(数据科学学习手札132)Python+Fabric实现远程服务器连接
本文示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
日常工作中经常需要通过SSH连接到多台远程服务器来完成各种任务,当需要操作的服务器众多,且要执行的任务涉及命令繁多时,如果可以以自动化的方式模拟SSH连接及执行命令的繁琐过程,对工作效率的提升是非常可观的。
本文我就将带大家学习在Python中使用非常强大的fabric库来对常用的远程服务器连接管理操作进行自动化:

2 使用fabric玩转远程服务器管理
fabric基于强大的paramiko、invoke等库,构建出一整套简单易用的API,使得我们使用简洁的语句就可以应付常见的各种远程服务器操作,使用pip install fabric完成安装,本文演示对应版本为2.6。
2.1 连接到远程服务器并执行终端命令
要建立并保持对远程服务器的连接,我们需要对fabric.Connection()进行实例化,其基础参数有:
host: str型,格式如
'用户名@host:端口',其中':端口'部分可以省略,默认端口为22connect_kwargs: dict型,用于传入其他连接所需参数,常用的有:
- password: str型,当以密码方式连接时,用于传入与
host参数对应的密码 - pkey: str型,当以私钥方式连接时,用于设置对应密钥
- timeout: float型,用于设置
TCP连接的超时时长(单位:秒)
其他可用参数你可以前往
https://docs.paramiko.org/en/latest/api/client.html#paramiko.client.SSHClient.connect的Parameters了解更多- password: str型,当以密码方式连接时,用于传入与
config: fabric.Config型,用于设置更多复杂功能参数,详见
https://docs.fabfile.org/en/2.6/api/config.html
先来看一个最基础的例子:
from fabric import Connection
# 建议将ssh连接所需参数变量化
user = '用户名'
host = 'host地址'
password = '密码'
# 利用fabric.Connection快捷创建连接
c = Connection(host=f'{user}@{host}',
connect_kwargs=dict(
password=password
))
# 利用run方法直接执行传入的命令
c.run('pwd');
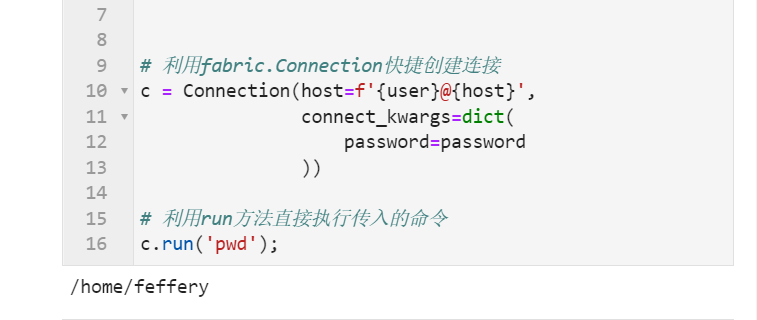
可以看到,非常简单就完成了连接服务器及执行指定命令的过程,且run()方法所执行的命令打印出的结果,可以通过stdout属性进行保存:
# hide=True抑制run()过程对执行结果的自动打印
output = c.run('df -h', hide=True).stdout
print(output)
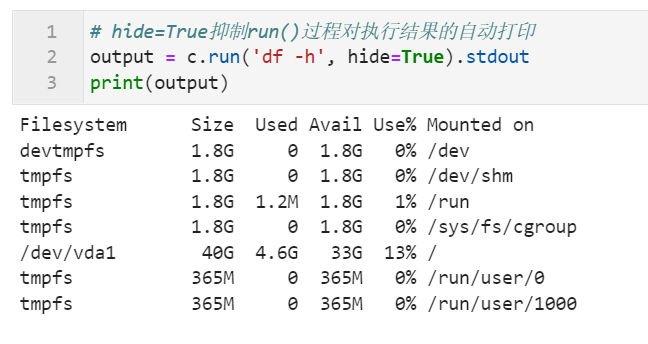
获悉了fabric的基础使用后,接下来我们来学习一些进阶内容:
2.2 配置sudo命令密码自动预填入
我们都知道,对于非root用户,在执行某些权限较高的命令时需要添加sudo前缀,并在会话的初次执行时需要手动输入当前用户的密码,而在fabric中,有两种方式可以实现这个步骤的自动化:
2.2.1 方式1:配合invoke.Responder
我们可以配合invoke.Responder来实现当命令行返回密码输入提示时,自动输入并执行指定的命令:
from invoke import Responder
# 配置命令行内容监听规则
sudopass = Responder(
pattern=f'\[sudo\] password for {user}:',
response=password+'\n'
)
# 注意需要设置pty=True
c.run('sudo pwd', pty=True, watchers=[sudopass]);

2.2.2 方式2:利用fabric.Config设置sudo密码
除了上一种方式外,我们还可以使用fabric.Config在创建连接时就一次性提前配置好sudo密码,之后需要执行sudo命令时用sudo()方法代替run()方法即可:
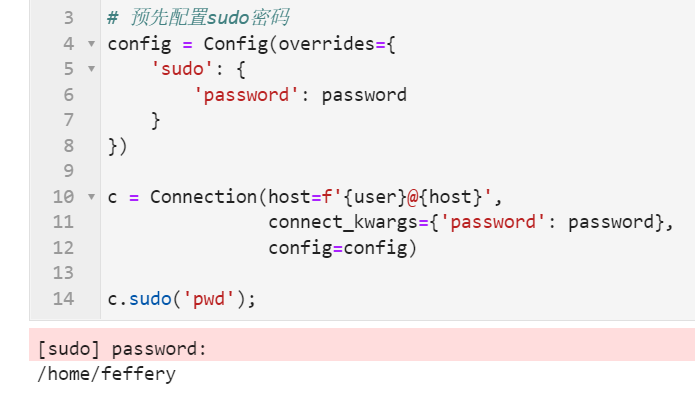
from fabric import Config
# 预先配置sudo密码
config = Config(overrides={
'sudo': {
'password': password
}
})
c = Connection(host=f'{user}@{host}',
connect_kwargs={'password': password},
config=config)
c.sudo('pwd');
2.3 远程文件传输
很多朋友都知道可以使用pscp、xshell之类的工具手动进行服务器与本地之间的文件相互传输,这些任务我们同样可以在fabric中自动化进行:
2.3.1 从本地上传文件到服务器
使用put()方法可以将指定的本地文件上传至服务器的指定位置,remote参数对应服务器目标保存位置:
c = Connection(host=f'{user}@{host}',
connect_kwargs={'password': password})
# 创建示例文件
with open('file_transfer.txt', 'w') as d:
d.write('1')
# 利用put方法上传至服务器
c.put('file_transfer.txt', remote='/home/feffery/')
# 打印已上传文件内容
c.run('cat /home/feffery/file_transfer.txt');

2.3.2 从服务器下载指定文件到本地
相反的,当我们需要从服务器取回指定文件到本地时,就可以使用get()方法:
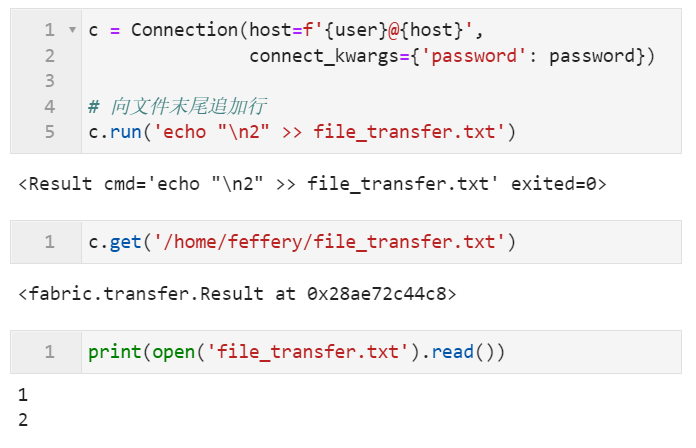
c = Connection(host=f'{user}@{host}',
connect_kwargs={'password': password})
# 向文件末尾追加行
c.run('echo "\n2" >> file_transfer.txt')
c.get('/home/feffery/file_transfer.txt')
print(open('file_transfer.txt').read())
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札132)Python+Fabric实现远程服务器连接的更多相关文章
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
随机推荐
- USB OTG原理和 ID 检测原理
OTG 检测的原理是: USB OTG标准在完全兼容USB2.0标准的基础上,增添了 电源管理(节省功耗)功能,它允许设备既可作为主机,也可作为外设操作(两用OTG).USB OTG技术可实现没有主机 ...
- 三极管和MOS管驱动电路的正确用法
1 三极管和MOS管的基本特性 三极管是电流控制电流器件,用基极电流的变化控制集电极电流的变化.有NPN型三极管(简称P型三极管)和PNP型三极管(简称N型三极管)两种,符号如下: MOS管是电压控制 ...
- AtCoder Grand Contest 055题解
我太菜啦!!!md,第一题就把我卡死了...感觉对构造题不会再爱了... A - ABC Identity 先来看这个题吧,题意就是给定你一个字符串,让你将这个字符串最多分成6个子串,使得每个字符都在 ...
- hdu 5175 Misaki's Kiss again(GCD和异或)
题意: 给一个数N. 如果GCD(N,M) = N XOR M,则称M是一个kiss 1<=M<=N 问总共有多少个kiss.并且列出所有的值. 思路: 思路一:枚举M.有大量的GCD ...
- Docker 搭建 Jenkins 持续集成自动化构建环境
1.Docker镜像拉取 Jenkins 环境命令 docker pull jenkins/jenkins:lts 查看下拉取的镜像 docker images 2.通过容器编排方式构建 Jenkin ...
- AC-DCN ESXi
传统IT架构中的网络,根据业务需求部署上线以后,如果业务需求发生变动,重新修改相应网络设备(路由器.交换机.防火墙)上的配置是一件非常繁琐的事情.在互联网/移动互联网瞬息万变的业务环境下,网络的高稳定 ...
- 源码安装的应用 rpm 命令无法查询
源码安装:一大堆源码文件,需要编译后才能使用(编译需要安装编译器 :yum install gcc) rpm 安装:redhat 官网或其它开源网站编译好发布,已经编译好的安装包,使用 rpm -iv ...
- APP 自动化之手势操作appium提供API详解(四)
一.手势操作1.上下左右滑屏 swipe---滑动 java-client 4.x 是有swipe方法的,可以通过传递坐标信息就可以完成滑动androidDriver.swipe(startx, st ...
- this.$set用法
this.$set()的主要功能是解决改变数据时未驱动视图的改变的问题,也就是实际数据被改变了,但我们看到的页面并没有变化,这里主要讲this.$set()的用法,如果你遇到类似问题可以尝试下,vue ...
- requests的get请求基本使用
官方文档 https://docs.python-requests.org/zh_CN/latest/ 快速上手 https://docs.python-requests.org/zh_CN/la ...