示例讲解PostgreSQL表分区的三种方式
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶!
1 简介
表分区是解决一些因单表过大引用的性能问题的方式,比如某张表过大就会造成查询变慢,可能分区是一种解决方案。一般建议当单表大小超过内存就可以考虑表分区了。PostgreSQL的表分区有三种方式:
- Range:范围分区;
- List:列表分区;
- Hash:哈希分区。
本文通过示例讲解如何进行这三种方式的分区。
2 例讲三种方式
为方便,我们通过Docker的方式启动一个PostgreSQL,可参考:《Docker启动PostgreSQL并推荐几款连接工具》。我们要选择较高的版本,否则不支持Hash分区,命令如下:
docker run -itd \
--name pkslow-postgres \
-e POSTGRES_DB=pkslow \
-e POSTGRES_USER=pkslow \
-e POSTGRES_PASSWORD=pkslow \
-p 5432:5432 \
postgres:13
2.1 Range范围分区
先创建一张表带有年龄,然后我们根据年龄分段来进行分区,创建表语句如下:
CREATE TABLE pkslow_person_r (
age int not null,
city varchar not null
) PARTITION BY RANGE (age);
这个语句已经指定了按age字段来分区了,接着创建分区表:
create table pkslow_person_r1 partition of pkslow_person_r for values from (MINVALUE) to (10);
create table pkslow_person_r2 partition of pkslow_person_r for values from (11) to (20);
create table pkslow_person_r3 partition of pkslow_person_r for values from (21) to (30);
create table pkslow_person_r4 partition of pkslow_person_r for values from (31) to (MAXVALUE);
这里创建了四张分区表,分别对应年龄是0到10岁、11到20岁、21到30岁、30岁以上。
接着我们插入一些数据:
insert into pkslow_person_r(age, city) VALUES (1, 'GZ');
insert into pkslow_person_r(age, city) VALUES (2, 'SZ');
insert into pkslow_person_r(age, city) VALUES (21, 'SZ');
insert into pkslow_person_r(age, city) VALUES (13, 'BJ');
insert into pkslow_person_r(age, city) VALUES (43, 'SH');
insert into pkslow_person_r(age, city) VALUES (28, 'HK');
可以看到这里的表名还是pkslow_person_r,而不是具体的分区表,说明对于客户端是无感知的。
我们查询也一样的:
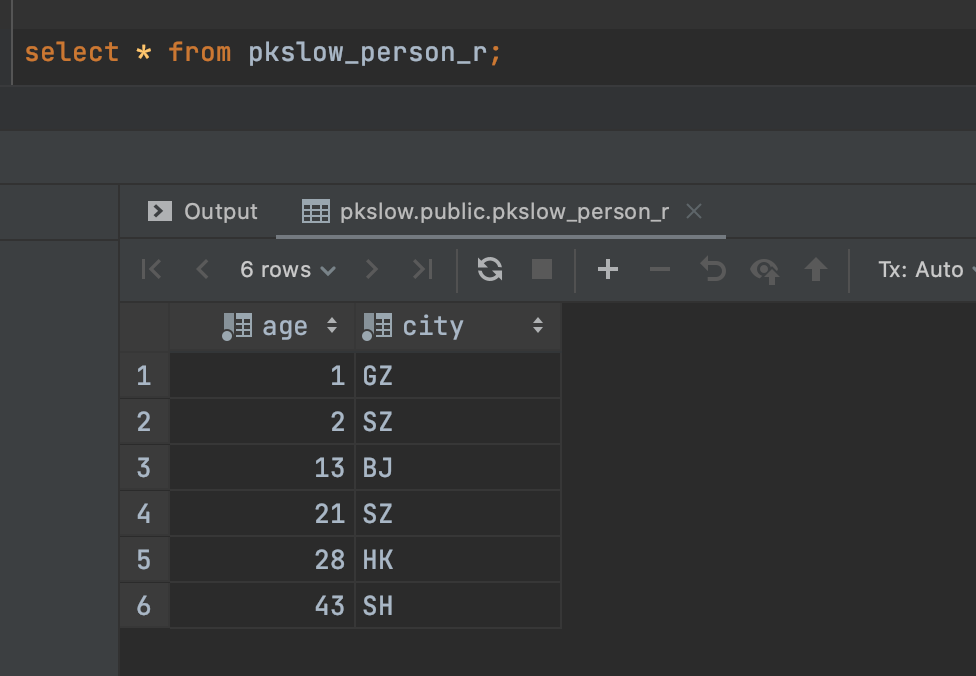
但实际上是有分区表存在的:

而且分区表与主表的字段是一致的。
查询分区表,就只能查到那个特定分区的数据了:

2.2 List列表分区
类似的,列表分区是按特定的值来分区,比较某个城市的数据放在一个分区里。这里不再给出每一步的讲解,代码如下:
-- 创建主表
create table pkslow_person_l (
age int not null,
city varchar not null
) partition by list (city);
-- 创建分区表
CREATE TABLE pkslow_person_l1 PARTITION OF pkslow_person_l FOR VALUES IN ('GZ');
CREATE TABLE pkslow_person_l2 PARTITION OF pkslow_person_l FOR VALUES IN ('BJ');
CREATE TABLE pkslow_person_l3 PARTITION OF pkslow_person_l DEFAULT;
-- 插入测试数据
insert into pkslow_person_l(age, city) VALUES (1, 'GZ');
insert into pkslow_person_l(age, city) VALUES (2, 'SZ');
insert into pkslow_person_l(age, city) VALUES (21, 'SZ');
insert into pkslow_person_l(age, city) VALUES (13, 'BJ');
insert into pkslow_person_l(age, city) VALUES (43, 'SH');
insert into pkslow_person_l(age, city) VALUES (28, 'HK');
insert into pkslow_person_l(age, city) VALUES (28, 'GZ');
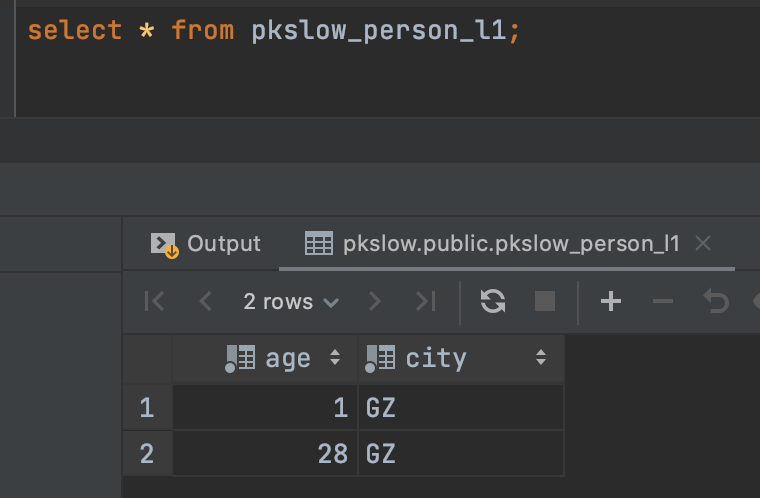
当我们查询第一个分区的时候,只有广州的数据:
2.3 Hash哈希分区
哈希分区是指按字段取哈希值后再分区。具体的语句如下:
-- 创建主表
create table pkslow_person_h (
age int not null,
city varchar not null
) partition by hash (city);
-- 创建分区表
create table pkslow_person_h1 partition of pkslow_person_h for values with (modulus 4, remainder 0);
create table pkslow_person_h2 partition of pkslow_person_h for values with (modulus 4, remainder 1);
create table pkslow_person_h3 partition of pkslow_person_h for values with (modulus 4, remainder 2);
create table pkslow_person_h4 partition of pkslow_person_h for values with (modulus 4, remainder 3);
-- 插入测试数据
insert into pkslow_person_h(age, city) VALUES (1, 'GZ');
insert into pkslow_person_h(age, city) VALUES (2, 'SZ');
insert into pkslow_person_h(age, city) VALUES (21, 'SZ');
insert into pkslow_person_h(age, city) VALUES (13, 'BJ');
insert into pkslow_person_h(age, city) VALUES (43, 'SH');
insert into pkslow_person_h(age, city) VALUES (28, 'HK');
可以看到创建分区表的时候,我们用了取模的方式,所以如果要创建N个分区表,就要取N取模。
随便查询一张分区表如下:
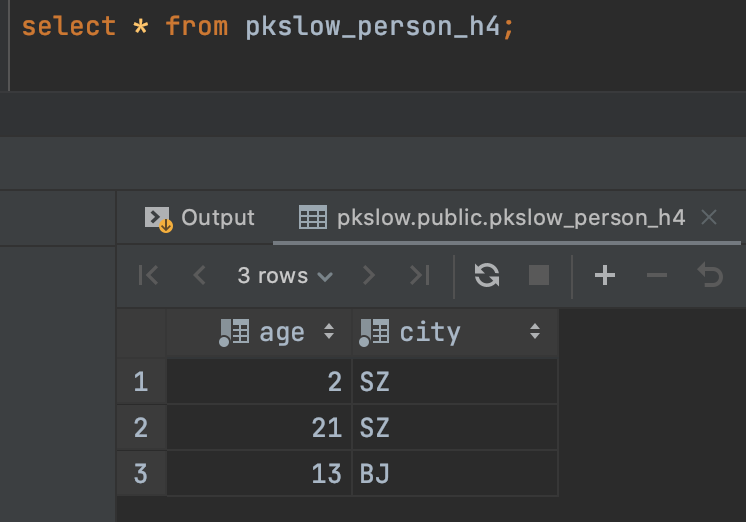
可以看到同是SZ的哈希值是一样的,肯定会分在同一个分区,而BJ的哈希值取模后也属于同一个分区。
3 总结
本文讲解了PostgreSQL分区的三种方式。
代码请查看:https://github.com/LarryDpk/pkslow-samples
欢迎关注微信公众号<南瓜慢说>,将持续为你更新...

多读书,多分享;多写作,多整理。
示例讲解PostgreSQL表分区的三种方式的更多相关文章
- 多表连接的三种方式 HASH MERGE NESTED
多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP------------------------------------------------------20 ...
- 多表连接的三种方式详解 hash join、merge join、 nested loop
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式.多表之间的连接有三种方式:Nested Loops,Hash Join 和 Sort Merge Join.具体适用哪 ...
- Python - Django - ORM 多对多表结构的三种方式
多对多的三种方式: ORM 自动创建第三张表 自己创建第三张表, 利用外键分别关联作者和书,关联查询比较麻烦,因为没办法使用 ORM 提供的便利方法 自己创建第三张表,使用 ORM 的 ManyToM ...
- python 获取表单的三种方式
条件:urls.py文件中配置好url的访问路径.models.py文件中有Business表. 在views.py文件中实现的三种方式: from app01 improt models def b ...
- 多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP
在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的连接方式. 之前打算在sqlplus中用执行计划的,但是格式看起来有点乱,就用Toad 做了3个截图. 从3张图里我们看到了几点 ...
- form表单提交三种方式,demo实例详解
第一种:使用type=submit 可以直接提交 <html> <head> <title>submit直接提交</title> </head& ...
- Django创建多对多表关系的三种方式
方式一:全自动(不推荐) 优点:django orm会自动创建第三张表 缺点:只会创建两个表的关系字段,不会再额外添加字段,可扩展性差 class Book(models.Model): # ... ...
- ORACLE 两表关联更新三种方式
不多说了,我们来做实验吧. 创建如下表数据 select * from t1 ; select * from t2; 现需求:参照T2表,修改T1表,修改条件为两表的fname列内容一致. 方式1,u ...
- PHP连接数据库、创建数据库、创建表的三种方式
这篇博客主要介绍了三种方式来连接MySQL数据库以及创建数据库.创建表.(代码是我在原来的基础上改的) MySQLi - 面向对象 MySQLi - 面向过程 PDO MySQLi 面向对象 < ...
随机推荐
- training11.14
7-10 关于堆的判断 (25分) 题目:将一系列给定数字顺序插入一个初始为空的小顶堆H[].随后判断一系列相关命题是否为真.命题分下列几种: x is the root:x是根结点: x and ...
- What are CBR, VBV and CPB?
转自:https://codesequoia.wordpress.com/2010/04/19/what-are-cbr-vbv-and-cpb/ It's common mistake to to ...
- Beta——事后分析
事后总结 NameNotFound 团队 项目 内容 北航-2020-软件工程(春季学期) 班级博客 要求 Beta事后分析 课程目标 通过团队合作完成一个软件项目的开发 会议截图 一.设想和目标 软 ...
- .Net Core with 微服务 - 架构图
上一次我们简单介绍了什么是微服务(.NET Core with 微服务 - 什么是微服务 ).介绍了微服务的来龙去脉,一些基础性的概念.有大佬在评论区指出说这根本不是微服务.由于本人的能力有限,大概也 ...
- at在指定的时间执行命令+atq列出用户待处理作业(jobs)
按下crtl+d取消定时任务 # at now+1hourat> echo"a">aat> <EOF>at> <EOT>job 4 ...
- 027. Python面向对象的__init__方法
__init__魔术方法(构造方法) 触发时机:实例化对象,初始化的时候触发 功能:为对象添加成员 参数:参数不固定,至少一个self参数 返回值:无 基本用法,至少含有一个参数 class MyCl ...
- Linux ll查看文件属性详解-软硬链接详解
Linux文件属性及类型 [root@localhost ~]# ll anaconda-ks.cfg 文件类型 权限 硬连接数 文件的大小 文件的创建,修改时间 - rw-------. 1 roo ...
- MyBatis 环境搭建(四)
MyBatis 引言 在回顾JDBC时,我们已经创建有 Java 工程,而且也已经导入 mysql 依赖包,这里就直接在原有工程上搭建MyBatis环境,以及使用MyBatis来实现之前用 JDBC ...
- sprintf和snprintf函数
printf()/sprintf()/snprintf()区别 先贴上其函数原型 printf( const char *format, ...) 格式化输出字符串,默认输出到终端-----s ...
- IT行业新闻事件
台积电: http://www.eefocus.com/component/394512 新闻合集: https://mail.qq.com/cgi-bin/frame_html?sid=q3Mhqr ...