Normalization Methods
概
整理一下各种normalization方法.
主要内容
对于每一层, 可以简化的理解为:
\]
其中\(h^{l}\)是前一层的输入, \(W, b\)分别为该层的权重和偏置, \(f\)是对应的激活函数.
但是仅按照这种方式搭建的网络训练不稳定还非常慢, 这也是为什么各种normalization方法被提出的初衷.
这些方法可以统一为:
\]
这里用\(g(\cdot)\)表示某种normalization方法.
为了方便起见, 另外令
y = g(x).
\]
总的示意图如下(图片来自Group Normalization):
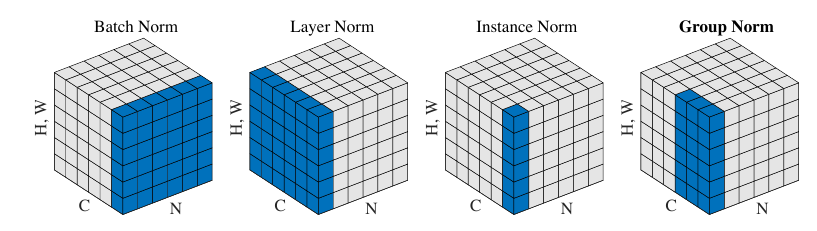
Batch Normalization
该normalization方法思想是最朴素的, 即每一次我们都recentering一下数据:
\]
这里\(\mu,\sigma\)分别表示\(x\)的均值和标准差.
但是上述的标准化存在均值和标准差的估计问题, 故在训练中我们取一个batch作为估计:
\]
其中\(x^i, i=1,2,\cdots, n\)为一个batch的数据.
在实际中, 为了安全和可扩展, 采取如下形式:
\]
其中\(\gamma, \beta\)为weight 和 bias, \(\epsilon\)常取1e-5.
在训练中, 每次forward pass都会更新running_mean \(\mu\), running_var \(\sigma^2\):
\sigma^2 = (1 - m) \cdot \sigma^2 + m \cdot \hat{\sigma}^2.
\]
这里\(m\)是用于滑动平均的momentum, 这里采取这种形式是为了和Pytorch的实现保持一致, 其选择\(m=0.1\).
在evaluation中, 我们变使用\(\mu, \sigma^2\)来normalization:
\]
注: 在处理\(dim=1\)(即向量数据)的时候, 均值和方差的计算就是普通的, 但是\(dim=2\)的时候, 比如常见的卷积mapping, 其结构为\(N \times C \times H \times W\), 则其均值方差是对于每一个通道计算的, 即\(\mu,\sigma \in \mathbb{R}^C\), 同理\(\gamma, \beta \in \mathbb{R}^C\).
Layer Normalization
显然, batch normalization的batch size 不能太小, 而layer normalization 可以处理这一点, 因为它是针对单个样本而言的.
其同样采取
\]
的形式, 只是
\]
这里\(x_i\)表示\(x\)的第\(i\)个分量, 特征维度为\(H\).
注: 在Pytorch的实现中, \(\gamma, \beta\)都是element-wise的, 即如果我们选取\(C \times H \times W\), 则\(\gamma, \beta \in \mathbb{R}^{C \times H \times W}\).
Instance Normalization
instance normalization 主要是用于消除图片之间的contrast而提出的:
\]
注意, instance的normalization同样是基于单个样本而言的, 对于卷积层而言\(N \times C \times H \times W\):
\hat{\sigma} := \sqrt{\frac{1}{HW}\sum_i \sum_j (x_{ij} - \hat{\mu})^2},
\]
显然\(\hat{\mu}, \hat{\sigma} \in \mathbb{R}^C\). 对于向量数据而言, 和layernorm其实是一致的.
注: instance normalization 通常没有放射变换(即舍弃\(\gamma, \beta\)).
Group Normalization
GN则是根据通道\(C\)分成\(G\)个group, 对每一个group沿着\(H, W\)方向估计:
\hat{\sigma}_g := \sqrt{\frac{1}{(C / G) \cdot HW} \sum_{i=1}^H\sum_{j=1}^W\sum_{k=(g - 1)\cdot \frac{C}{G} + 1}^{g * \frac{C}{G}} (x_{kij} - \hat{\mu}_g)^2}, \\
g = 1, 2, \cdots, G.
\]
注: 这里假设\(C\)能够整除\(G\).
注: 当\(G=C\)的时候, GN 就是 IN, \(G=1\)的时候, GN就是LN.
Normalization Methods的更多相关文章
- 机器学习中的标准化方法(Normalization Methods)
希望这篇随笔能够从一个实用化的角度对ML中的标准化方法进行一个描述.即便是了解了标准化方法的意义,最终的最终还是要:拿来主义,能够在实践中使用. 动机:标准化的意义是什么? 我们为什么要标准化?想象我 ...
- JabRef 文献管理软件
JabRef 文献管理软件简明教程 大多只有使用LaTeX撰写科技论文的研究人员才能完全领略到JabRef的妙不可言,但随着对Word写作平台上BibTeX4Word插件的开发和便利应用,使用Word ...
- 大规模视觉识别挑战赛ILSVRC2015各团队结果和方法 Large Scale Visual Recognition Challenge 2015
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Legend: Yellow background = winner in thi ...
- LaTeX 的对参考文献的处理
LaTeX 的对参考文献的处理实在是非常的方便,我用过几次,有些体会,写出来供大家 参考.当然,自己的功力还不够深,有些地方问题一解决就罢手了,没有细究. LaTeX 对参考文献的处理有这 ...
- BIBTeX制作参考文献
一篇关于Latex的参考文献的好文章!基本问题都能解答~ 文章来源:http://www.cnblogs.com/longdouhzt/archive/2012/06/21/2557965.html ...
- latex bib format
LaTeX 的对参考文献的处理实在是非常的方便,我用过几次,有些体会,写出来供大家参考.当然,自己的功力还不够深,有些地方问题一解决就罢手了,没有细究. LaTeX 对参考文献的处理有这么一些优点: ...
- Spiking-YOLO : 前沿性研究,脉冲神经网络在目标检测的首次尝试 | AAAI 2020
论文提出Spiking-YOLO,是脉冲神经网络在目标检测领域的首次成功尝试,实现了与卷积神经网络相当的性能,而能源消耗极低.论文内容新颖,比较前沿,推荐给大家阅读 来源:晓飞的算法工程笔记 公众 ...
- Video processing systems and methods
BACKGROUND The present invention relates to video processing systems. Advances in imaging technology ...
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
随机推荐
- Hadoop入门 概念
Hadoop是分布式系统基础架构,通常指Hadoop生态圈 主要解决 1.海量数据的存储 2.海量数据的分析计算 优势 高可靠性:Hadoop底层维护多个数据副本,即使Hadoop某个计算元素或存储出 ...
- college-ruled notebook
TBBT.s3.e10: Sheldon: Where's your notebook?Penny: Um, I don't have one.Sheldon: How are you going t ...
- Scala(二)【基本使用】
一.变量和数据类型 1.变量 语法:val / var 变量名:变量类型 = 值 val name:String = "zhangsan" 注意 1.val定义的变量想到于java ...
- MySQL压力测试工具
一.MySQL自带的压力测试工具--Mysqlslap mysqlslap是mysql自带的基准测试工具,该工具查询数据,语法简单,灵活容易使用.该工具可以模拟多个客户端同时并发的向服务器发出查询更新 ...
- jvm的优化
a) 设置参数,设置jvm的最大内存数 b) 垃圾回收器的选择
- Oracle中的instr函数
最近修改某个条件,由原来输入一个数据修改为可以输入多个,如图所示: 在实现时用到了regexp_substr函数进行分割连接起来的数据,查询时还用到了instr函数进行判断,但出现了问题,当子库存输入 ...
- 端口占用,windows下通过命令行查看和关闭端口占用的进程
1.查找所有端口号对应的PID 端口号:8080 命令:netstat -ano|findstr "8080" 2.找到端口的PID并关闭 PID:1016 命令:taskkill ...
- java多线程4:volatile关键字
上文说到了 synchronized,那么就不得不说下 volatile关键字了,它们两者经常协同处理多线程的安全问题. volatile保证可见性 那么volatile的作用是什么呢? 在jvm运行 ...
- mobile app 与server通信的四种方式
Have you ever wondered how the information gets into the application installed in your mobile device ...
- 用 Go 实现一个 LRU cache
前言 早在几年前写过关于 LRU cache 的文章: https://crossoverjie.top/2018/04/07/algorithm/LRU-cache/ 当时是用 Java 实现的,最 ...