快速搭建ELK7.5版本的日志分析系统--搭建篇
title: 快速搭建ELK7.5版本的日志分析系统--搭建篇
一、ELK安装部署
官网地址:https://www.elastic.co/cn/
官网权威指南:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
安装指南:https://www.elastic.co/guide/en/elasticsearch/reference/7.5/rpm.html
ELK是Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部
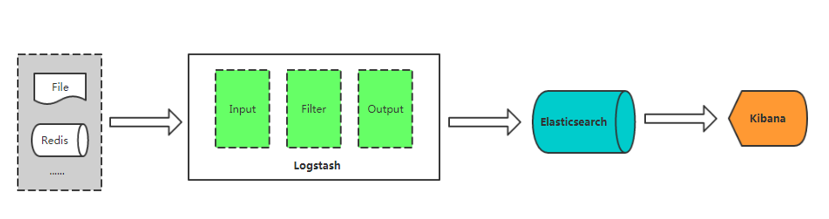
- Logstash :是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
- Elasticsearch:是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
- Kibana:一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
- Beats :轻量型采集器的平台,从边缘机器向 Logstash 和 Elasticsearch 发送数据。
Filebeat:轻量型日志采集器。
https://www.elastic.co/cn/
https://www.elastic.co/subscriptions
Input:输入,输出数据可以是Stdin、File、TCP、Redis、Syslog等。
Filter:过滤,将日志格式化。有丰富的过滤插件:Grok正则捕获、Date时间处理、Json编解码、Mutate数据修改等。
Output:输出,输出目标可以是Stdout、File、TCP、Redis、ES等。
基本概念
Node:运行单个ES实例的服务器
Cluster:一个或多个节点构成集群
Index:索引是多个文档的集合
Document:Index里每条记录称为Document,若干文档构建一个Index
Type:一个Index可以定义一种或多种类型,将Document逻辑分组
Field:ES存储的最小单元
Shards:ES将Index分为若干份,每一份就是一个分片
Replicas:Index的一份或多份副本
ES 关系型数据库(比如Mysql)
| ES | 关系型数据库(比如Mysql) |
|---|---|
| Index | Database |
| Type | Table |
| Document | Row |
| Field | Column |
准备环境
本次使用2台服务器来进行模拟集群,所以请准备2台服务器
Centos7.6 两台
IP:192.168.73.133 安装: elasticsearch、logstash、Kibana、java
192.168.73.135 安装: elasticsearch、logstash
安装JDK
yum安装
[root@elk-master ~]# yum install -y java
[root@elk-master ~]# java -version
openjdk version "1.8.0_232"
OpenJDK Runtime Environment (build 1.8.0_232-b09)
OpenJDK 64-Bit Server VM (build 25.232-b09, mixed mode)
源码安装JDK
下载安装http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
配置Java环境
# tar zxf jdk-8u91-linux-x64.tar.gz -C /usr/local/
# ln –s /usr/local/jdk1.8.0_91 /usr/local/jdk
# vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
# source /etc/profile
看到如下信息,java环境配置成功
# java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
配置安装ElasticSearch
yum安装
安装elasticsearch的yum源的密钥(这个需要在所有服务器上都配置)
[root@elk-master ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
配置elasticsearch的yum源
在elasticsearch.repo文件中添加如下内容
[root@elk-master ~]# vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
安装elasticsearch
[root@elk-master ~]# yum install -y elasticsearch
创建elasticsearch data的存放目录,并修改该目录的属主属组
# mkdir -p /data/es-data (自定义用于存放data数据的目录)
# chown -R elasticsearch:elasticsearch /data/es-data
修改elasticsearch的日志属主属组
# chown -R elasticsearch:elasticsearch /var/log/elasticsearch/
修改elasticsearch的配置文件
[root@elk-master ~]# vim /etc/elasticsearch/elasticsearch.yml
找到配置文件中的cluster.name,打开该配置并设置集群名称,是否作为主节点
cluster.name: elk-cluster
node.master: true
node.data: true
找到配置文件中的node.name,打开该配置并设置节点名称
node.name: elk-1
修改data存放的路径
path.data: /data/es-data
修改logs日志的路径
path.logs: /var/log/elasticsearch/
监听的网络地址
network.host: 192.168.73.133
设置集群中的Master节点的初始列表,可以通过这些节点来自动发现其他新加入集群的节点
discovery.zen.ping.unicast.hosts: ["192.168.73.133", "192.168.73.135"]
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 1
开启监听的端口
http.port: 9200
增加新的参数,这样head插件可以访问es (7.x版本,如果没有可以自己手动加)
http.cors.enabled: true
http.cors.allow-origin: "*"
检查配置
[root@elk-master ~]# grep -v ^# /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluster
node.name: elk-1
node.master: true
node.data: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: false
network.host: 192.168.73.133
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.73.133", "192.168.73.135"]
discovery.zen.minimum_master_nodes: 1
http.cors.enabled: true
http.cors.allow-origin: "*"
集群主要关注两个参数
discovery.zen.ping.unicast.hosts # 单播,集群节点IP列表。提供了自动组织集群,自动扫描端口9300-9305连接其他节点。无需额外配置。
discovery.zen.minimum_master_nodes # 最少主节点数
为防止数据丢失,这个参数很重要,如果没有设置,可能由于网络原因脑裂导致分为两个独立的集群。为避免脑裂,应设置符合节点的法定人数:(nodes / 2 ) + 1
换句话说,如果集群节点有三个,则最小主节点设置为(3/2) + 1 或2
启动服务并设置开机启动
[root@elk-master ~]# systemctl start elasticsearch && systemctl enable elasticsearch
通过浏览器请求下9200的端口,看下是否成功
先检查9200端口是否起来
[root@elk-master ~]# netstat -antp |grep 9200
tcp6 0 0 192.168.73.133:9200 :::* LISTEN 61375/java
浏览器访问测试是否正常(以下为正常)
[root@elk-master ~]# curl http://192.168.73.133:9200/
{
"name" : "elk-1",
"cluster_name" : "elk-cluster",
"cluster_uuid" : "AtEF6eE2RXGw2_vv-WVcVw",
"version" : {
"number" : "7.5.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "e9ccaed468e2fac2275a3761849cbee64b39519f",
"build_date" : "2019-11-26T01:06:52.518245Z",
"build_snapshot" : false,
"lucene_version" : "8.3.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
注意事项
需要修改几个参数,不然启动会报错
vim /etc/security/limits.conf
在末尾追加以下内容(elk为启动用户,当然也可以指定为*)
elk soft nofile 65536
elk hard nofile 65536
elk soft nproc 2048
elk hard nproc 2048
elk soft memlock unlimited
elk hard memlock unlimited
继续再修改一个参数
vim /etc/security/limits.d/90-nproc.conf
将里面的1024改为2048(ES最少要求为2048)
* soft nproc 2048
另外还需注意一个问题(在日志发现如下内容,这样也会导致启动失败,这一问题困扰了很久)
[2017-06-14T19:19:01,641][INFO ][o.e.b.BootstrapChecks ] [elk-1] bound or publishing to a non-loopback or non-link-local address, enforcing bootstrap checks
[2017-06-14T19:19:01,658][ERROR][o.e.b.Bootstrap ] [elk-1] node validation exception
[1] bootstrap checks failed
[1]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
解决:修改配置文件,在配置文件添加一项参数(目前还没明白此参数的作用)
vim /etc/elasticsearch/elasticsearch.yml
bootstrap.system_call_filter: false
node节点安装
本次环境我们使用2台服务器,这2台服务器的服务搭建可以跟上面的步骤相同即可,配置文件按照以下修改
[root@k8s-node03 elasticsearch]# grep -v ^# /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluster
node.name: elk-2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.73.135
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.73.133", "192.168.73.135"]
discovery.zen.minimum_master_nodes: 1
http.cors.enabled: true
http.cors.allow-origin: "*"
启动服务并设置开机启动
[root@k8s-node03 elasticsearch]# systemctl start elasticsearch && systemctl enable elasticsearch
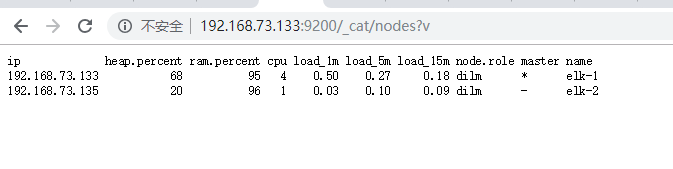
使用该地址可以查看node节点是否加入节点 http://192.168.73.133:9200/_cat/nodes?v
也可以使用REST接口查看集群健康状态:
[root@elk-master ~]# curl -i -XGET http://192.168.73.133:9200/_cluster/health?pretty
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 465
{
"cluster_name" : "elk-cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 5,
"active_shards" : 10,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
查看集群节点:
[root@elk-master ~]# curl -i -XGET http://192.168.73.133:9200/_cat/nodes?pretty
HTTP/1.1 200 OK
content-type: text/plain; charset=UTF-8
content-length: 102
192.168.73.135 19 96 1 0.07 0.15 0.14 dilm - elk-2
192.168.73.133 16 96 7 0.54 0.45 0.35 dilm * elk-1
green:所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow:所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。
red:至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
green/yellow/red 状态是一个概览你的集群并了解眼下正在发生什么的好办法
安装elasticsearch-head插件
安装docker镜像或者通过github下载elasticsearch-head项目都是可以的,1或者2两种方式选择一种安装使用即可
Github下载地址:https://github.com/mobz/elasticsearch-head
1. 使用docker的集成好的elasticsearch-head
# docker run -p 9100:9100 mobz/elasticsearch-head:5
docker容器下载成功并启动以后,运行浏览器打开http://localhost:9100/
2. 使用git安装elasticsearch-head
# yum install -y npm
# git clone git://github.com/mobz/elasticsearch-head.git
# cd elasticsearch-head
# npm install
# npm run start &
检查端口是否起来
netstat -antp |grep 9100
浏览器访问测试是否正常
http://IP:9100/
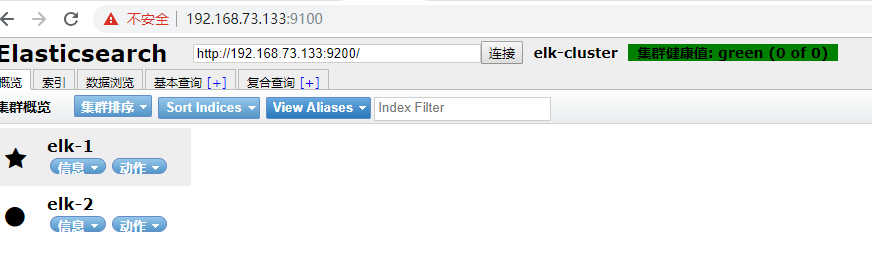
集群健康值介绍:
黄色代表没有主分片数据丢失,但是现在不是健康的状态(警告)应该有10个分片,现在只有5个。
红色代表有数据丢失
绿色代表正常
提示:es支持一个类似于快照的功能,方便我们用于数据备份
Head插件小缺点: 当我们索引特别多的时候,打开head至少需要五分钟。因为它要把所有的索引都扫描一遍进行展示,这时候打开使用的带宽也会特别大(不会出现超时,一直等待就可以)
LogStash的安装使用
安装Logstash环境:
官方安装手册:
https://www.elastic.co/guide/en/logstash/current/installing-logstash.html
下载yum源的密钥认证:
[root@elk-master ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
利用yum安装logstash
[root@elk-master ~]# yum install -y logstash
创建一个软连接,每次执行命令的时候不用在写安装路劲(默认安装在/usr/share下)
[root@elk-master ~]# ln -s /usr/share/logstash/bin/logstash /bin/
执行logstash的命令
[root@elk-master ~]# logstash -e 'input { stdin { } } output { stdout {} }'
hello world
test
然后等待stdout返回的结果
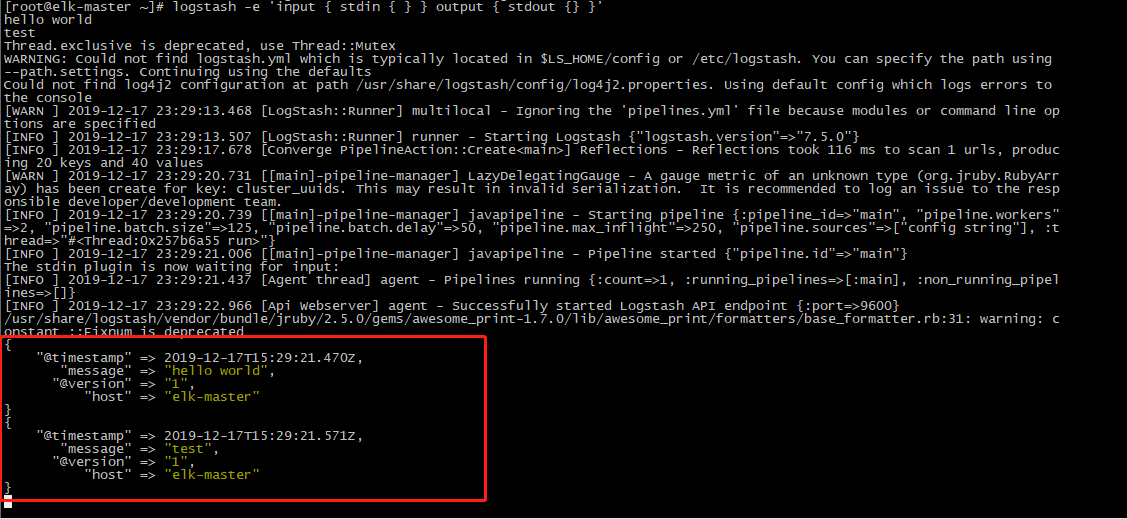
注:
-e 执行操作
input 标准输入
{ input } 插件
output 标准输出
{ stdout } 插件
如果标准输出到elasticsearch中保存下来,应该怎么玩,看下面
[root@elk-master ~]# logstash -e 'input { stdin { } } output { elasticsearch { hosts => ["192.168.73.133:9200"] } stdout { codec => rubydebug }}'
I am ELK
who are you
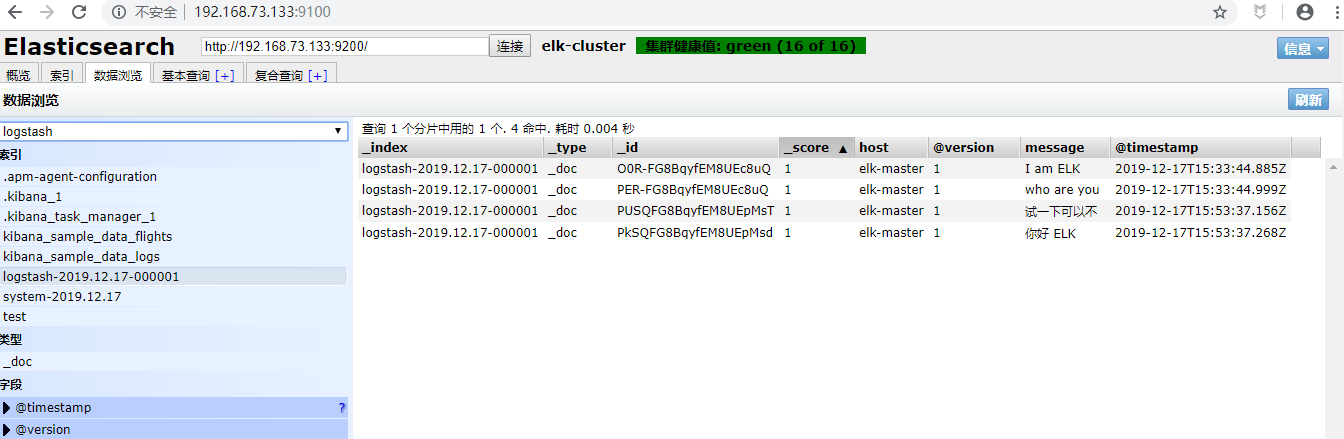
logstash使用配置文件
官方指南:
https://www.elastic.co/guide/en/logstash/current/configuration.html
创建配置文件elk.conf
input { stdin { } }
output {
elasticsearch { hosts => ["192.168.73.133:9200"] }
stdout { codec => rubydebug }
}
使用配置文件运行logstash
logstash -f ./elk.conf
运行成功以后输入以及标准输出结果

logstash的插件类型
Input插件
权威指南:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
file插件的使用
# vim /etc/logstash/conf.d/elk.conf
添加如下配置
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
运行logstash指定elk.conf配置文件,进行过滤匹配
#logstash -f /etc/logstash/conf.d/elk.conf
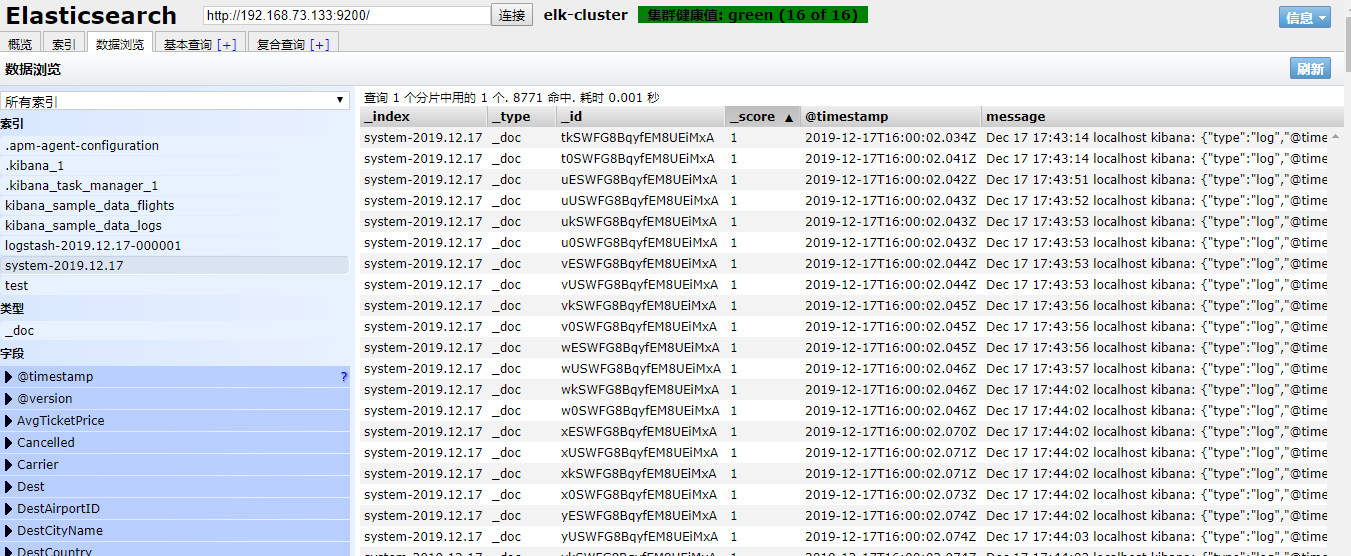
来一发配置安全日志的并且把日志的索引按类型做存放,继续编辑elk.conf文件
vim /etc/logstash/conf.d/elk.conf
添加secure日志的路径
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
file {
path => "/var/log/secure"
type => "secure"
start_position => "beginning"
}
}
output {
if [type] == "system" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-system-%{+YYYY.MM.dd}"
}
}
if [type] == "secure" {
elasticsearch {
hosts => ["192.168.1.202:9200"]
index => "nagios-secure-%{+YYYY.MM.dd}"
}
}
}
运行logstash指定elk.conf配置文件,进行过滤匹配
[root@elk-master ]# logstash -f /etc/logstash/conf.d/elk.conf
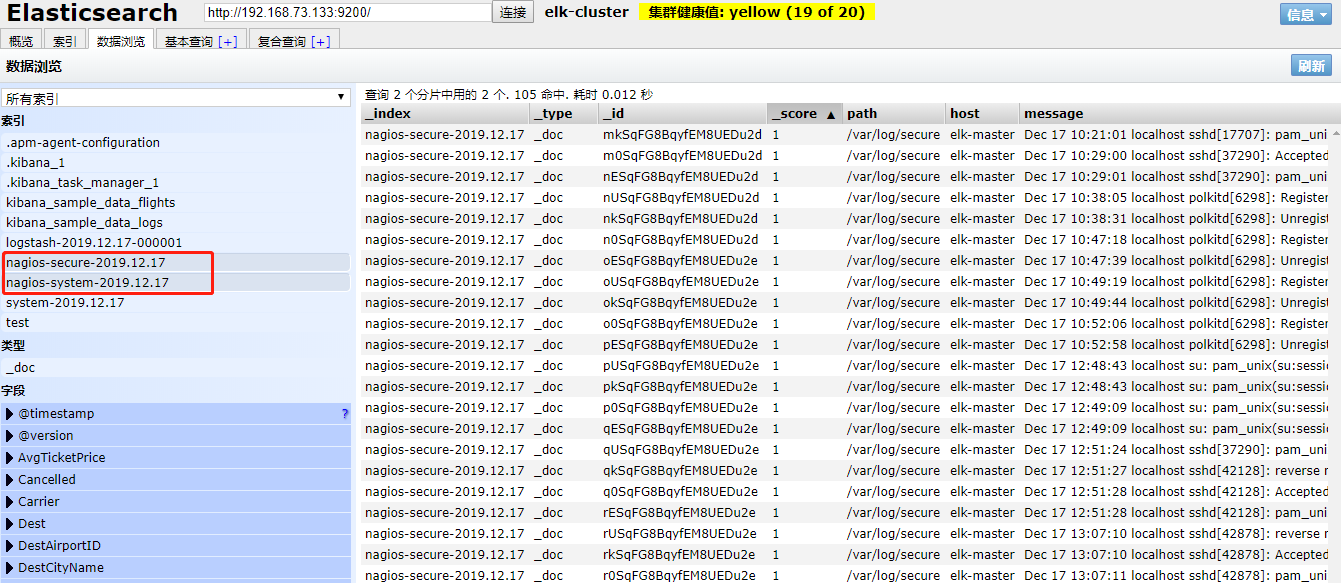
这些设置都没有问题之后,接下来安装下kibana,可以让在前台展示
Kibana的安装及使用
安装kibana环境
官方手册:https://www.elastic.co/guide/en/kibana/current/install.html
下载kibana的tar.gz的软件包
# yum install -y kibana
编辑kibana的配置文件
# vim /etc/kibana/kibana.yml
修改配置文件如下,开启以下的配置
server.port: 5601
server.host: "192.168.99.185"
elasticsearch.hosts: ["http://192.168.99.185:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"
启动服务并设置开机启动
# systemctl start kibana &&systemctl enable kibana
查看服务端口监听情况
# netstat -auntlp |grep 5601
tcp 0 0 192.168.73.133:5601 0.0.0.0:* LISTEN 61996/node
Kibana访问方式
http://192.168.73.133:5601
等待加载完毕之后的界面如图所示
添加样本数据
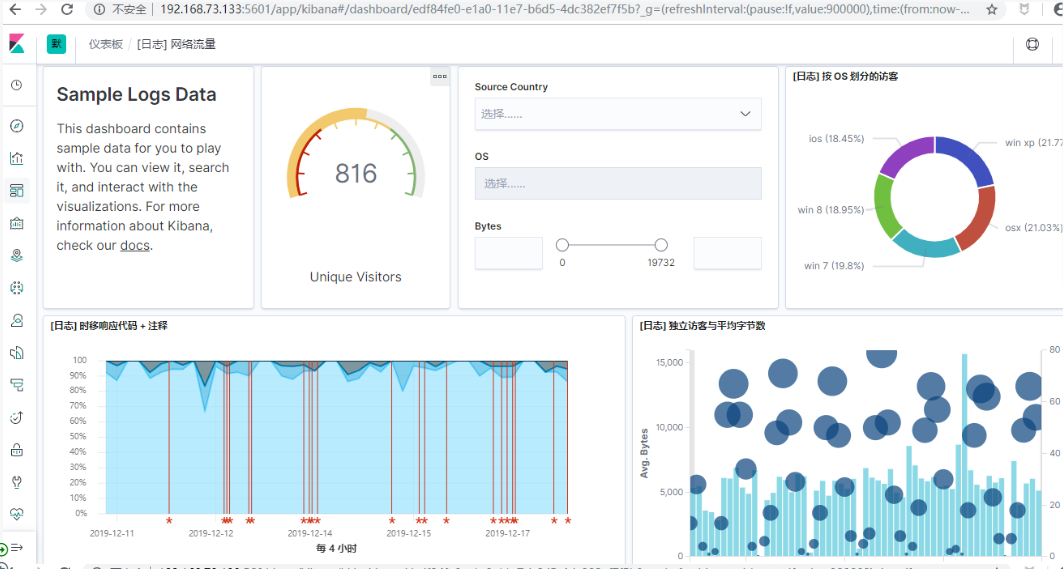
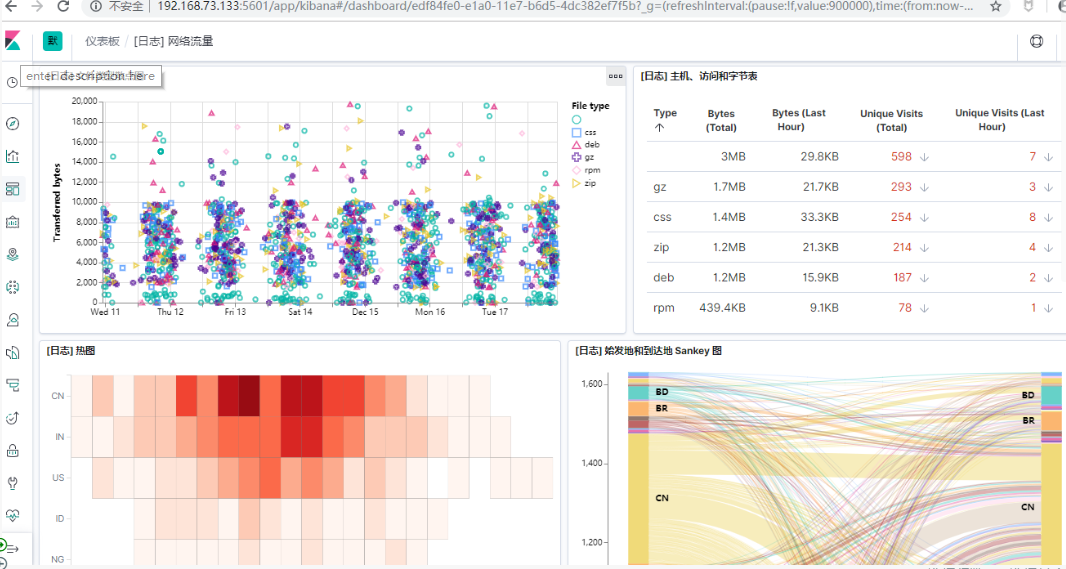
样本数据仪表盘
专注开源的DevOps技术栈技术,可以关注公众号,有问题欢迎一起交流

快速搭建ELK7.5版本的日志分析系统--搭建篇的更多相关文章
- ELK日志分析系统搭建
之前一段时间由于版本迭代任务紧,组内代码质量不尽如人意.接二连三的被测试提醒后台错误之后, 我们决定搭建一个后台日志分析系统, 经过几个方案比较后,选择的相对更简单的ELK方案. ELK 是Elast ...
- Docker搭建ElasticSearch+Redis+Logstash+Filebeat日志分析系统
一.系统的基本架构 在以前的博客中有介绍过在物理机上搭建ELK日志分析系统,有兴趣的朋友可以看一看-------------->>链接戳我<<.这篇博客将介绍如何使用Docke ...
- Rsyslog+ELK日志分析系统搭建总结1.0(测试环境)
因为工作需求,最近在搭建日志分析系统,这里主要搭建的是系统日志分析系统,即rsyslog+elk. 因为目前仍为测试环境,这里说一下搭建的基础架构,后期上生产线再来更新最后的架构图,大佬们如果有什么见 ...
- CentOs 7.3下ELK日志分析系统搭建
系统环境 为了安装时不出错,建议选择这两者选择一样的版本,本文全部选择5.3版本. System: Centos release 7.3 Java: openjdk version "1.8 ...
- ELK日志分析系统搭建(转)
摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticSearch,一款基于Apache Lucene的开源分布式搜索引擎)中便于查找和分析,在研究 ...
- ELK大流量日志分析系统搭建
1.首先说下EKL到底是什么吧? ELK是Elasticsearch(相当于仓库).Logstash(相当于旷工,挖矿即采集数据).Kibana(将采集的数据展示出来)的简称,这三者是核心套件,但并非 ...
- ELK日志分析系统搭建 windows
1 分别下载elk包 下载地址 https://www.elastic.co/cn/downloads 2 将这三个解压到同一个目录下,便于管理 3 elasticsearch不需要修改配置 默认即可 ...
- CentOS7下Elastic Stack 5.0日志分析系统搭建
原文链接:http://www.2cto.com/net/201612/572296_3.html 在http://localhost:5601下新建索引页面输入“metricbeat-*”,之后ki ...
- Rsyslog+ELK日志分析系统
转自:https://www.cnblogs.com/itworks/p/7272740.html Rsyslog+ELK日志分析系统搭建总结1.0(测试环境) 因为工作需求,最近在搭建日志分析系统, ...
随机推荐
- JSP、JSTL标签、EL表达式
JSP.JSTL标签.EL表达式 1.EL表达式:${} 功能: 获取数据 执行运算 获取web开发的常用对象 2.JSP标签 例如: jsp标签还有很多功能,这里只列举出一种. <jsp:fo ...
- 云南农职《JavaScript交互式网页设计》 综合机试试卷①——实现购物车的结算
一.语言和环境 实现语言:javascript.html.css. 开发环境:HBuilder. 二.题目2(100分) 1.功能需求: 马上过节了,电商网站要进行促销活动,需要实现该商城购物车的商品 ...
- 在 jQuery 中使用滑入滑出动画效果,实现二级下拉导航菜单的显示与隐藏效果
查看本章节 查看作业目录 需求说明: 在 jQuery 中使用滑入滑出动画效果,实现二级下拉导航菜单的显示与隐藏效果 用户将光标移动到"最新动态页"或"帮助查询" ...
- JZOJ5966. [NOIP2018TGD2T3] 保卫王国 (动态DP做法)
题目大意 这还不是人尽皆知? 有一棵树, 每个节点放军队的代价是\(a_i\), 一条边连接的两个点至少有一个要放军队, 还有\(q\)次询问, 每次规定其中的两个一定需要/不可放置军队, 问这样修改 ...
- 关于MySQL导入数据到elasticsearch的小工具logstash
logstash核心配置文件pipelines.yml #注:此处的 - 必须顶格写必须!!! - pipeline.id: invitation #下面路径配置的是你同步数据是的字段映射关系 pat ...
- Pytest_配置文件-pytest.ini(4)
pytest配置文件可以改变pytest的默认运行方式,它是一个固定的文件名称pytest.ini. 存放路径为项目的根目录 解决中文报错 在讲解配置文件的可用参数前,我们先解决一个高概率会遇到的问题 ...
- mybatis-plus实现多表联查
一.方法一 1.在pojo模块下新建一个VO 包路径用于提供页面展示所需的数据 2.在vo包下新建EmployInfo类,此类继承了Employees类,再把Dept类的数据复制过来 3.在Dao层中 ...
- maven pom.xml 的 spring-boot-maven-plugin 红色报错 解决
解决方法,添加对应的spring boot 版本号即可
- [转]Vue之引用第三方JS插件
1.绝对路径引入,全局使用. 在index.html文件中使用script标签引入插件. 该种方式就是上面演示ckplayer插件使用的方式. 备注: 这种方式的引用,会在开启ESLint时,报错,可 ...
- FIS 使用
从淘宝npm镜像安装fis $ npm install -g fis --registry=https://registry.npm.taobao.org 安装less插件 $ npm install ...