Elasticsearch(二)--集群原理及优化
一、ES原理
1、索引结构ES是面向文档的
各种文本内容以文档的形式存储到ES中,文档可以是一封邮件、一条日志,或者一个网页的内容。一般使用 JSON 作为文档的序列化格式,文档可以有很多字段,在创建索引的时候,我们需要描述文档中每个字段的数据类型,并且可能需要指定不同的分析器,就像在关系型数据中“CREATE TABLE”一样。在存储结构上,由_index、_type和_id唯一标识一个文档。
_index指向一个或多个物理分片的逻辑命名空间。_id文档标记符由系统自动生成或使用者提供。删除过期老化的数据时,最好以索引为单位,而不是_id。由于_type在实际应用中容易引起概念混淆,在ES 6.x版本中,一个索引只允许存在一个_type,7.x版本将完全删除_type的概念。
2、分片(shard)
在分布式系统中,单机无法存储规模巨大的数据,要依靠大规模集群处理和存储这些数据,一般通过增加机器数量来提高系统水平扩展能力。因此,需要将数据分成若干小块分配到各个机器上。然后通过某种路由策略找到某个数据块所在的位置。除了将数据分片以提高水平扩展能力,分布式存储中还会把数据复制成多个副本,放置到不同的机器中,这样一来可以增加系统可用性,同时数据副本还可以使读操作并发执行,分担集群压力。但是多数据副本也带来了一致性的问题:部分副本写成功,部分副本写失败。为了应对并发更新问题,ES将数据副本分为主从两部分,即主分片(primary shard)和副分片(replica shard)。主数据作为权威数据,写过程中先写主分片,成功后再写副分片,恢复阶段以主分片为准。数据分片和数据副本的关系如下图所示。
分片(shard)是底层的基本读写单元,分片的目的是分割巨大索引,让读写可以并行操作,由多台机器共同完成。读写请求最终落到某个分片上,分片可以独立执行读写工作。ES利用分片将数据分发到集群内各处。分片是数据的容器,文档保存在分片内,不会跨分片存储。分片又被分配到集群内的各个节点里。当集群规模扩大或缩小时,ES 会自动在各节点中迁移分片,使数据仍然均匀分布在集群里。
一个ES索引包含很多分片,一个分片是一个Lucene的索引,它本身就是一个完整的搜索引擎,可以独立执行建立索引和搜索任务。Lucene索引又由很多分段组成,每个分段都是一个倒排索引。ES每次“refresh”都会生成一个新的分段,其中包含若干文档的数据。在每个分段内部,文档的不同字段被单独建立索引。每个字段的值由若干词(Term)组成,Term是原文本内容经过分词器处理和语言处理后的最终结果(例如,去除标点符号和转换为词根)。
索引建立的时候就需要确定好主分片数,在较老的版本中(5.x 版本之前),主分片数量不可以修改,副分片数可以随时修改。现在(5.x~6.x 版本之后),ES 已经支持在一定条件的限制下,对某个索引的主分片进行拆分(Split)或缩小(Shrink)。但是,我们仍然需要在一开始就尽量规划好主分片数量:先依据硬件情况定好单个分片容量,然后依据业务场景预估数据量和增长量,再除以单个分片容量。分片数不够时,可以考虑新建索引,搜索1个有着50个分片的索引与搜索50个每个都有1个分片的索引完全等价,或者使用_split API来拆分索引(6.1版本开始支持)。
在实际应用中,我们不应该向单个索引持续写数据,直到它的分片巨大无比。巨大的索引会在数据老化后难以删除,以_id 为单位删除文档不会立刻释放空间,删除的 doc 只在 Lucene分段合并时才会真正从磁盘中删除。即使手工触发分段合并,仍然会引起较高的 I/O 压力,并且可能因为分段巨大导致在合并过程中磁盘空间不足(分段大小大于磁盘可用空间的一半)。因此,我们建议周期性地创建新索引。例如,每天创建一个。假如有一个索引website,可以将它命名为website_20180319。然后创建一个名为website的索引别名来关联这些索引。这样,对于业务方来说,读取时使用的名称不变,当需要删除数据的时候,可以直接删除整个索引。索引别名就像一个快捷方式或软链接,不同的是它可以指向一个或多个索引。可以用于实现索引分组,或者索引间的无缝切换。现在我们已经确定好了主分片数量,并且保证单个索引的数据量不会太大,周期性创建新索引带来的一个新问题是集群整体分片数量较多,集群管理的总分片数越多压力就越大。在每天生成一个新索引的场景中,可能某天产生的数据量很小,实际上不需要这么多分片,甚至一个就够。这时,可以使用_shrink API来缩减主分片数量,降低集群负载。
3、动态更新索引
为文档建立索引,使其每个字段都可以被搜索,通过关键词检索文档内容,会使用倒排索引的数据结构。倒排索引一旦被写入文件后就具有不变性,不变性具有许多好处:对文件的访问不需要加锁,读取索引时可以被文件系统缓存等。那么索引如何更新,让新添加的文档可以被搜索到?答案是使用更多的索引,新增内容并写到一个新的倒排索引中,查询时,每个倒排索引都被轮流查询,查询完再对结果进行合并。每次内存缓冲的数据被写入文件时,会产生一个新的Lucene段,每个段都是一个倒排索引。在一个记录元信息的文件中描述了当前Lucene索引都含有哪些分段。由于分段的不变性,更新、删除等操作实际上是将数据标记为删除,记录到单独的位置,这种方式称为标记删除。因此删除部分数据不会释放磁盘空间。
4、 近实时搜索
在写操作中,一般会先在内存中缓冲一段数据,再将这些数据写入硬盘,每次写入硬盘的这批数据称为一个分段,如同任何写操作一样。一般情况下(direct方式除外),通过操作系统write接口写到磁盘的数据先到达系统缓存(内存),write函数返回成功时,数据未必被刷到磁盘。通过手工调用flush,或者操作系统通过一定策略将系统缓存刷到磁盘。这种策略大幅提升了写入效率。从write函数返回成功开始,无论数据有没有被刷到磁盘,该数据已经对读取可见。ES正是利用这种特性实现了近实时搜索。每秒产生一个新分段,新段先写入文件系统缓存,但稍后再执行flush刷盘操作,写操作很快会执行完,一旦写成功,就可以像其他文件一样被打开和读取了。由于系统先缓冲一段数据才写,且新段不会立即刷入磁盘,这两个过程中如果出现某些意外情况(如主机断电),则会存在丢失数据的风险。通用的做法是记录事务日志,每次对ES进行操作时均记录事务日志,当ES启动的时候,重放translog中所有在最后一次提交后发生的变更操作。比如HBase等都有自己的事务日志。
5、段合并
在ES中,每秒清空一次写缓冲,将这些数据写入文件,这个过程称为refresh,每次refresh会创建一个新的Lucene 段。但是分段数量太多会带来较大的麻烦,每个段都会消耗文件句柄、内存。每个搜索请求都需要轮流检查每个段,查询完再对结果进行合并;所以段越多,搜索也就越慢。因此需要通过一定的策略将这些较小的段合并为大的段,常用的方案是选择大小相似的分段进行合并。在合并过程中,标记为删除的数据不会写入新分段,当合并过程结束,旧的分段数据被删除,标记删除的数据才从磁盘删除。HBase、Cassandra等系统都有类似的分段机制,写过程中先在内存缓冲一批数据,不时地将这些数据写入文件作为一个分段,分段具有不变性,再通过一些策略合并分段。分段合并过程中,新段的产生需要一定的磁盘空间,我们要保证系统有足够的剩余可用空间。Cassandra系统在段合并过程中的一个问题就是,当持续地向一个表中写入数据,如果段文件大小没有上限,当巨大的段达到磁盘空间的一半时,剩余空间不足以进行新的段合并过程。如果段文件设置一定上限不再合并,则对表中部分数据无法实现真正的物理删除。ES存在同样的问题。
6、节点
在Elasticsearch中,每个节点可以有多个角色,节点既可以是候选主节点,也可以是数据节点。其中,数据节点负责数据的存储相关的操作,如对数据进行增、删、改、查和聚合等。正因为如此,数据节点往往对服务器的配置要求比较高,特别是对CPU、内存和I/O的需求很大。此外,数据节点梳理通常随着集群的扩大而弹性增加,以便保持Elasticsearch服务的高性能和高可用。候选主节点是被选举为主节点的节点,在集群中,只有候选主节点才有选举权和被选举权,其他节点不参与选举工作。一旦候选主节点被选举为主节点,则主节点就要负责创建索引、删除索引、追踪集群中节点的状态,以及跟踪哪些节点是群集的一部分,并决定将哪些分片分配给相关的节点等。
二、集群
2.4)集群(cluster)
(1)集群由一个或多个节点组成,对外提供服务,对外提供索引和搜索功能。在所有节点,一个集群有一个唯一的名称默认为“Elasticsearch”。此名称是很重要的,因为每个节点只能是集群的一部分,当该节点被设置为相同的集群名称时,就会自动加入集群(开启广播模式)。当需要有多个集群的时候,要确保每个集群的名称不能重复,否则,节点可能会加入错误的集群。
注意:
- 一个节点只能加入一个集群。此外,还可以拥有多个独立的集群,每个集群都有其不同的集群名称。例如,在开发过程中,可以建立开发集群库和测试集群库。
- 当扩容集群、添加节点时,分片会均衡地分配到集群的各个节点,从而对索引和搜索过程进行负载均衡,这些都是系统自动完成的。
- 分布式系统中难免出现故障,当节点异常时,ES会自动处理节点异常。当主节点异常时,集群会重新选举主节点。当某个主分片异常时,会将副分片提升为主分片。
eg: 拥有三个节点的集群——为了分散负载而对分片进行重新分配
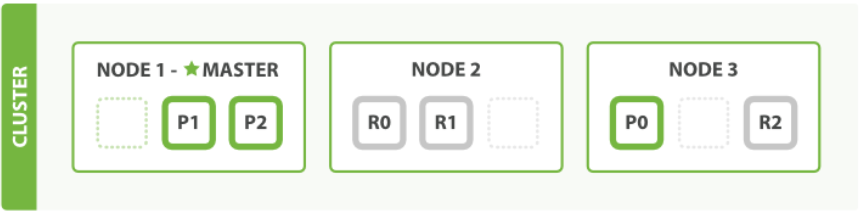
Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥有2个分片,而不是之前的3个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片的性能将会得到提升。
分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 以上这个拥有6个分片(3个主分片和3个副本分片)的索引可以最大扩容到6个节点,每个节点上存在一个分片,并且每个分片拥有所在节点的全部资源。
(2)分片策略
分片分配过程是分片到节点的一个处理过程,它可能发生在初始恢复过程中,副本分配中,再平衡过程中,或当节点被添加或删除时。
(2.1)分片分配设置
下面的动态设置可以用来控制分片的分配和回收。
□cluster.routing.allocation.enable:禁用或启用哪种类型的分片,可选的参数有:
·all——允许所有的分片被重新分配。
·primaries——只允许主结点分片被重新分配。
·new_primaries——只允许新的主结点索引的分片被重新分配。
·none——不对任何分片进行重新分配。
□cluster.routing.allocation.node_concurrent_recoveries:允许在一个节点上同时并发多少个分片分配,默认为2。
□cluster.routing.allocation.node_initial_primaries_recoveries:当副本分片加入集群的时候,在一个节点上并行发生分片分配的数量,默认是4个。 □cluster.routing.allocation.same_shard.host:在一个主机上的当有多个相同的集群名称的分片分配时,是否进行检查,检查主机名和主机ip地址。默认为false,此设置仅适用于在同一台机器上启动多个节点时配置。
- indices.recovery.concurrent_streams:从一个节点恢复的时候,同时打开的网络流量的数量,默认为3。
- indices.recovery.concurrent_small_file_streams:从同伴的分片恢复时打开每个节点的小文件(小于5M)流的数目,默认为2。
(2.2)分片平衡设置
下面的动态设置可以用来控制整个集群的碎片再平衡,配置有:
□cluster.routing.rebalance.enable:启用或禁用特定种类的分片重新平衡,可选的参数有:
·all——允许所有的分片进行分片平衡,默认配置。
·primaries——只允许主分片进行平衡。
·replicas——只允许从分片进行平衡。
·none——不允许任何分片进行平衡。
□cluster.routing.allocation.allow_rebalance:当分片再平衡时允许的操作,可选的参数有:
·always——总是允许再平衡。
·indices_primaries_active——只有主节点索引允许再平衡。
·indices_all_active——所有的分片允许再平衡,默认参数。
·cluster.routing.allocation.cluster_concurrent_rebalance:重新平衡时允许多少个并发的分片同时操作,默认为2。
(2.3)启发式分片平衡
以下设置用于确定在何处放置每个碎片的数据:
□cluster.routing.allocation.balance.shard:在节点上分配每个分片的权重,默认是0.45。
□cluster.routing.allocation.balance.index:在特定节点上,每个索引分配的分片的数量,默认0.55。
□cluster.routing.allocation.balance.threshold:操作的最小最优化的值。默认为1。
2.5).节点(node)
(1)一个节点是一个逻辑上独立的服务,它是集群的一部分,可以存储数据,并参与集群的索引和搜索功能。节点也有唯一的名字,在启动的时候分配。该名称是在启动时分配给节点的随机通用唯一标识符(UUID),支持自定义名称。这个名字在管理中很重要,在网络中Elasticsearch集群通过节点名称进行管理和通信。一个节点可以被配置加入一个特定的集群。默认情况下,每个节点会加入名为Elasticsearch的集群中,这意味着如果你在网络上启动多个节点,如果网络畅通,他们能彼此发现并自动加入一个名为Elasticsearch的集群中。当网络没有集群运行的时候,只要启动任何一个节点,这个节点会默认生成一个新的集群,这个集群会有一个节点。
(2)节点类型
主(master)节点:在一个节点上当node.master设置为true(默认)的时候,它有资格被选作为主节点,控制整个集群。它将负责管理:集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。
数据(data)节点:在一个节点上node.data设置为true(默认)的时候。该节点保存数据和执行数据相关的操作,如增删改查、搜索和聚合。默认情况下,节点同时是主节点和数据节点,这是非常方便的小集群,但随着集群的发展,分离主节点和数据节点将变得非常重要。
客户端节点:当一个节点的node.master和node.data都设置为false的时候,它既不能保持数据也不能成为主节点,该节点可以作为客户端节点,可以响应用户的请求,并把相关操作发送到其他节点。
部落节点:当一个节点配置tribe.*的时候,它是一个特殊的客户端,它可以连接多个集群,在所有连接的集群上执行搜索和其他操作。
客户端节点在搜索请求或批量增加索引请求等可能涉及在不同数据节点上的操作。这些请求会分成两个阶段,一是接收客户端的请求,二是协调节点执行相关操作。当数据分散在不同的节点上时,协调节点将请求转发到数据节点,每个数据节点在本地执行请求并把结果传输给协调节点,然后协调节点收集各个数据节点的结果转换成单个请求结果返回。所以需要客户端有足够的内存和CPU来处理各个节点的返回结果。
2.6)路由(routing)
当存储一个文档的时候,它会存储在唯一的主分片中,具体哪个分片是通过散列值进行选择。默认情况下,这个值是由文档的ID生成。如果文档有一个指定的父文档,则从父文档ID中生成,该值可以在存储文档的时候进行修改。
2.7)分片(shard)
分片是单个Lucene实例,这是Elasticsearch管理的比较底层的功能。索引是指向主分片和副本分片的逻辑空间。对于使用,只需要指定分片的数量,其他不需要做过多的事情。在开发使用的过程中,我们对应的对象都是索引,Elasticsearch会自动管理集群中所有的分片,当发生故障的时候,Elasticsearch会把分片移动到不同的节点或者添加新的节点。一个索引可以存储很大的数据,这些空间可以超过一个节点的物理存储的限制。例如,十亿个文档占用磁盘空间为1TB。仅从单个节点搜索可能会很慢,还有一台物理机器也不一定能存储这么多的数据。为了解决这一问题,Elasticsearch将索引分解成多个分片。当你创建一个索引,你可以简单地定义你想要的分片数量。每个分片本身是一个全功能的、独立的单元,可以托管在集群中的任何节点。
2.8)主分片(primary shard)
每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。默认情况下,一个索引有5个主分片。你可以事先制定分片的数量,当分片一旦建立,则分片的数量不能修改。
2.9)副本分片(replica shard)
每一个分片有零个或多个副本。副本主要是主分片的复制,其中有两个目的:
增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。
提高性能:当查询的时候可以到主分片或者副本分片中进行查询。
默认情况下,一个主分片配有一个副本,但副本的数量可以在后面动态地配置增加。副本分片必须部署在不同的节点上,不能部署在和主分片相同的节点上。分片主要有两个很重要的原因是:
允许水平分割扩展数据。
允许分配和并行操作(可能在多个节点上)从而提高性能和吞吐量。
这些很强大的功能对用户来说是透明的,你不需要做什么操作,系统会自动处理。
2.10)复制(replica)
复制是一个非常有用的功能,不然会有单点问题。当网络中的某个节点出现问题的时候,复制可以对故障进行转移,保证系统的高可用。因此,Elasticsearch允许你创建一个或多个拷贝,你的索引分片就形成了所谓的副本或副本分片。复制是重要的,主要的原因有:□它提供了高可用性,当节点失败的时候不受影响。需要注意的是,一个复制的分片不会存储在同一个节点中。□它允许你扩展搜索量,提高并发量,因为搜索可以在所有副本上并行执行。每个索引可以拆分成多个分片。索引可以复制零个或者多个分片。一旦复制,每个索引就有了主分片和副本分片。分片的数量和副本的数量可以在创建索引时定义。当创建索引后,你可以随时改变副本的数量,但你不能改变分片的数量。默认情况下,每个索引分配5个分片和一个副本,这意味着你的集群节点至少要有两个节点,你将拥有5个主要的分片和5个副本分片共计10个分片。[插图]注意 每个Elasticsearch分片是一个Lucene的索引。有文档存储数量限制,你可以在一个单一的Lucene索引中存储的最大值为lucene-5843,极限是2147483519(=integer.max_value-128)个文档。你可以使用_cat/shards API监控分片的大小。
三、es结构
1、es模块结构图
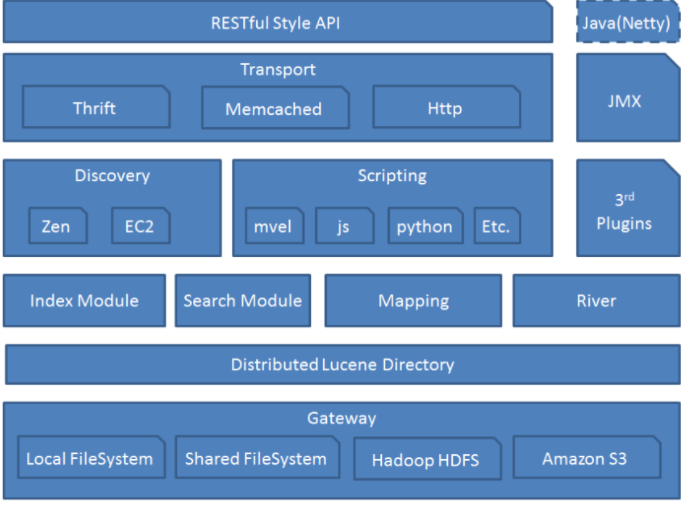
Gateway: 代表ES的持久化存储方式,包含索引信息,ClusterState(集群信息),mapping,索引碎片信息,以及transaction log等;
- 对于分布式集群来说,当一个或多个节点down掉了,能够保证我们的数据不能丢,最通用的解决方案就是对失败节点的数据进行复制,通过控制复制的份数可以保证集群有很高的可用性,复制这个方案的精髓主要是保证操作的时候没有单点,对一个节点的操作会同步到其他的复制节点上去。
- ES一个索引会拆分成多个碎片,每个碎片可以拥有一个或多个副本(创建索引的时候可以配置),如下:每个索引分成3个碎片,每个碎片有2个副本
$ curl -XPUT http://localhost:9200/twitter/ -d '
index :
number_of_shards : 3
number_of_replicas : 2 每个操作会自动路由主碎片所在的节点,在上面执行操作,并且同步到其他复制节点,通过使用“non blocking IO”模式所有复制的操作都是并行执行的,也就是说如果你的节点的副本越多,你网络上的流量消耗也会越大。复制节点同样接受来自外面的读操作,意义就是你的复制节点越多,你的索引的可用性就越强,对搜索的可伸缩行就更好,能够承载更多的操作。
- 第一次启动的时候,它会去持久化设备读取集群的状态信息(创建的索引,配置等)然后执行应用它们(创建索引,创建mapping映射等),每一次shard节点第一次实例化加入复制组,它都会从长持久化存储里面恢复它的状态信息。
Discovery
Discovery模块负责发现集群中的节点,以及选择主节点。ES支持多种不同Discovery类型选择,内置的实现称为Zen Discovery,其他的包括公有云平台亚马逊的EC2、谷歌的GCE等。
节点启动后先ping(这里的ping是 Elasticsearch 的一个RPC命令。如果 discovery.zen.ping.unicast.hosts 有设置,则ping设置中的host,否则尝试ping localhost 的几个端口, Elasticsearch 支持同一个主机启动多个节点);
Ping的response会包含该节点的基本信息以及该节点认为的master节点;
选举开始,先从各节点认为的master中选,规则很简单,按照id的字典序排序,取第一个;
如果各节点都没有认为的master,则从所有节点中选择,规则同上。这里有个限制条件就是 discovery.zen.minimum_master_nodes,如果节点数达不到最小值的限制,则循环上述过程,直到节点数足够可以开始选举;
最后选举结果是肯定能选举出一个master,如果只有一个local节点那就选出的是自己;
如果当前节点是master,则开始等待节点数达到 minimum_master_nodes,然后提供服务, 如果当前节点不是master,则尝试加入master;
ES支持任意数目的集群(1-N),通过一个规则,只要所有的节点都遵循同样的规则,得到的信息都是对等的,选出来的主节点肯定是一致的。但分布式系统的问题就出在信息不对等的情况,这时候很容易出现脑裂(Split-Brain)的问题,大多数解决方案就是设置一个quorum值,要求可用节点必须大于quorum(一般是超过半数节点,(master_eligible_nodes / 2) + 1,例如,如果有3个具备Master资格的节点,则这个值至少应该设置为(3/2)+ 1 = 2),才能对外提供服务。而 Elasticsearch 中,这个quorum的配置就是 discovery.zen.minimum_master_nodes ;
memcached
通过memecached协议来访问ES的接口,支持二进制和文本两种协议.通过一个名为transport-memcached插件提供
Memcached命令会被映射到REST接口,并且会被同样的REST层处理,memcached命令列表包括:get/set/delete/quit
2、es存储结构

四、es优化方式
1、写入速度优化
在 ES 的默认设置下,是综合考虑数据可靠性、搜索实时性、写入速度等因素的。有时候,业务上对数据可靠性和搜索实时性要求并不高,反而对写入速度要求很高,此时可以调整一些策略,可以牺牲可靠性和搜索实时性为代价,最大化写入速度。
从以下几方面入手:
- 加大translog flush间隔,目的是降低iops、writeblock。
- 加大index refresh间隔,除了降低I/O,更重要的是降低了segment merge频率。
- 调整bulk请求。
- 优化磁盘间的任务均匀情况,将shard尽量均匀分布到物理主机的各个磁盘。
- 优化节点间的任务分布,将任务尽量均匀地发到各节点。
- 优化Lucene层建立索引的过程,目的是降低CPU占用率及I/O,例如,禁用_all字段。
2、搜索速度的优化
1)有些字段的内容是数值,但并不意味着其总是应该被映射为数值类型,例如,一些标识符,将它们映射为keyword可能会比integer或long更好。
2)预热文件系统cache
如果ES主机重启,则文件系统缓存将为空,此时搜索会比较慢。可以使用index.store.preload设置,通过指定文件扩展名,显式地告诉操作系统应该将哪些文件加载到内存中,在索引创建时设置:
PUT /my_index{"settings": {"index.store.preload": ["nvd", "dvd"]}}
注意:如果文件系统缓存不够大,则无法保存所有数据,那么为太多文件预加载数据到文件系统缓存中会使搜索速度变慢,应谨慎使用。
3)一个搜索请求涉及的分片数量越多,协调节点的CPU和内存压力就越大。默认情况下,ES会拒绝超过1000个分片的搜索请求。因此应该更好地组织数据,让搜索请求的分片数更少。如果想调节这个值,则可以通过action.search.shard_count配置项进行修改。虽然限制搜索的分片数并不能直接提升单个搜索请求的速度,但协调节点的压力会间接影响搜索速度,例如,占用更多内存会产生更多的GC压力,可能导致更多的stop-the-world时间等,因此间接影响了协调节点的性能。
官放文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/elasticsearch-intro.html
感谢阅读,借鉴了不少大佬资料,整合了一个相对系统、简洁、针对项目研发较为实用的版本,如需转载,请注明出处,谢谢!https://www.cnblogs.com/huyangshu-fs/p/12181057.html
-i
Elasticsearch(二)--集群原理及优化的更多相关文章
- elasticsearch 基础 —— 集群原理
空集群 如果我们启动了一个单独的节点,里面不包含任何的数据和 索引,那我们的集群看起来就是一个 图 1 "包含空内容节点的集群". 图 1. 包含空内容节点的集群 一个运行中的 E ...
- Elasticsearch 分片集群原理、搭建、与SpringBoot整合
单机es可以用,没毛病,但是有一点我们需要去注意,就是高可用是需要关注的,一般我们可以把es搭建成集群,2台以上就能成为es集群了.集群不仅可以实现高可用,也能实现海量数据存储的横向扩展. 新的阅读体 ...
- ELasticSearch(五)ES集群原理与搭建
一.ES集群原理 查看集群健康状况:URL+ /GET _cat/health (1).ES基本概念名词 Cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产 ...
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- J2EE集群原理(摘录)
J2EE集群原理 什么是集群呢?总的来说,集群包括两个概念:“负载均衡”(load balancing)和“失效备援”(failover) 图一:负载均衡 多个客户端同时发出请求,位于前端的负载均衡 ...
- kafka集群原理介绍
目录 kafka集群原理介绍 (一)基础理论 二.配置文件 三.错误处理 kafka集群原理介绍 @(博客文章)[kafka|大数据] 本系统文章共三篇,分别为 1.kafka集群原理介绍了以下几个方 ...
- PB级数据实时查询,滴滴Elasticsearch多集群架构实践
PB级数据实时查询,滴滴Elasticsearch多集群架构实践 mp.weixin.qq.com 点击上方"IT牧场",选择"设为星标"技术干货每日送达 点 ...
- ES的集群原理
文章转载自:https://www.cnblogs.com/soft2018/p/10213266.html 一.ES集群原理 查看集群健康状况:URL+ /GET _cat/health (1).E ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
随机推荐
- 17. yum
https://www.linuxidc.com/Linux/2015-04/116331.htm
- 前端知识,什么是BFC?
BFC全称是Block Formatting Context,即块格式化上下文.它是CSS2.1规范定义的,关于CSS渲染定位的一个概念.要明白BFC到底是什么,首先来看看什么是视觉格式化模型. 视觉 ...
- 【Reverse】每日必逆0x01
附件:https://files.buuoj.cn/files/7458c5c0ce999ac491df13cf7a7ed9f1/SimpleRev 题解 查壳 64位ELF文件,无壳 IDApro处 ...
- C++ 写出这个数
题目如下: 读入一个正整数 n,计算其各位数字之和,用汉语拼音写出和的每一位数字. 输入格式: 每个测试输入包含 1 个测试用例,即给出自然数 n 的值.这里保证 n 小于 1. 输出格式: 在一行内 ...
- Python实战之MySQL数据库操作
1. 要想使Python可以操作MySQL数据库,首先需要安装MySQL-python包,在CentOS上可以使用一下命令来安装 $ sudo yum install MySQL-python 2. ...
- 多线程异步操作导致异步线程获取不到主线程的request信息
org.springframework.web.context.request.RequestContextHolderorg.springframework.web.context.request. ...
- 【Service】【Database】【MySQL】基础
1. 概念 1.1. 作者:Unireg 1.2. MySQL AB --> MySQL Solaris:二进制版本: 1.3. 官方网站: MySQL: www.mysql.com Maria ...
- mybatis分页插件PageHelper源码浅析
PageHelper 是Mybaties中的一个分页插件.其maven坐标 <!-- https://mvnrepository.com/artifact/com.github.pagehelp ...
- ActiveMQ(三)——理解和掌握JMS(1)
一.JMS基本概念 JMS是什么JMS Java Message Service,Java消息服务,是JavaEE中的一个技术. JMS规范JMS定义了Java中访问消息中间件的接囗,并没有给予实现, ...
- 【JS】toLocaleString 日期格式,千分位转换
https://blog.csdn.net/Seven521m/article/details/108866881 类似于c里printf(m%)的意思 可以指定整数最少位数,小数最少与最多位数,有效 ...