思是这张照片是由横向1920个像素点和纵向1080个像素点构成,一共包含了1920x108 ...
- Python中 sys.argv[]
sys.argv[]是一个从程序外部获取参数的桥梁,从外部取得的参数可以是多个,所以获得的是一个列表(list),用[]提取其中的元素.其第一个元素是程序本身,随后才依次是外部给予的参数. 实例 im ...
- VS Code 搭建stm32开发环境
MCU免费开发环境 一般芯片厂家会提供各种开发IDE方案,通常其中就包括其自家的集成IDE,如: 意法半导体 STM32CubeIDE NXP Codewarrior TI CCS 另外也可以用ecl ...
- C# Collection
数组与集合不同的适用范围: 数组:数组最适用于创建和使用固定数量的强类型化对象. 集合:集合提供更灵活的方式来使用对象组. 与数组不同,你使用的对象组随着应用程序更改的需要动态地放大和缩小. 对于某些 ...
- shell中的$0 $n $# $* $@ $? $$
$0当前脚本的文件名 $n传递给脚本或函数的参数.n 是一个数字,表示第几个参数.例如,第一个参数是$1,第二个参数是$2. $#传递给脚本或函数的参数个数. $*传递给脚本或函数的所有参数. $@传 ...
- Ubuntu中类似QQ截图的截图工具并实现鼠标右键菜单截图
@ 目录 简介: 安装: 设置快捷键: 实现鼠标右键菜单截图: 简介: 在Windows中用惯了强大易用的QQ截图,会不习惯Ubuntu中的截图工具. 软件名为火焰截图,功能类似QQ截图,可以设置快捷 ...
- c++ if语句讲解&例题
一.if语句 1.基本语法: if(条件 布尔型){ 当条件符合执行的语句 } 2.例子: #include <iostream> using namespace std; int mai ...
- CentOS8部署tftp
tftp:简单文本传输协议,而ftp:文本传输协议.可以把tftp看成是ftp的精简版.tftp用于免登录传输小文件,tftp服务端监听在udp协议的69端口tftp简单的工作原理: tftp服务端与 ...
- PHP中操作任意精度大小的GMP扩展学习
对于各类开发语言来说,整数都有一个最大的位数,如果超过位数就无法显示或者操作了.其实,这也是一种精度越界之后产生的精度丢失问题.在我们的 PHP 代码中,最大的整数非常大,我们可以通过 PHP_INT ...